Designing Data-Intensive Applications 書本 - Replication 筆記 (1)
今天來做 Replication 的筆記,主要是談在 Replication 中的模式,例如 Leaders and Followers 以及實現 Replication 有 Statement-based replication ,Logical replication,Physical replication 還有談談什麼是 Replication Lag 並造成了怎樣的影響。
在做 replication 不外乎就是將同樣的資料分布在多台機器上,而通常會需要做 replication 的情況有以下幾點:
- 為了讓 data 能夠地理性的更靠近 user,就如同伺服器會散落不同的國家並服務各個國家的 user 的意思,這樣的話是可以減少 network latency 的。
- 為了讓 system 能夠持續 work,就算有幾台機器無法使用,還有多的機器可以使用,也就是增進 availability。
- 如果能有多台機器來 serve read queries 的話可以增加 read throughput。
但是 replication 真正困難點就在於多台機器之間的資料如何去維持一致,當你的情境是會有持續有新寫入的資料就值得去思考這件事情。
思考這件事情就會延伸出 replication 常見的三種模式:
- Single-leader
- Multi-leader
- Leaderless
每一種模式都有其 trade-off 要去考量,以及在這些模式下又分 synchronous and asynchronous replication,以及如何去 handle failed replicas。
Leaders and Followers
要怎麼保證每次新寫入的資料能夠維持在每一個 replica 維持一致呢?常見的解決方式是採用 Leader-based replication,也叫做 active/passive or master–slave replication。
來看圖會更明白:

- User 可以對 Leader replica 進行讀寫操作,如果是寫操作則需要將寫入的結果同步到 Follower replica
- Follower replica 則是負責 serve User 的 read query,不支援 write query。
這樣的模式幾乎每一個 RDBMS 都支援這樣的模式,如 PostgreSQL,MySQL 等等。
這樣的模式就會衍生出另外一個問題,同步資料到 Follower replica 要採用 Synchronous 還是 Asynchronous?
Synchronous Versus Asynchronous Replication
來看個例子:
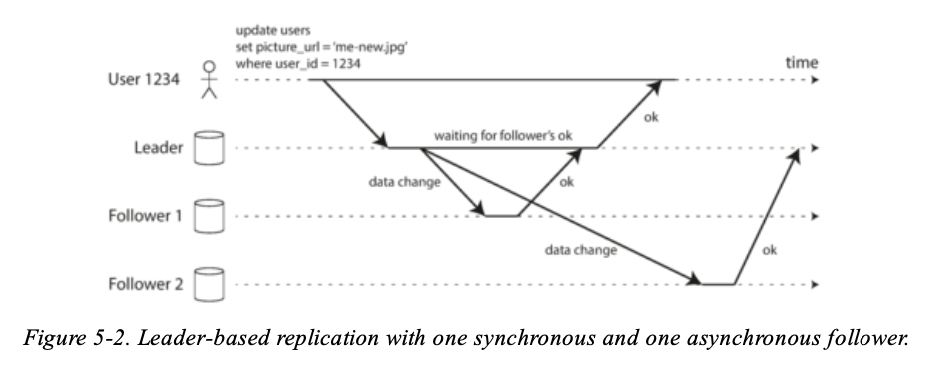
假設有兩個 Follower 一個用 Synchronous 的方式,一個用 Asynchronous 的方式,可以知道 Leader 會等 Follower 1 確實更新成功,才會 response 給 User,而 Leader 不會管 Follower 2 有沒有完成。
Synchronous 的方式優點就是保證 Leader 的資料與 Follower 1 的資料在同一時間內會一致的,如果 Leader 的機器壞了,那麼可以保證 User 存取 Follower 1 的資料也會是如同 Leader 的資料,而缺點也很明顯就是 User 要等 Leader 與 Follower 1 都寫入完成才可以拿到 response,相對的 latency 就會比較高,此外如果 Follower 1 因為 crashed 或是 network 連不到了,也代表說這次的 write 失敗了,Leader 這邊的資料也會 rollback 回去,所以即時 Leader 機器是正常的,但如果同步的 follower 壞了,也會 block all writes。
所以,常見的做法是不會將所有的 Follower 使用 Synchronous 同步資料,但至少會選擇一台是 Synchronous,而其他 Follower 則是 Asynchronous,如果 Synchronous 的那個 Follower 掛掉了,則會立即從其他 Follower 選一台變成 Synchronous,這樣的做法可以保證至少會有兩個 nodes 的資料會是 up-to-date,這樣的做法也稱為 semi-synchronous。
如果 Leader-based replication 採用全 asynchronous 的做法的話,代表 write 並不保證是 durable 的,因為有可能 Followers 資料同步失敗你並不知道,client 也可能會讀到就的資料。但是這樣的方式就可以提高 write 的速度。
Setting Up New Followers
那如果中途我想要新增 Follower 機器怎辦,要如何讓新 Follower 機器能夠追上 Leader 的資料量呢?如果只將 Leader data copy 到 new follower 是不足夠的,因為在 copy 的這段期間可能就持續有新資料進來了,所以還是無法與 Leader 同步到現有的資料量。
可以這樣做:
- 先取得 Leader 到此刻的 snapshot 資料,並且盡可能不要採用 lock on the entire database 的方式,絕大多數的 DB 都可支援該操作。
- 接著將 snapshot copy 到 new follower node。
- the follower 起來了之後與 leader 進行連接並且持續接收 data changes,而接收的時間點就是 snapshot 的時間點,其實就是要參考 leader’s replication log,在 PostgreSQL 有所謂的 log sequence number,MySQL 叫做 binlog。
- 當 follower 處理完所有 backlog of data changes since the snapshot,就稱為 caught up,當達到這個階段,就可以開始處理 sanpshot 之後收到的 data changes,最後趕上 leader。
Handling Node Outages
機器可能會有一些原因需要關閉,例如 rebooting a machine to install a kernel security patch,或者是提升硬體設備等等,這時候如果使用 replication 機制就有一些錯誤處理要做。
Follower failure: Catch-up recovery
當 Follower 因為 crashed or restarted or network problem 無法順利收到 Leader data changes log 的時候,如果 Follower 過了一段時間恢復了,要如何趕上 Leader 的進度?由於 Follower 這邊會知道 latest transaction,因此 follower 可以跟 leader 拿該 latest transaction 之後的所有 data changes 來進行處理,來慢慢趕上 Leader 的進度。
Leader failure: Failover
如果 Leader 掛掉了呢?
從剩下的 Follower 推選出一個新 leader,這樣 client 端才能持續 write,而其他 follower 需要改接新的 leader,這樣的過程稱為 failover。我們來細講整個 failover 流程:
- 首先要決定 Leader 是否真的 failed 了,可能是因為 crashes, power outages, network issues, and more。最常見的判斷方式是用 timeout,例如如果 node 在 30s 內沒有 response,就 assume 這個 node 也就是 leader 掛掉了。
- 如何選擇一個新 leader,理想情況應該是要選與舊的 leader 的資料最接近的 follower,這樣才不會有太多的 data loss,這樣的問題就需要談談 consensus problem,在後面的章節會再細講。
- 要將剩餘的 follower 設置連接新的 leader,而 client 端也要能夠送新的 write 給 new leader,稱為 Request Routing。此外,如果 old leader 回復正常,它可能會認為它還是 leader,所以這邊也要特別處理。
在實現 failover 的階段還有一些問題會出現:
- 如果是使用 asynchronous replication,在推選新 leader 過程中會遺失新的 write,而且如果新 leader 架設的期間,old leader 又回復正常了,這樣可能會導致雙 leader 的情況,並且可能會有 conflicting writes in the meantime,最好的方式最好還是 old leader 收到的 write 變成 discard 掉,但就會影響 client 的 durability expectations。
- 忽略掉 writes 可能會導致其他 storage 與 database 的資料不一致的問題產生,詳情可以看 GitHub 之前發生的問題:an out-of-date MySQL follower was promoted to leader. The database used an autoincrementing counter to assign primary keys to new rows, but because the new leader’s counter lagged behind the old leader’s, it reused some primary keys that were previously assigned by the old leader. These primary keys were also used in a Redis store, so the reuse of primary keys resulted in inconsistency。
- 如果雙 leader 的問題發生了,並且沒有去解決 write conflicts 就會導致 data lost or corrupted。
- timeout 要怎麼設置才好?如果設置太低,會導致 leader 常常被誤判是 fail 的,因為可能只是目前的流量過高,database 處理的速度變慢了,如果設置太高,又可能會太晚發現 leader 是 fail 的,導致很多 write 都失敗。這樣我覺得看來還是只能憑經驗去設置 timeout,或者是用額外條件來判斷 db 是否真的掛了。
因此基於以上的 failover 情境,許多情況自動化還是無法做得很完美,許多 operations teams 還是會選擇手動去處理 failover 的情況。
Implementation of Replication Logs
Datbase 在實現 Replication log 目前有以下幾種方式,分別來介紹一下。
Statement-based replication
最直覺的方式再將 every write request (statement),原封不動地在 follower 再執行一遍,比如說 SQL 的 INSERT,UPDATE,DELETE 等等。
但是這樣的方式有以下的缺點:
- 如果有 statement 會呼叫 nondeterministic function,例如 NOW (),來取的 current date and time or RAND () to get random number。這樣的話在每一個 replica 執行很有可能都會得到不同的值。
- 如果 statement 使用 autoincrementing column,或者是 update … WHERE
,這種的話都一定要在每個 replica 用同樣的順序去執行,不然就很容易有資料不一致的問題。 - 有些 statement 可能有 side effects,例如 triggers, stored procedure, user-defined functions,這些在每一個 replica 都容易會是 nondeterministic function。
透過一些 workround 手段是可以解決:
- the leader can replace any nondeterministic function calls with a fixed return value when the statement is logged so that the followers all get the same value. 但是還是會有許多 edge cased,很難每一個都能注意到。
- 在 MySQL version 5.1 以前是使用 Statement-based replication,但現在 Default 是採用 row-based replication if there is any nondeterminism in a statement,VoltDB uses statement-based replication, and makes it safe by requiring transactions to be deterministic。
Write-ahead log (WAL) shipping
在前面的章節有提到 log-structured storage engine 像是 SSTables and LSM-Trees 還有 B-Tree 等等都會有所謂的 log 去紀錄每一個 write。而這種 log 就叫做是 Write-ahead log,而且這種 log 是比較 low-level 的,會紀錄 which bytes were changed in which disk blocks,想是 PostgreSQL 及 Oracle 也是採用這種方式,於是 WAL 就很適合拿來做 replication,但是壞處就是 WAL 格式會與 storage engine 高耦合,每個 database version 很有都會不相容,所以 leader 跟 follower 通常不能使用不同的 version。
相對的,如果 Database 想要升級 version,就會很難做到 zero-downtime upgrade。
這種方式來做 replication,通常又會叫做是 Physical log replication。
Logical (row-based ) log replication
另外一種方式叫做 Logial log replication,這種方式不會跟 storage engine internals 綁在一起,logical log 主要是 a sequence of records describing writes to database tables at the granularity of a row:
- 如果是 inserted row,log 會有 new values of all columns
- 如果是 deleted row,log 會有足夠資訊可以判斷所這個 row 是要被刪除的,通常判斷的依據就是透過 primary key,如果沒有 primary key 就會紀錄 the old values of all columns。
- 如果是 updated row,log 就會透過 primary key 來辨認出要 update row,並且也會紀錄 the new values of all columns (or at least the new values of all columns that changed)。
由於低耦合 storage engine,所以可以做到 backward compatible,也允許 leader version 與 follower version 不同,此外 logical log format 也可以被 external applications to parse,因此做出 CDC (change data capture) 的效果,可以知道 database 做了什麼 SQL 指令,你可以攔截到相關的 record 並做處理。
Trigger-based replication
還有一種方式是當 data change (write transaction) occurs in a database system 時 register application code 來自動地執行相關的操作,這樣的情境通常是例如你只想要 replicate a subset of the data 或是 你想要 replicate from one kind of database to another 等等。
而這樣的東西其實會是 database 的功能如 triggers and stored procedures。
Trigger-base replication 通常會比 built-in replication 有更多的 overheads,而且也有其限制,但是提供的好處就是有更多的彈性去客製化。
Problems with Replication Lag
來談談 Replication Lag 所造成的問題,所謂 Replication Lag 指的就是 Leader 的資料與 Replication 之間的資料更新延遲問題。假設 Leader 是 single node,在加大 follower 的 node 情況下,Replication Lag 就會越來越明顯,尤其如果是採用 asynchronous replication,leader 不會等全部 Follower 都跟上資料,但如果 Leader 要等全部 Follower 跟上資料就會花上不少的 netwrok latency。
在有 Replication Lag 情況下,延伸出一個名詞就是 eventual consistency,只能保證最終一致性。基本上如果是要用 Replication 多少都會有 Replication Lag,但一般來說只會有幾秒鐘之類的延遲而已,這邊談的是如果 Replication Lag 是好幾分鐘的話那就要注意了。同時你要預期 client 可能會讀到 non-consistent data 那商業邏輯下要怎麼處理。
以下來看有哪些 Replication Lag 的情境:
Reading Your Own Writes
首先第一種是很常見的,如果 client 端這時候送了一個 write 會到 leader,但是 client 要讀剛剛 write 的 data 卻可能會從 Follower 來讀,這時候就有可能因為 Replication Lag 產生讀取不到資料,或是舊資料的問題。
來看流程圖會更清楚:
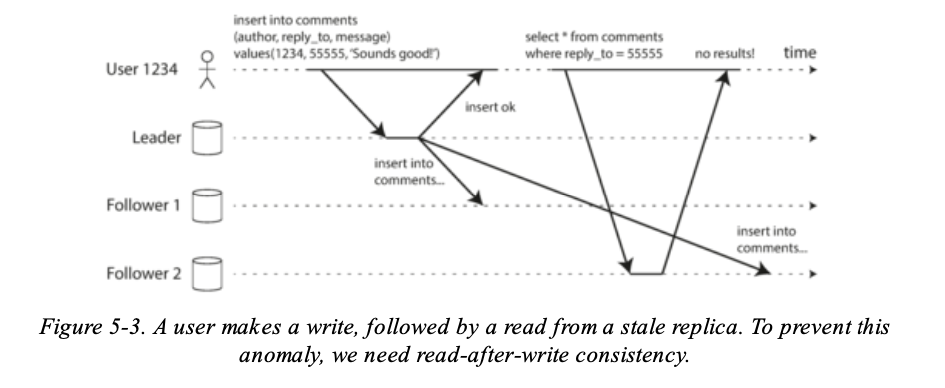
- Leader 更新完資料並通知 Follower 就 response 了
- User 讀取資料從 Follower 讀,會沒有資料。
要解決這種問題,應該要採用 read-after-write consistency 或是又叫做 read- your-writes consistency,實作方式有以下幾種:
- 當該 User 寫入資料後,應該要從 Leader 讀取資料,這樣可以保證該 User 讀得到都是最新的資料。舉個例子:如果 User 更新自己的 profile,理論上只有自己才可以更改自己的 profile,所以 user 讀自己的 profile 都從 leader 讀,user 要讀其他人的 profile 就從 follower 讀。
- 另外一種方式是可以用 update time 去紀錄上次的更新的時間與現在要讀取的時間是否有高於 Replication Lag,在這期間內都從 Leader 讀,反之則從 Follower 讀。那這樣你就要去監控 Replication Lag 時間為何。
- 還有一種做法是在 client 端記住最近一次的 write 時間,並且從 Follower 讀的時候去看資料有沒有符合 write 時間,沒有的話就換另外一個 Follower 讀。這種時間可以是 logical timestamp (something that indicates ordering of writes, such as the log sequence number)。
還有一種複雜的情境是,如果同樣的 user 會有多台機器可以存取,例如 desktop web brower and a mobile app,這時候就要考慮 cross-device read-after-write consistency,不同的 device 的資料必須要一致。此外,還有以下兩點要考慮:
- 如果透過記 user last update timestamp 的方式就會比較麻煩,因為不同 device 並不會知道其他 device 的 update timestamp,這些資料就必須要集中化處理,才能一致。
- 如果你的 replica 是橫跨多個 datacenter,還要考慮不同 device 是否會 routed to the same datacenter,例如:if the user’s desktop computer uses the home broadband connection and their mobile device uses the cellular data network, the devices’ network routes may be completely different。就必須要不同 device 都要 read the same datacenter and same leader。
Monotonic Reads
再來看這種情境:
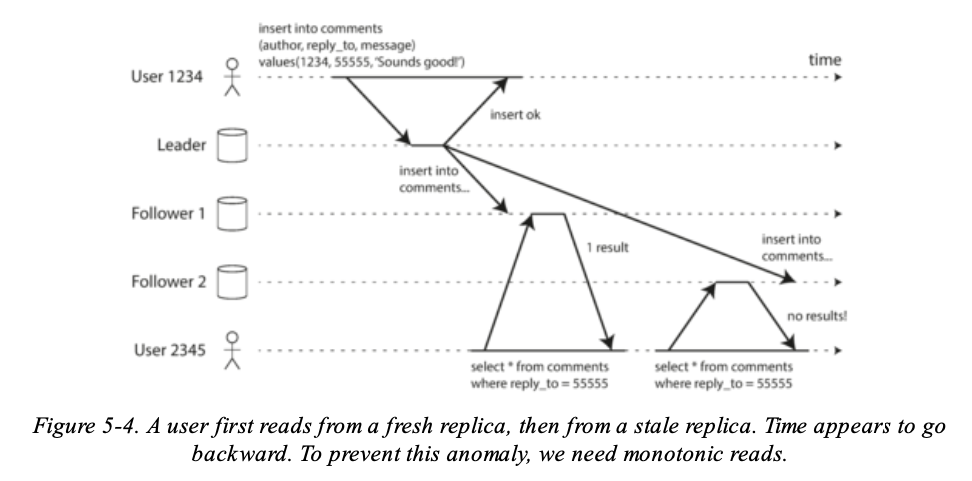
- 當 User 1234 對 Leader 寫入資料後,Leader 不等 follower 同步好就 response。
- User 2345 讀取的時候從 Follower 1 讀了之後,又從 Follower 2 讀了資料,可能會造成第一次 Follower 有拿到資料第二次則沒有,因為兩個 Follower 的更新速度不一致導致的。
因此要介紹 Monotonic reads 的概念,可以保證以上的情況不會發生,但是只能保證最後一致性。什麼意思呢?也就是你在讀資料的時候只會從同一個 Follower 讀資料,而不會跳來跳去,就算你有一連串的 read query 也都會在同一個 Follower,避免前面所說每個 read 都從不同 Follower 讀的問題。
而要從哪個 replica 讀?可以透過 a hash of the user ID,而固定每一個 User 只能讀哪個 replica,而不是隨機讀取,然而這樣的風險就在於如果 replica 掛了,這個 User 就需要 routed to another replica。
Consistent Prefix Reads
再來看這種情境:
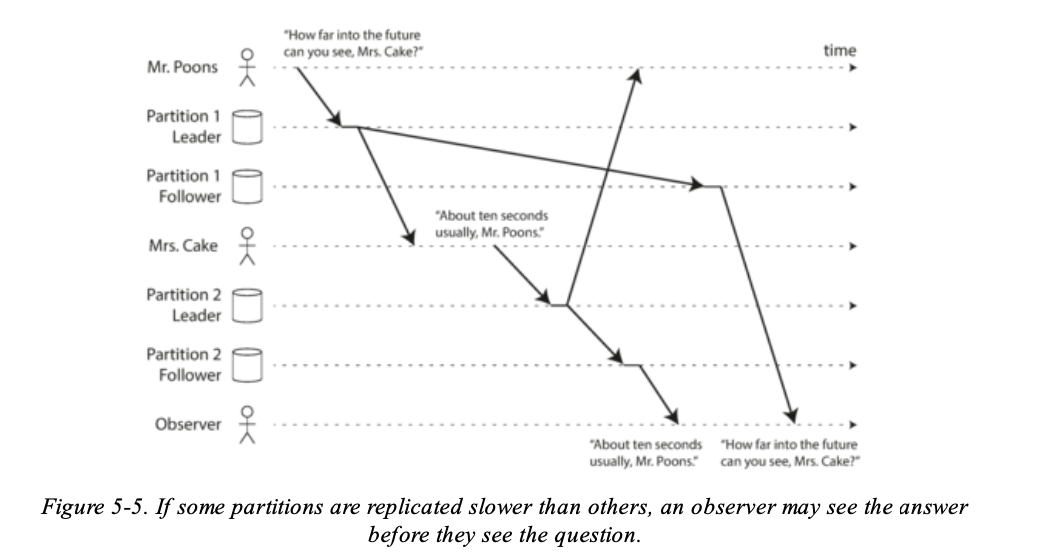
- Mr. Poons 與 Mrs. Cake 在聊天,這兩個人的 write 各自給不同的 leader,同時有其他人在讀取的時候與這兩個人的聊天順序不一樣,也就是說讀取的 Follower 不同就有可能會有句子上下對調的問題發生。
要解決這種方式,要採用 consistent prefix reads 概念:如果有一連串的 writes 要發生了,並且這個 order 很重要,那麼其他人 read 的時候也要跟著 write 這個 order 去讀,才不會出現上面的狀況。
通常這種問題最常發生在 partitioned (sharded) databases,在多個 distributed databases, different partitions operate independently, so there is no global ordering of writes:when a user reads from the database, they may see some parts of the database in an older state and some in a newer state。
其中一種解決辦法就是這些 write 都到 same partition,然而這種方式會非常的不有效率,有其他方式可以解決,在後面的章節會再提。
Solutions for Replication Lag
前面講了這些 Replication Lag 所造成的問題,因此如果這些問題讓 User 有非常不好的體驗的話,在架構設計上最好是採用 read-after-write,給 User 的假象是 synchronous replication,實質背後是 asynchronous replication。
所以基本上,如果你的流量沒有到一定程度,其實採用 single-node database 還是最佳解,起碼你不用解決很多 replication 的資料不一致問題,single node database 資料不一致可以透過 db 所提供的 transcation 來幫我們解決,如果 application code 要涉及 replication 就會變得很複雜。
總結
今天主要是著重介紹 Single Leader 與多個 Follower 的架構,以及同步與非同步更新資料的所帶來的 replication log 問題。最後提供 backend 版主對於 logical log replicaton V.S physical log replication (block-level replication) 的優缺點。