Designing Data-Intensive Applications 書本 - Modes of Dataflow 筆記

今天來做 Modes of Dataflow 的筆記,重點圍繞著何謂 forward and backward compatibility,並且運用在 database,REST,RPC,Message-Passing 如何去克服向上相容及向下相容。
Forward and Backward compatibility
Forward Compatibility
指的是舊版本的軟硬體可以使用新版本的軟硬體的資料的意思
Backward Compatibility
指的是新版本的軟硬體可以相容舊版本的軟硬體的資料的意思
Dataflow of Databases
在 database 的情境下,當新的需求出來之後,可能會需要有添加新欄位的情況,那可能就要特別注意當 old version application 存許到新 schema 的時候要注意不要覆蓋掉新欄位的值。
來看個例子:
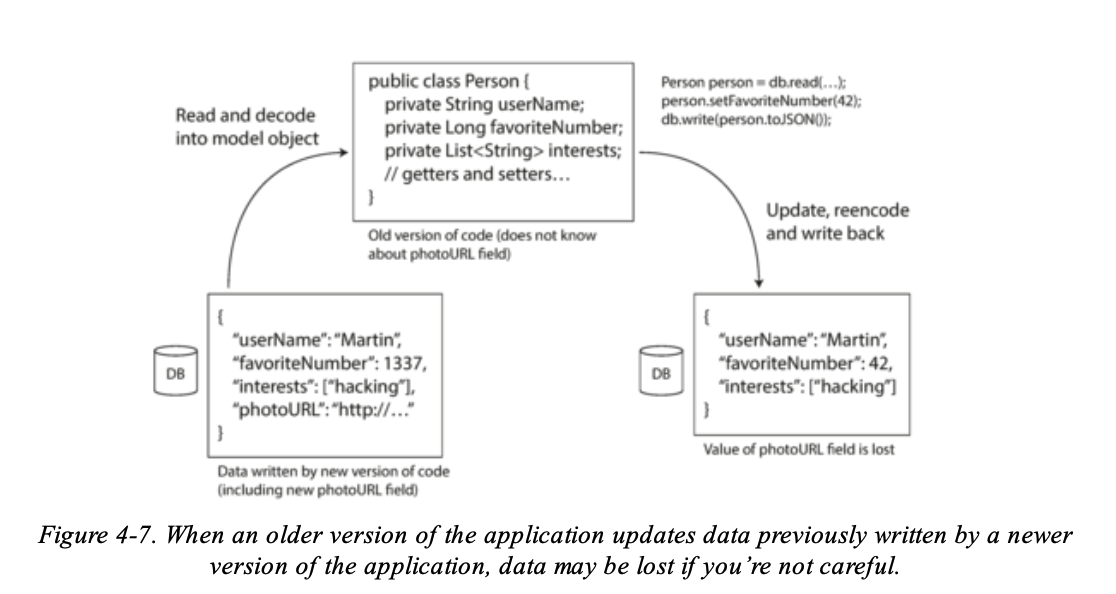
- db table schema 新增了 photoURL 欄位,old version application 讀 record 的時候會將其 decode 到該語言的 object,但是它不知道有新增欄位,所以 code 還是舊的無法 decode new column to object,這時候如果 old version application update record to database,如果 update 的方式是對每一個 column 進行 update,而 old version application 的 ORM 又沒有特別處理的話,很有可能會將新 column 的值設為 default value,以上圖的情境很有可能就會是空字串。
- 另外一種情況,也很容易發生的是 json column,現在的 RDBMS 也有支援 column 是 json or jsonb type。由於 json 欄位會是 flexible schema,所以 old version application 會很難知道有什麼新的 field 出現,而且 ORM 通常更新 json 欄位也有可能會是整個 json 欄位進行更新。所以最好的解決方式還是使用該 RDBMS 的 raw SQL 語法去針對某一個 json field 進行 update 來避免這樣的問題出現。此外,也不建議你所使用的程式語言去將每一個 json field 變成一個 object,而是採用 map 的方式去 decode,因為使用 object 的方式就一定要每一個 field 定義出來,那就一定會有 miss new field 的時候。
解決方法
- 應該要理解你所使用 ORM 的 update 方式如何,就我所知 Java 常用的 JPA 框架就很常用一個 class object 進行 save 來實施 insert and update,就很有可能會遇到剛才所說的問題。以 Golang 我常用的 ORM,比如說是 go-pg,都是需要針對某欄位進行 update,所以比較不容易發生這種問題。
Dataflow Through Services: REST and RPC
在傳輸資料的方式現在最常見的應該就是 REST and RPC,那 API 這種東西也是最容易會遇到新舊版本的問題。
REST
以 REST API 而言,最常見的就是會採用版本管理來實施在 URL 上,例如 example.com/v1/api,example.com/v2/api 等等,這樣的方式就是每個版本都會有各自的 server 去處理,如果不這樣做,那你要處理向下相容的話就不能在新版本的 API 去改變舊版本的 payload,例如 request body 等等,你只能選擇新增新的 field,讓新版本的 client 端去多帶這些新的 field,個人覺得是看商業情境而定該不該汰舊換新,讓 client 端都升級成舊版本之類的方式,或是採用 URL 版本管理去各自 server 新舊版本的 client 端。
RPC
RPC 的方式其實從以前就提出了,其目的是想達到 call remote machine function。但是它會有以下的缺點:
- A local function call is predictable and either succeeds or fails, depending only on parameters that are under your control. A network request is unpredictable: the request or response may be lost due to a network problem, or the remote machine may be slow or unavailable, and such problems are entirely outside of your control. Network problems are common, so you have to anticipate them, for example by retrying a failed request.
- A local function call either returns a result, or throws an exception, or never returns (because it goes into an infinite loop or the process crashes). A network request has another possible outcome: it may return without a result, due to a timeout. In that case, you simply don’t know what happened: if you don’t get a response from the remote service, you have no way of knowing whether the request got through or not.
- If you retry a failed network request, it could happen that the requests are actually getting through, and only the responses are getting lost. In that case, retrying will cause the action to be performed multiple times, unless you build a mechanism for deduplication (idempotence) into the protocol. Local function calls don’t have this problem.
- Every time you call a local function, it normally takes about the same time to execute. A network request is much slower than a function call, and its latency is also wildly variable: at good times it may complete in less than a millisecond, but when the network is congested or the remote service is overloaded it may take many seconds to do exactly the same thing.
- When you call a local function, you can efficiently pass it references (pointers) to objects in local memory. When you make a network request, all those parameters need to be encoded into a sequence of bytes that can be sent over the network. That’s okay if the parameters are primitives like numbers or strings, but quickly becomes problematic with larger objects.
- The client and the service may be implemented in different programming languages, so the RPC framework must translate datatypes from one language into another. This can end up ugly, since not all languages have the same types—recall JavaScript’s problems with numbers greater than 253. This problem doesn’t exist in a single process written in a single language.
但是儘管如此,Google 開發的 gRPC 改了不少舊有 RPC 的方式,其主要原因是採用 protobuf 的格式去定義傳輸資料,同時大幅度地降低傳輸資料的大小,然後在向下相容情境下,就算舊版本的 client 端送到新版本的 server 端,client 端由於 gRPC 的方式 codegen 出來的欄位都會是舊 version 的,而新版本的 server 端只要不刪除舊版本的欄位,還是一樣可以讀到。
另外建議可以看一下這篇文章:https://medium.com/@leon740727 / 設計思考 - protocol-buffers-3 - 為什麼 - 49219fc87bb7
講解了為何 protobuf v2 => protobuf v3 之間的差別,以及為何要這樣做。
但是我又翻到 protobuf v3 在 v3.15.0 又要支援 optional 的方式了,相關說明在這邊:https://github.com/protocolbuffers/protobuf/blob/master/docs/field_presence.md 以及 issue 討論探討:https://github.com/protocolbuffers/protobuf/issues/359
Message-Passing Dataflow
message-passing 的傳輸方式比較特別,主要是可以採用非同步的方式,sender 方只著重送出 message,基本上就沒有 sender 的事情了,而是 receiver 方要負責收到 message 後再去做相對應的邏輯處理即可。
所以我自己覺得在 receiver 方向下相容也是很容易的。
Distributed actor frameworks
這邊提一下 actor model 的模式,The actor model is a programming model for concurrency in a single process. Rather than dealing directly with threads (and the associated problems of race conditions, locking, and deadlock), logic is encapsulated in actors.
In distributed actor frameworks, this programming model is used to scale an application across multiple nodes. The same message-passing mechanism is used, no matter whether the sender and recipient are on the same node or different nodes. If they are on different nodes, the message is transparently encoded into a byte sequence, sent over the network, and decoded on the other side.
可以看這張圖會更理解:
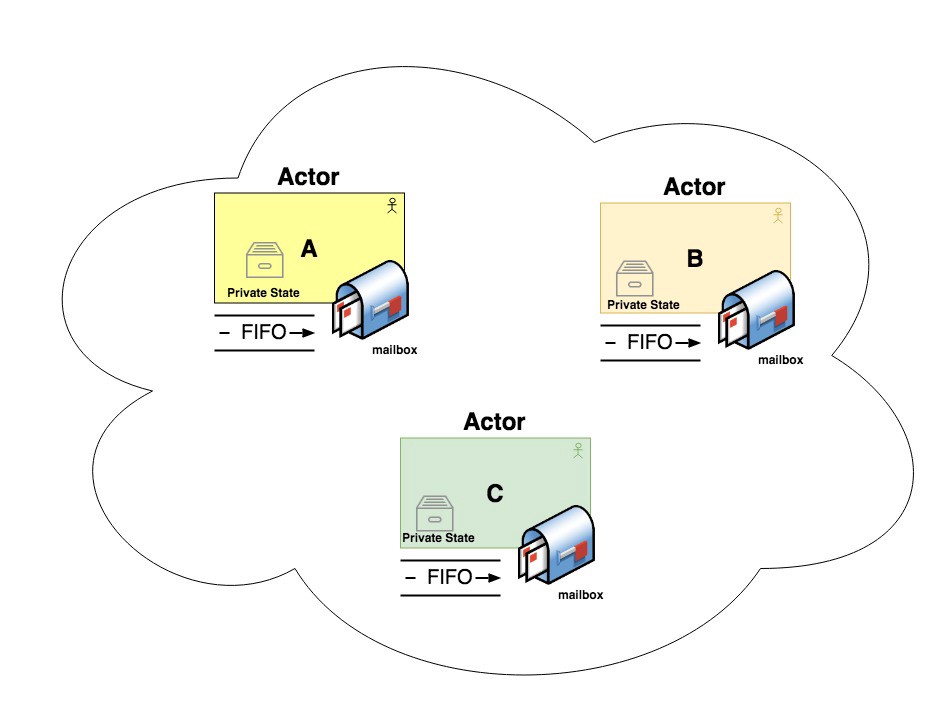
Actor Model vs CSP
其實 Golang 的 CSP 與 Actor Model 是滿相近的設計,只是差別在於 channel 是共用的,而不是像 Actor 有各自的 mailbox。推薦看這篇文章:https://texlution.com/post/elixir-concepts-for-golang-developers/#processes
總結
這篇文章主要是介紹常見傳輸方式在遇到 forward/backward compatibility 的差別及解決辦法,並且看了一下 protobuf v2 => v3 之間的差異以及為何這樣設計還滿有趣的。