Designing Data-Intensive Applications 書本 - Replication 筆記 (2)
今天來講講 Multi-Leader Replication 有哪些優缺點,以及如何處理 Write Conflicts。在前篇文章所提的 Leader-based replication,有個主要的缺點就是,如果這個 leader 掛了,所有的 writes 都無法進行了。因此這時候可以採用 multi-leader replication 的架構來解決這個問題,而每一個 leader 底下都會有各自的 follower。
Use Cases For Multi-Leader Replication
通常會使用 multi-leader 的情況下,是因為有多個 datacenter,如果不是的話多增加一個 leader 其實只是增加系統複雜度並沒有什麼太多的幫助。
Multi-datacenter operation
所以可以想成每一個 datacenter 裡面有各自的 Leader-based replication。
來看看這張圖會更明白:
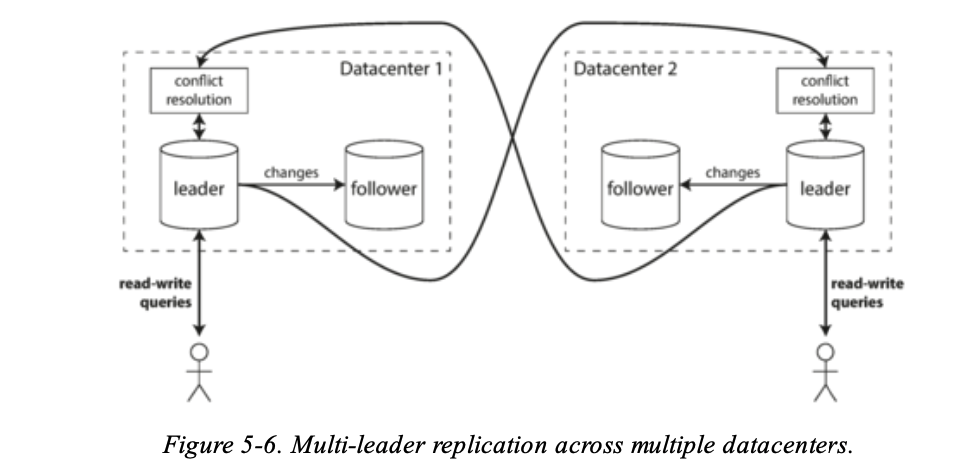
每個 user 會對屬於自己的 datacenter 的 leader 進行 write 或是 read,而不同的 datacenter 的 leader 就需要解決 conflict 的問題。
performance
- 在 performance 上是可以提高的,因為每個 user 可以連上離自己較近的 datacenter,write 速度也會提高,少了一些 latency。
- 可以在 local datacenter 進行 replication 外也可以對其他 datacenter 進行非同步的 replication,這樣只要 User 所對到的 datacenter 有更新成功就可以了,不需要等其他 datacenter 更新完資料,提高 performance。
Tolerance of datacenter outages
在 single-leader 的情境下,如果這個 leader 掛了就需要等待 promote new leader 的時間,但如果是 multi-leader 的話,如果這個 datacenter 的 leader 掛了,User 可以連到其他 datacenter 的 leader 就可以做持續寫入的操作。
Tolerance of network problems
- A single- leader configuration is very sensitive to problems in this inter-datacenter link, because writes are made synchronously over this link
- A multi- leader configuration with asynchronous replication can usually tolerate network problems better: a temporary network interruption does not prevent writes being processed.
Clients with offline operation
還有一種情境很適合用 multi-leader,如果有一個月曆 APP 在你的手機上,如果手機斷網了,你對月曆 APP 的寫入還是會存在 local 端,而當連接網路後,才會把 local 的改動 sync 到 remote server。
像這樣的情境,就像是 local leader and remote leader 的雙 leader 架構。從這樣去想,就可以設計出:each device is a “datacenter,” and the network connection between them is extremely unreliable. As the rich history of broken calendar sync implementations demonstrates, multi-leader replication is a tricky thing to get right。There are tools that aim to make this kind of multi-leader configuration easier. For example, CouchDB is designed for this mode of operation。
Collaborative editing
還有一種情境是像那種多人協作文件的服務,其實跟前面的月曆的意思很像,反正不管怎樣,如果你想要多人協作快速,通常就不想要使用 locking,但是就要特別 write conflict 的問題這也跟 multi-leader 所要解決的事情是差不多,後面就來談談怎麼解決這件事情。
Handling Write Conflicts
Multi-leader 最大的問題就是 write conflicts 要解決,來看個例子:
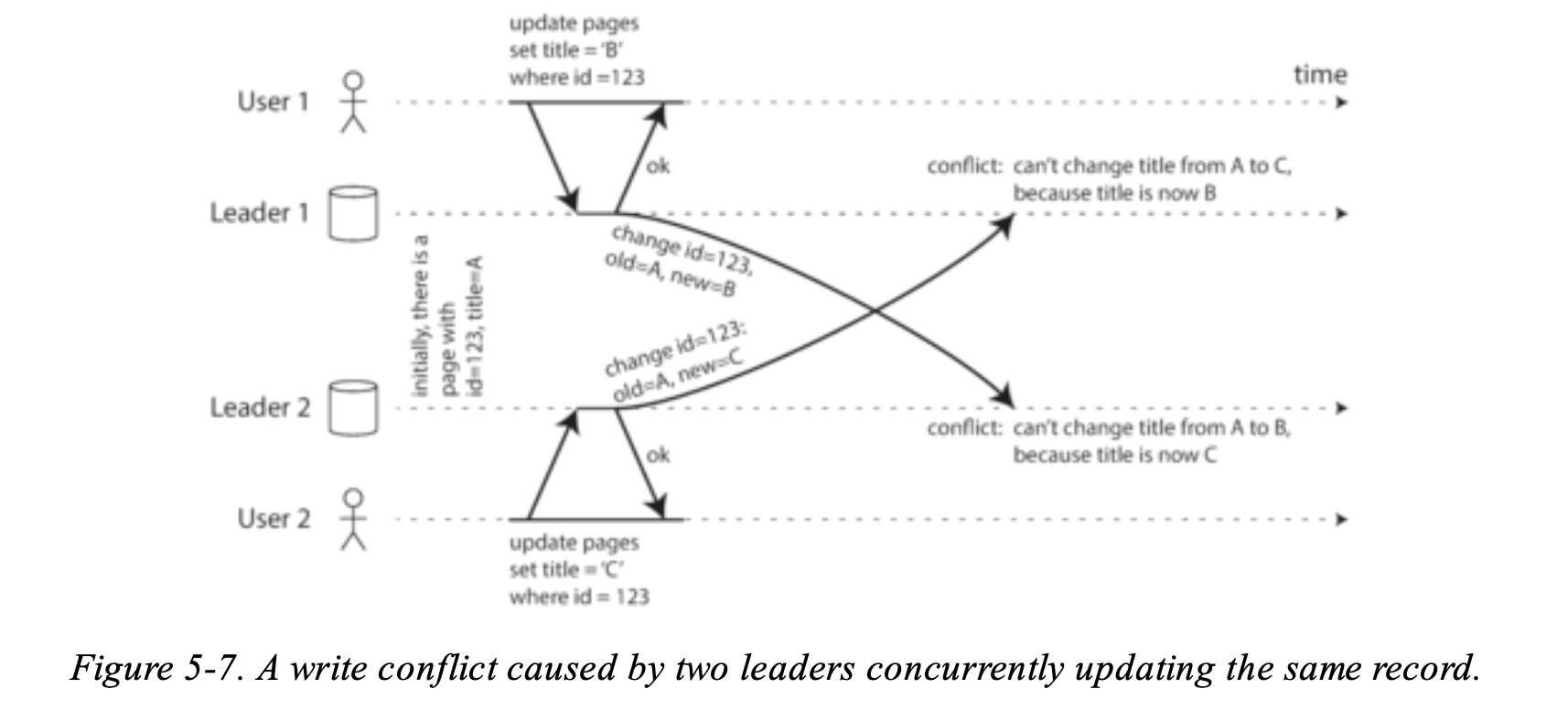
如果兩個 User 要同時對 Wiki 修改資料,而且這兩個 User 都是給不同的 leader 處理。
Synchronous versus asynchronous conflict detection
要解決這個問題首先需要想辦法偵測 conflict,在 single-leader 的架構下 the second write 會被 block 並且等待第一個 write 成功才會進入第二個 write,這時如果有第二個 write 有 conflict 可能就會阻擋寫入並且 rollback 之類的。
但是如果是 multi-leader 的話,兩個 write 都是成功的話,the conflict is only detected asynchronously at some later point in time。這樣解決 conflict 就太遲了,但是如果你讓所有 conflict 都是 synchronous 去偵測的話,每一個 write 都要被同步到 replicas 成功後再告訴 User,但是這樣就失去了 multi-leader 的好處,沒辦法讓每一個 replica 個別接受 write。那就不如使用 single-leader 的架構。
Conflict avoidance
最簡單的方式是 avoid conflict:如果 application 可以確保每一個 write 都是 for a particular record go through the same leader, then conflicts cannot occur。舉個例子:如果每個 user 可以 edit 他們自己的 data,那可以確保每一位 user always routed to the same datacenter and use the leader in that datacenter for reading and writing。不同的 User 有自己的 datacenter,對於 User 而言就像是 single-leader 的架構一樣。
但是會遇到的問題就是 datacenter 的 leader 掛了,需要 reroute traffic to another datacenter, or perhaps because a user has moved to a different location and is now closer to a different datacenter,這樣的話 Conflict avoidance 就很難做到。
Converging toward a consistent state
以前面的例子,其實重點在於每一個 replicas 所收到的一連串的 write 其最終的 final value 一樣要是一致的,所以需要去 achieving convergent conflict resolution:
-
可以給每一個 Write 一個 unique ID,比如說 timestamp,a long random number,a UUID,或是 hash of the key and value,從這些 write 去選擇較 highest ID as the winner 來去解決 write conflict 問題。
如果是使用 timestamp,這種方式叫做 last write wins (LWW)。但是會有潛在的問題,之後會再來談。
-
給每一個 replica 一個 unique ID,and let writes that originated at a higher- numbered replica always take precedence over writes that originated at a lower-numbered replica。
-
或是將這些 write merge 起來,以上面的圖就像是 B/C。
-
將遇到的 write conflict 記錄起來並且透過 application code 去解決,一種方式是直接跟 User,讓 User 去決定 conflict 如何解。
Custom conflict resolution logic
而通常有些 db 會有其客製化的解決 conflict 方法,例如 Bucardo,可以讓你寫一個 write script 去處理 conflict 的情況,而 CouchDB 可以讓你遇到 conflict 的時候這些 write 存起來,並且當下次這些有 conflict data 被讀到後這些 data 讓 application code 去解決,就可以在 UI 做點手腳,讓 User 有選擇性地去解決 conflict。
What is a conflict?
但其實有很多情況你很難決定 write 的優先順序怎麼來的,例如說如果今天兩個 User 要訂房,每次訂房都有去檢查該房間有沒有空位,這兩個 User 會有可能同時檢查通過,並都送出的訂房的請求,這個之後我們會再談談,最基本的話會用 transaction 來做到,但在 replicated system 就會用到一些 2PC 的機制。
Multi-Leader Replication Topologies
最後來談談 replication topology:
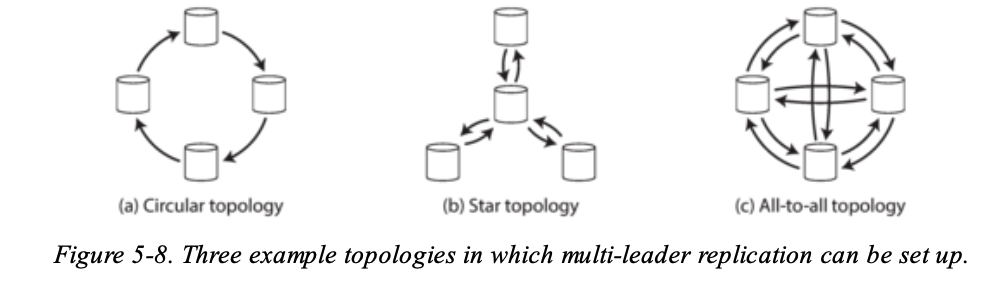
在 multi-leader 的架構下,可以採用 a, b 的設計,write 要一個一個傳遞給 leader 最後才傳給所有 replica。為了避免 infinite replication loops,每一個 node 會被給予 a unique identifier 在 replication log 裡面,當有 node 收到的 data change 是被 tagged with its own identifier, that data change is ignored, because the node knows that it has already been processed。
但是這兩種方式最大的缺點就是如果一個 node fail 了,it can interrupt the flow of replication messages between other nodes, causing them to be unable to communicate until the node is fixed。
而 All-to-all topology 會有以下的問題:
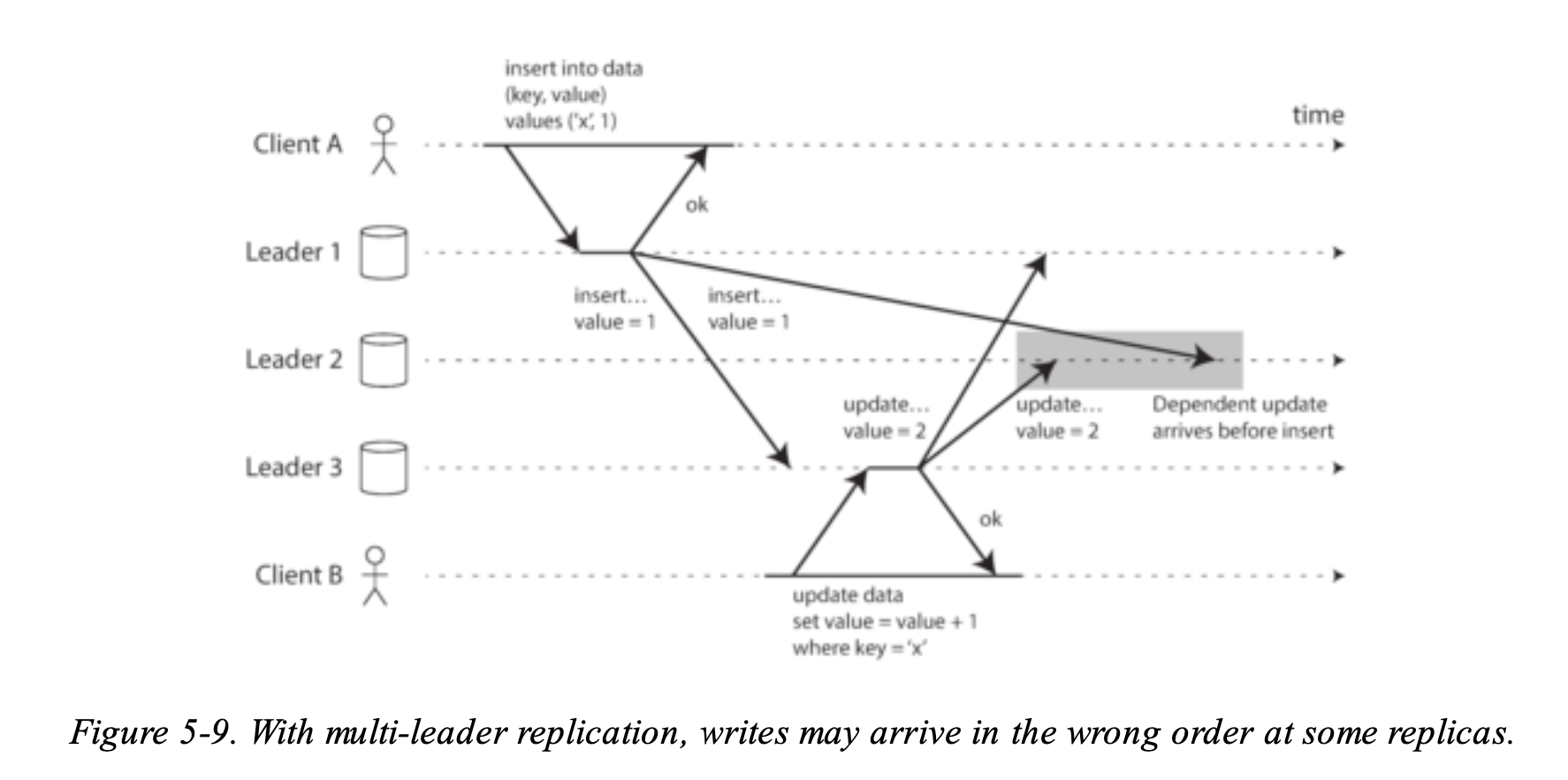
- client A inserts a row into a table on leader 1, and client B updates that row on leader 3.
- However, leader 2 may receive the writes in a different order: it may first receive the update (which, from its point of view, is an update to a row that does not exist in the database) and only later receive the corresponding insert (which should have preceded the update).
這樣的問題就像是前面說的 Consistent Prefix Reads,為了解這個問題,可以使用稱為 version vectors 的技巧,這個之後會在講。
總結
今天主要是介紹 Multi-Leader 架構下會遇到哪些問題並且如何去解決,但是不管什麼解決方法都一定會有其優缺點,只能看 trade-off 去衡量囉。