淺談 PostgreSQL 與 MySQL 的差異

今天來筆記一下 MySQL 與 PostgreSQL 的差異,這篇文章是我很久以前就想講的主題,另外多年前 Uber 也出了這篇 Why Uber Engineering Switched from Postgres to MySQL,我會根據這篇文章提到的內容來探討一下,MySQL 與 PostgreSQL 在怎樣的情境下的各自優缺點為何。
以下文章內容與圖片參考於 MySQL 跟 PostgreSQL 官方網站及其他大神的文章,連結會放在最後 Ref 上。另外關於 Postgres 的部分就沒寫得那麼詳細了,只會著重在重要的點,對於 PG internal 這部分很推薦看 https://www.interdb.jp/pg/ 講得非常詳細。
最後,在介紹之前先來看看 MySQL 與 PostgreSQL 的標語:
MySQL:The world’s most popular open source database
PostgreSQL:The world’s most advanced open source database
從這可以知道兩邊多少有互相苗頭的意味!?挺有趣的。
History
我們從歷史開始來看 MySQL 與 PostgreSQL 的崛起。
MySQL
(圖片來源)
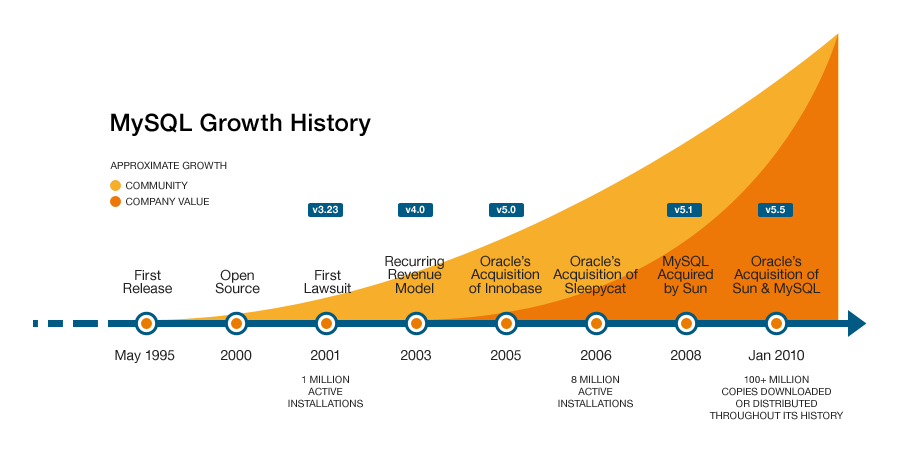
MySQL 由瑞典的 MySQL AB 公司所開發,於 2008 年被 Sun 收購。接著 2009 年被 Oracle 收購讓 MySQL 成為旗下產品。MySQL 的版權就掌握在 Oracle 手中,並且是有權利將 MySQL 閉源的。因此 MySQL 的作者 fork 出 MariaDB 出來。而維基百科於 2013 年正式宣布將從 MySQL 遷移到 MariaDB 資料庫。
其他版本的時間線:
- MySQL 5.6 (2013-02-05)
- MySQL 5.7 (2015-10-21)
- MySQL 8.0 (2018-04-19)
PostgreSQL
(圖片來源)
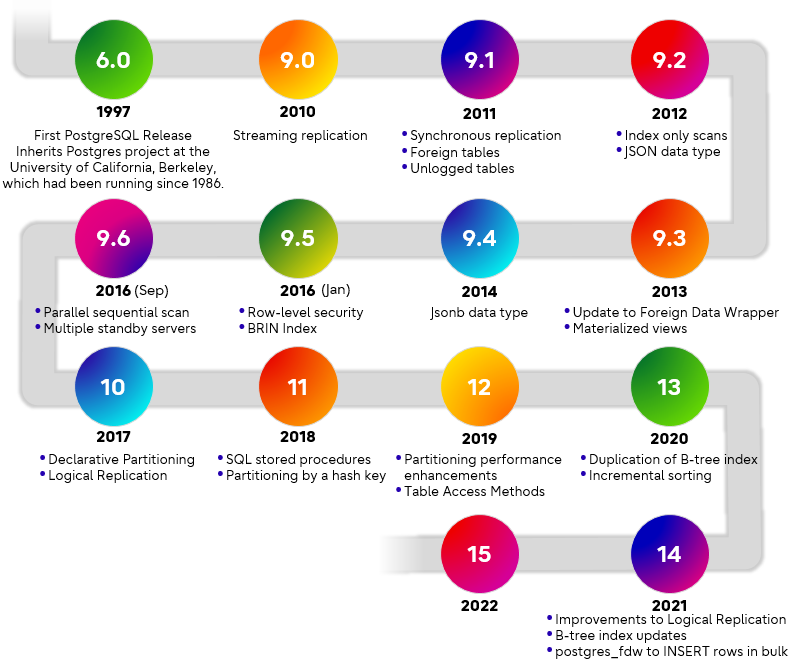
PostgreSQL 最初是美國加州伯克萊大學資訊科學系所開發出來的,後來就直接開源了。從 9.0 ~ 9.6 主要都在做資料庫基本功能的加強。之後就開始每年推出一個主版本,所以版本跳動很快,跟 MySQL 的版本發佈差很多。
以現在的時間來看應該是以 PostgreSQL 16 對標 MySQL 8.x。
License
講完了歷史來談談兩邊的 License 要注意的點。
(圖片來源)
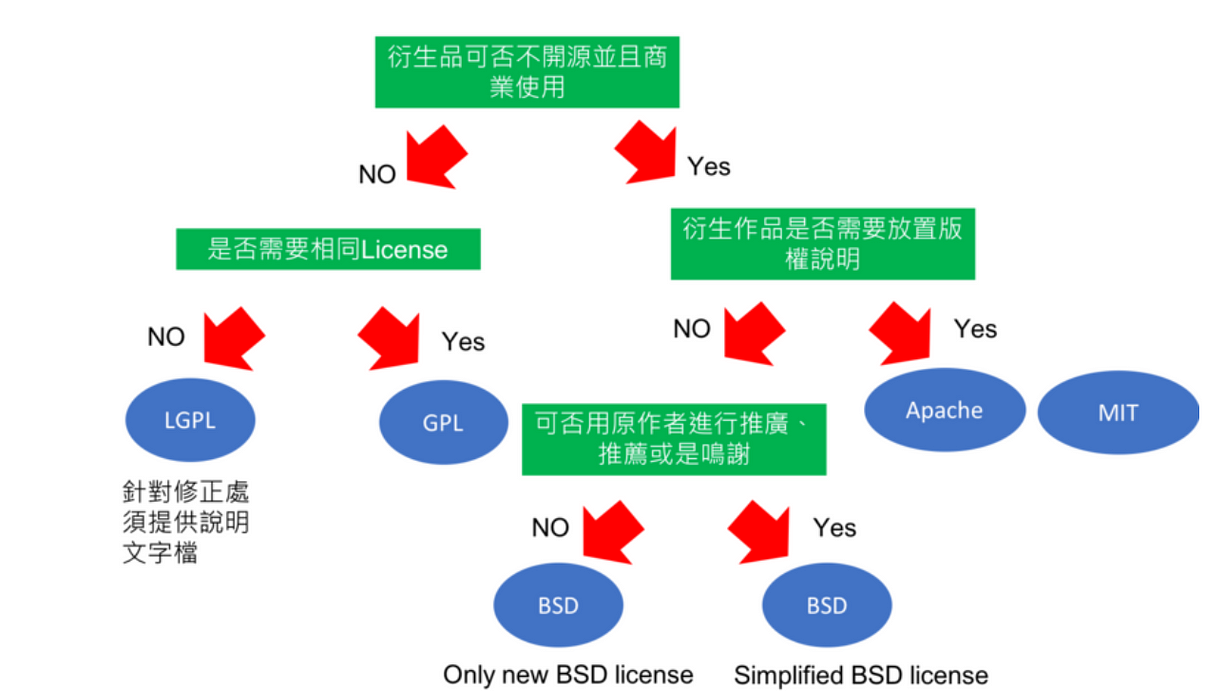
我們常見的就是 GPL、Apache、MIT、BSD 這些。從上圖可以知道最主要差別在於衍生品是否中強制開源以及允不允許商業使用。
MySQL
MySQL 從一開始都是屬於 GPL License,因此衍生品是需要開源的。所以通常想要二次開發的第三方公司並作為商業使用就不會選擇 GPL 的。另外 MySQL 本身的版權是屬於作者的,但是後來版權賣給所屬的公司,之後一路被收購到最後被 Oracle 擁有 MySQL 版權。
因此 Oracle 是有權利更改 MySQL 的 License,假設 Oracle 想要閉源 MySQL,可以等到下一次的 MySQL 主版本在用新的授權。是沒辦法在當前版本去改授權的。
另外如果有其他公司想要二次改造 MySQL 但又不想要因為 GPL 限制而開源,就需要跟 Oracle 買商業授權,這樣就可以閉源了。
從 MySQL AB,到 Sun,到最後被 Oracle 收購,那 Oracle 自然就有 MySQL 的版權,也就是 MySQL 的主人。
看下 Oracle 官網上關於商業授權的描述
Q3:身為商業 OEM、ISV 或 VAR,我應該何時購買 MySQL 軟體的商業授權?
答:OEM、ISV 和 VAR 想要在其商業應用程式中嵌入 MySQL 軟體的商業二進位文件,但又不想受 GPL 約束,並且不想發布其專有應用程式的源代碼,則應購買商業許可證來自甲骨文。購買商業許可證意味著 GPL 不適用,商業許可證包括發行商通常在商業發行協議中找到的保證。
當然啦,如果只是使用 MySQL 的服務完全可以用社區免費版的,不會收費。Oracle 也有因此推出像是企業版提供一些特殊功能還有技術支援之類的。
PostgreSQL
PostgreSQL 的授權是自創的,但是與 BSD 跟 MIT 類似,基本上使用者想要拿 PostgreSQL 的程式碼做任何二次開發並商業使用開不開源都可以。
而 PostgreSQL 本身也是屬於社區的,背後是由 PostgreSQL 全球開發小組所組成的,核心成員來自全球各地的獨立開發者或是不同公司的成員。可以在這邊查到相關成員名單。
Ranking
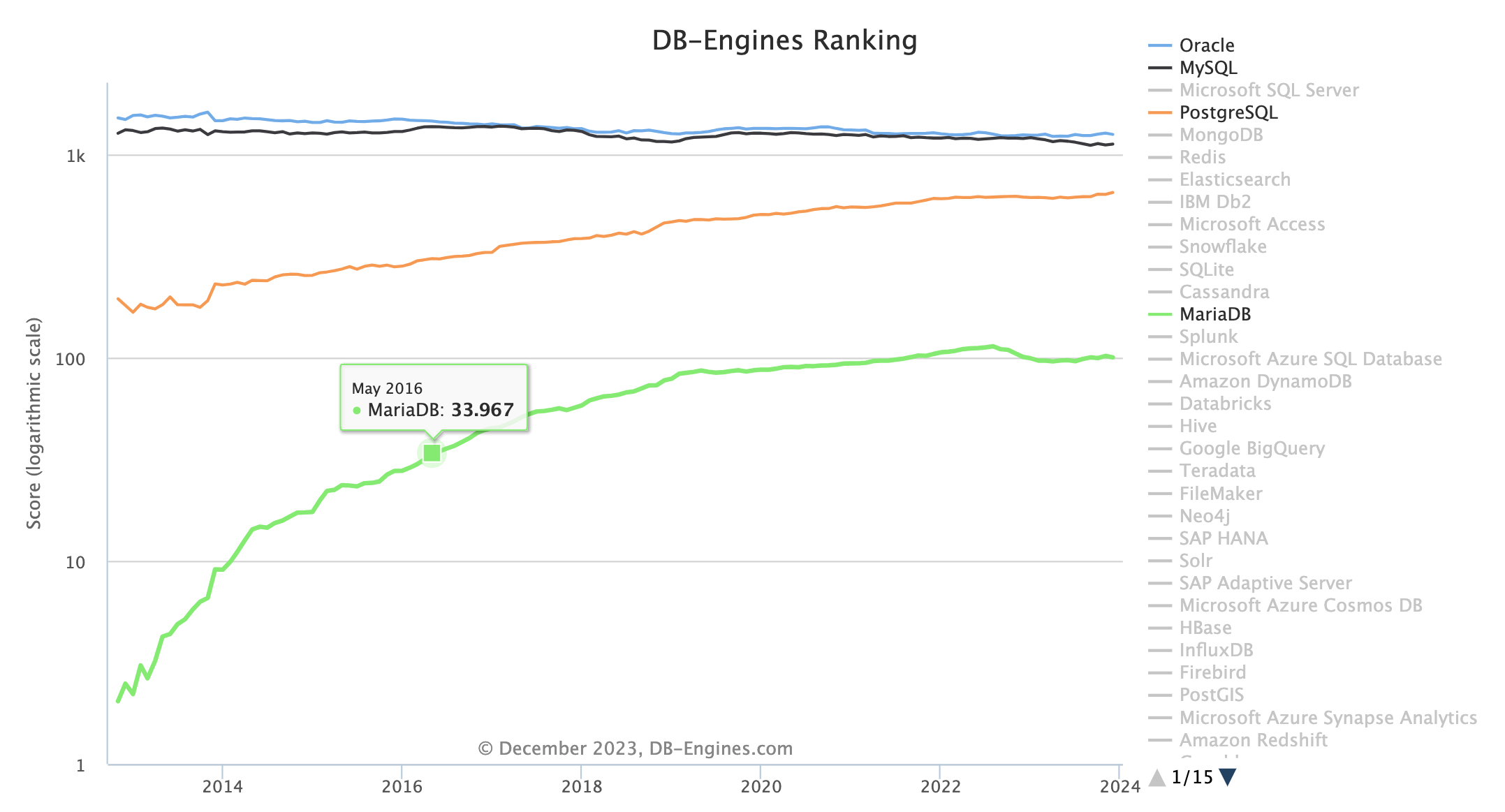
這個趨勢圖是從知名的 db engine 來的,其分數算法來自於
- Google、Bing 和 Yandex 搜尋引擎查詢中的結果數量
- Google trend 中的搜尋頻率
- Stack Overflow 和 DBA Stack Exchange 上的相關問題數量和感興趣用戶數量
- Indeed and Simply Hired 中的工作職位數量
- LinkedIn and Upwork 中的提及數量
- Twitter 中推文的數量
可以看到 Oracle 跟 MySQL 早期就開始很受歡迎,PostgreSQL 從 2014 開始很穩定的上升,並逐漸追上 MySQL。
Architecture
接著以 overview 的角度來介紹 MySQL 與 PostgreSQL 的架構。
MySQL
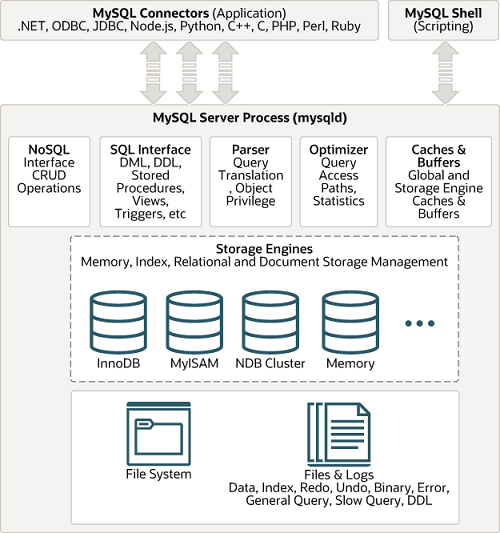
Connection / Thread Handling
當 Client 端對 Server 端發出連線請求時,會由 Server 端這邊產生一個 thread 來負責處理該連線。因此是 one-thread-per-connection。但不管是 thread 還是 process 還是會需要有 pool 的概念才能有效利用資源而不是一眛的堆高 max connections。因此 Oracle 有推出了 ThreadPool 方案,透過 Plugin 方式添加到 Enterprise 版本。
Query Cache
這邊特別提一下 Query Cache 的概念。
當使用者使用 select 查詢後,MySQL Server 會優先查看有沒有對應的 cache 存在,有的話會跳過解析、最佳化及執行的過程,直接顯示 cache 的資料。query cache 是以 key (sql statement):value (result) 方式存。
但其實這個 query cache 用處並不大,因為很容易 cache miss:
- 只要對應的表有更新,其 cache 就需要被清空
- select query 要一模一樣才能 cache hit。
因此在 MySQL 以下的版本逐步淘汰 query cache。
- 5.6:disable query_cache by default
- 5.7.20: depreciated query_cache
- 8.0: retire query_cache
Storage Engine
屬於可插拔式的 plugin storage engine,也因此 MySQL 早期是提供 MyISAM,後來用 plugin 的方式誕生了 InnoDB。這邊主要介紹這兩個 engine 的差別,其他就比較少會用到了
-
MyISAM: 一開始的 default engine
- non-transactional
- table lock/scan
- 在執行查詢語句前,會自動給涉及的所有表加讀鎖,在執行插入、刪除、修改操作前,會自動給涉及的表加寫鎖。
-
InnoDB: 從 MySQL 5.5 開始為 default engine
- transactional
- row lock
File Format
1 | mysql> SHOW VARIABLES LIKE 'datadir'; |
當建立 database 會在 /var/lib/mysql/ 目錄里面創建一個以 database 為名的目錄,然後保存表結構和表數據的文件都會存放在這個目錄里。
架設這邊有一個 my_test 的 database,該 database 里有一張名為 t_order 數據庫表。
1 | [root@xiaolin ~]#ls /var/lib/mysql/my_test |
-
db.opt
- 用來存儲當前數據庫的默認字符集和字符校驗規則。
-
character set (utf8 vs utf8mb4)
- 早期給的 utf8 只支援 3 byte,為了因應後續字元不夠用問題則又誕生了 utf8mb4,所以應該都是要用後者比較保險。
-
8.0 拿掉了
-
orders.frm
-
t_order 的表結構會保存在這個檔案。在 MySQL 中建立一張表都會生成一個.frm 檔案,該檔案是用來保存每個表的元數據資訊的,主要包含表結構定義。
-
8.0 拿掉了
-
-
orders.ibd
- t_order 的表數據會保存在這個檔案。表數據可以存在共享表空間檔案(檔案名:ibdata1)里,也可以存放在獨占表空間檔案(檔案名:表名字.ibd)。這個行為是由參數 innodb_file_per_table 控制的,若設置了參數 innodb_file_per_table 為 1,則會將存儲的數據、索引等資訊單獨儲存在一個獨占表空間,從 MySQL 5.6.6 版本開始,默認值為 1 ,因此 MySQL 中每一張表的數據都存放在一個獨立的 .ibd 文件。
Table Space
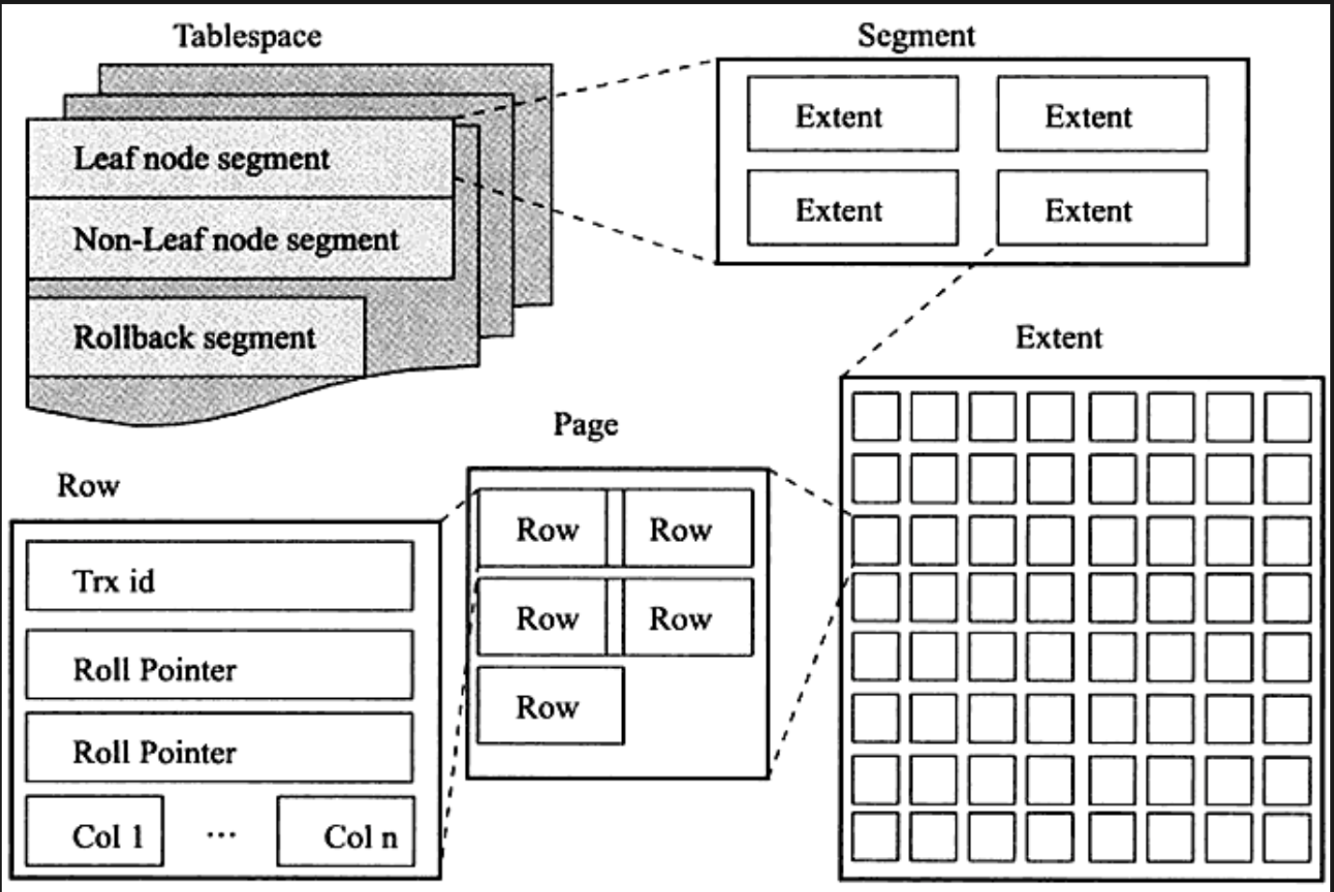
row
資料庫中的 record 都是按列(row)進行存放的。
row 本身會紀錄以下屬性:
-
row_id
這個如果建 table 沒有指定了主鍵或者 unique index,才會需要 row_id 隱藏欄位作為唯一值。
-
trx_id
事務 id,表示這筆資料是由哪個事務生成的。
-
roll_pointer
這條記錄上一個版本的指針。
page
資料庫中的數據是按頁 (page) 為單位來讀寫的,默認每個頁的大小為 16KB。因此一次最少從 disk 中讀取 16KB 的內容到內存中,一次最少把內存中的 16KB 內容 flush 到 disk 中。
page 還會分成很多類型如 data page, undo page 等等。
extent
每個區 (extent) 的大小為 1MB,對於 16KB 的頁來說,連續的 64 個 page 會被劃為一個區。會有 extent 的想法也是為了讓 B+tree leaf node 中的 page 的實體位置也鄉林,因此可以利用到 sequential io 的優點。
segment
表空間是由多個段(segment)組成的,段是由多個區(extent)組成的。段又分為數據段、索引段和回滾段等。
- 索引段:存放 B + 樹的非葉子節點的區的集合
- 數據段:存放 B + 樹的葉子節點的區的集合
- 回滾段:存放的是回滾數據的區的集合
PostgreSQL
(圖片來源)
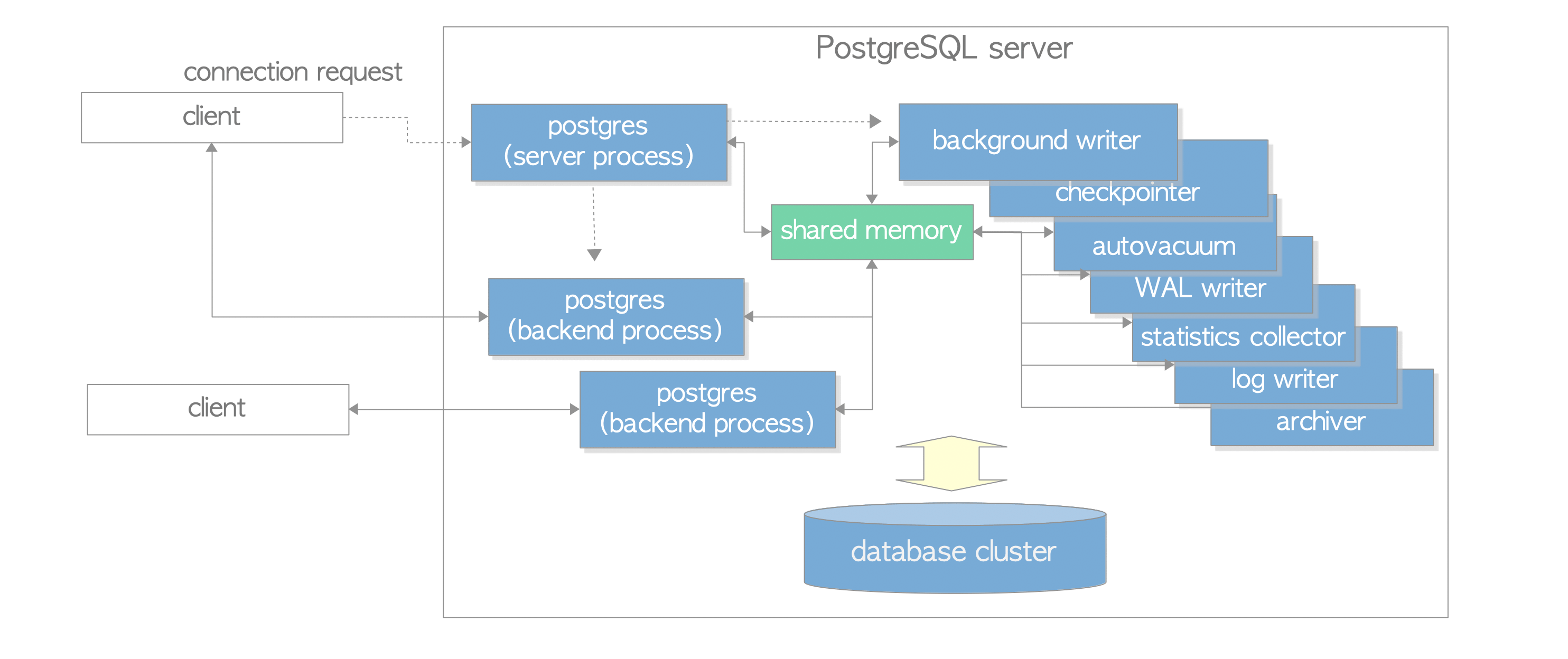
PostgreSQL 是走 client/server 的架構,其實每一個 connection 都是一個 process,一個 Server 管理多個 database,所以也可以當作一個 database cluster 就是 PostgreSQL Server。
整個 PostgreSQL Server 總共會有以下 process 組成:
- Postgres server process 是所有 process 的 parent,管理一整個 database cluster。
- 每一個 Backend process 處理 client 發過來的 query 跟 statement。
- 有一些 Backend process 是負責處理各種 feature,例如 vacuum 跟 checkpoint。
- 在 PG 9.3 之後多了所謂的 background worker process,可以讓 user 執行特定的 code
Logical Structure of Database Cluster
(圖片來源)
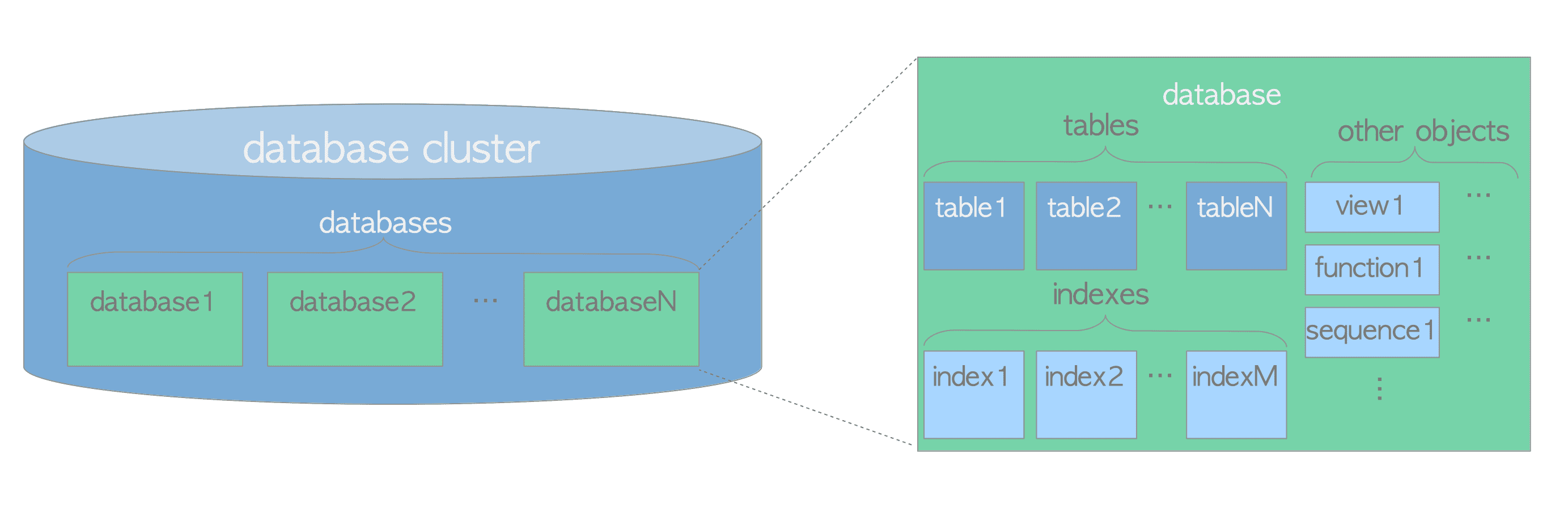
通常我們架設一個 PostgreSQL Server,底下可以有多個 database cluster,而每一個 database 底下會有自己的 (heap) tables, indexes 還有其他 objects 例如,view, function, sequence 等相關資料。而在 PostgreSQL 中,每一個 databse 本身也是一種 object,並且在邏輯上與其他 database 分開。
Physical Structure of Database Cluster
一個 database cluster database cluster 在實體上的規劃是透過所謂的 base directory 去定義入口點,而在這個 directory 底下會有一些子目錄跟很多檔案,去存每一個 databse 的資料。
(圖片來源)
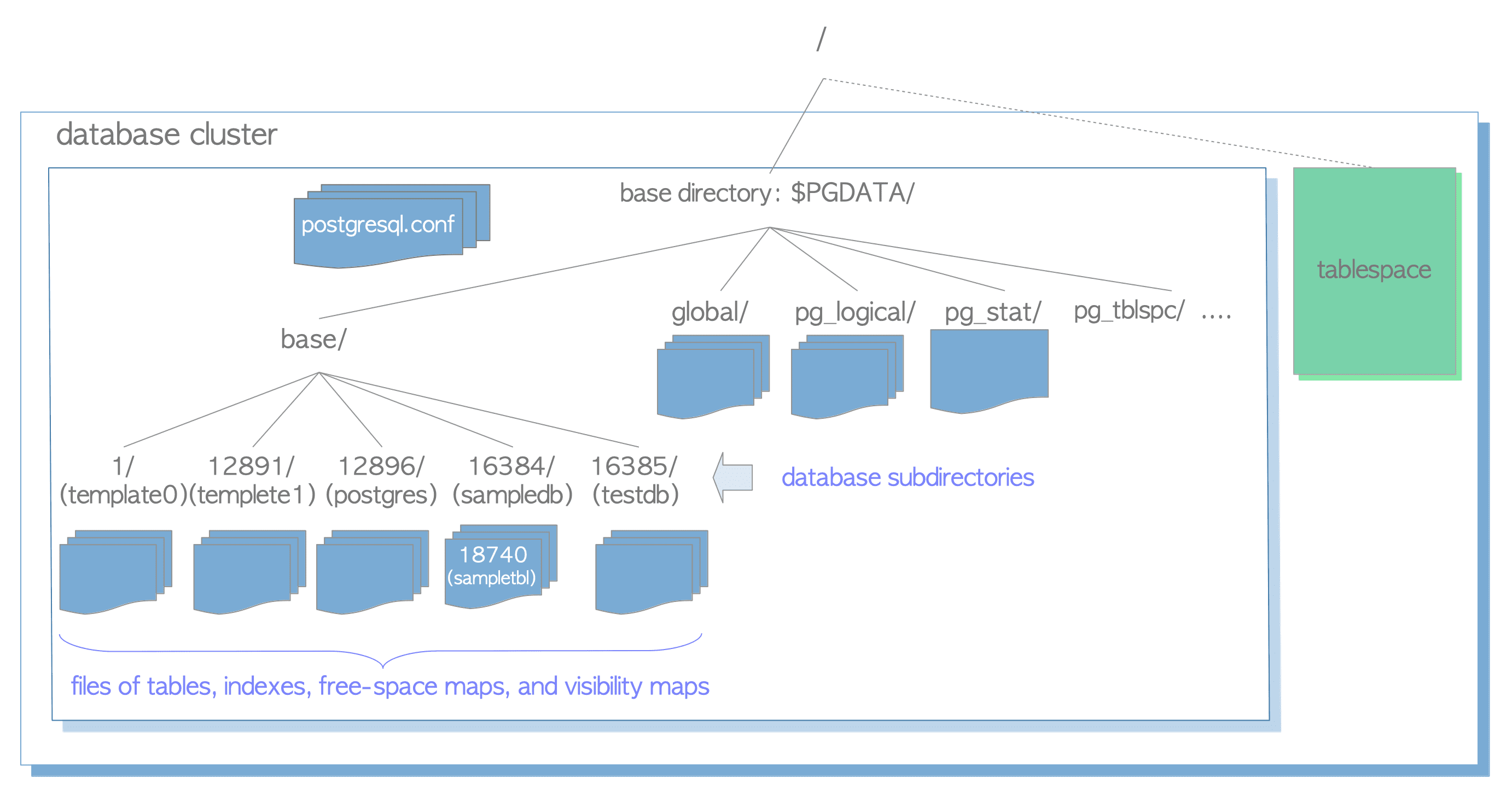
可以看到 base directory 底下有 base/ 目錄而裡面就會放每一個 database 的子目錄,而 database 子目錄底下就會再有 tables, indexes, free-space maps and visvility maps 等文件。
Table Space
在跑 initdb 後,默認會創建了兩個表空間 pg_default 和 pg_global。如果在建表時候沒有指定表空間,則默認是 pg_default。資料庫群中表的管理默認都是在 pg_global 中。pg_default 表空間的物理位置在 $PGDATA\base。pg_global 表空間的物理位置在 $PGDATA\global。
每一個 table 或是 indexes 如果大小小於 1GB,都會存成一個檔案在 database 的目錄下。Tables 跟 Indexes 也有各自的 OID 去表示,並且這些檔案是由 relfilenode 去管理,通常 relfilenode 與 OID 的值會一樣,例如:
1 | sampledb=# SELECT relname, oid, relfilenode FROM pg_class WHERE relname = 'sampletbl'; |
Internal Layout of a Heap Table File
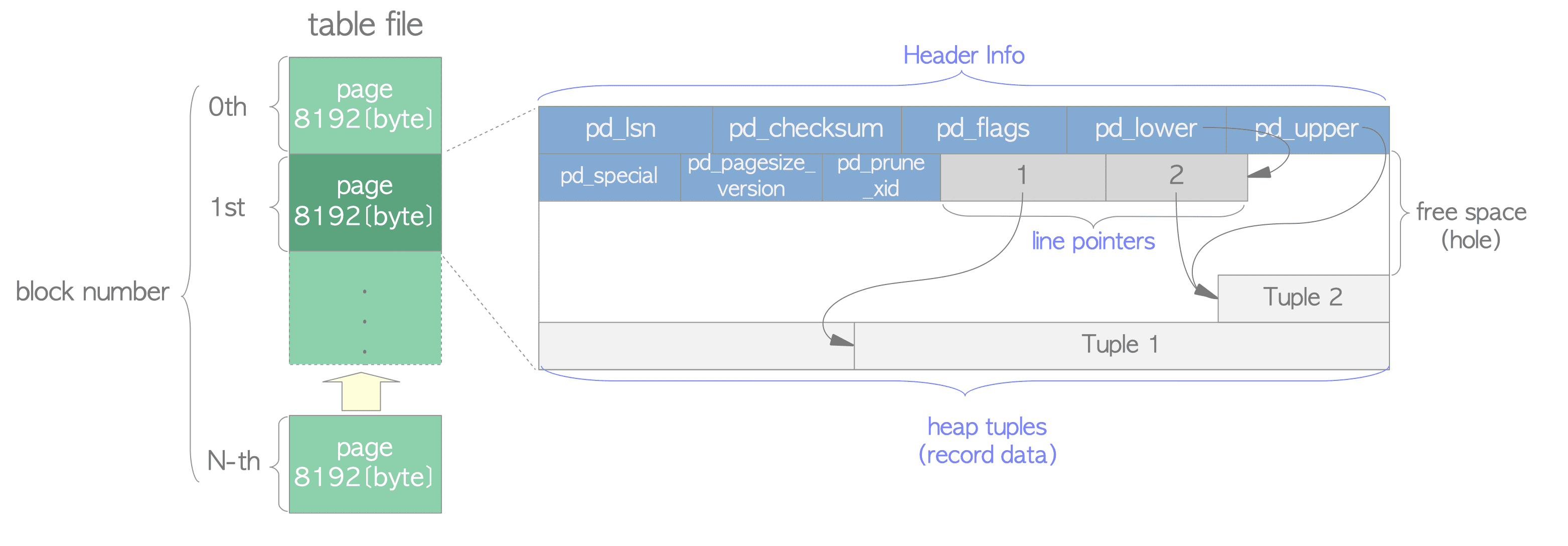
在每一個 Heap Table file 裡面會被劃分成固定長度的 Page (或稱為 Block),每一個 Page 預設是 8KB,每一個 file 裡面的這些 Page 都是按順序從 0 開始編號,這個編號通常稱為 block number,如果 file 滿的話,PostgreSQL 會在 file 尾端添加一個新的 empty page 來增加 file 的大小。
(圖片來源)
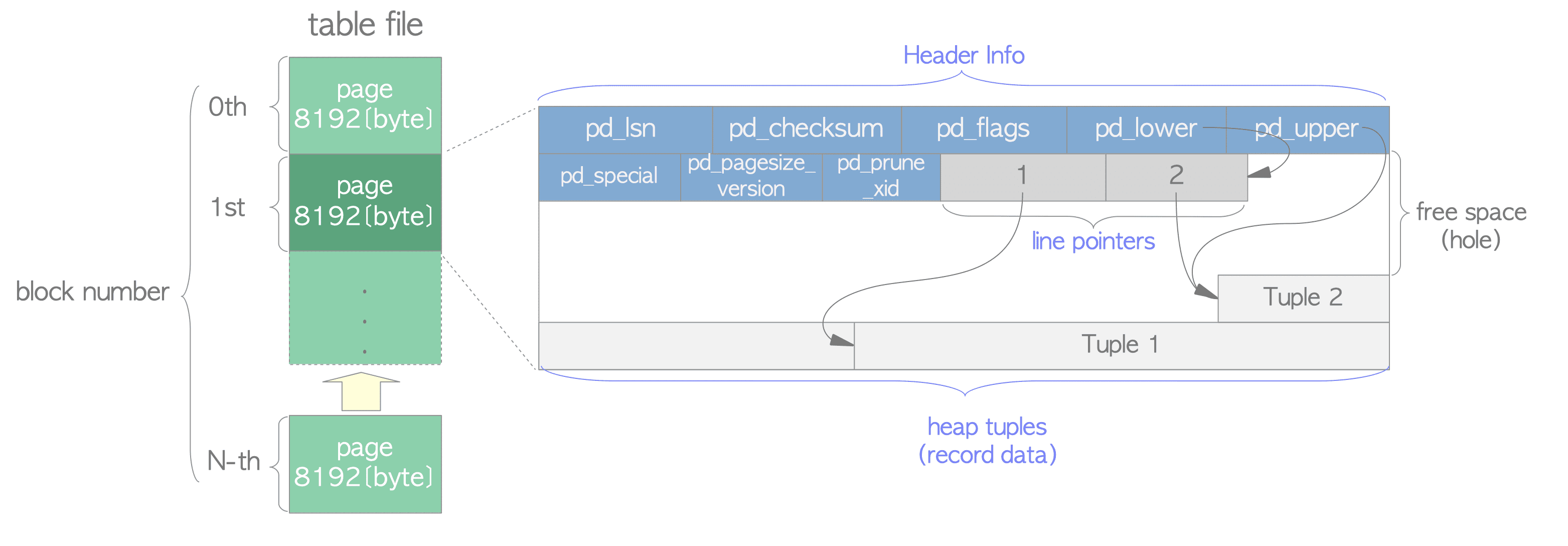
Table/Index structure
接著來談談 MySQL 與 PostgreSQL 儲存資料在 table 與 index 有什麼差別。
MySQL (Index Organized Table)
MySQL 底層資料存放方式是 IOT (Index-Organized Table),透過一座 B+tree 並使用 Primary Key 來進行排序,並在 leaf node 存放這個 Primary Key 所對應的整個 record。
(圖片來源)
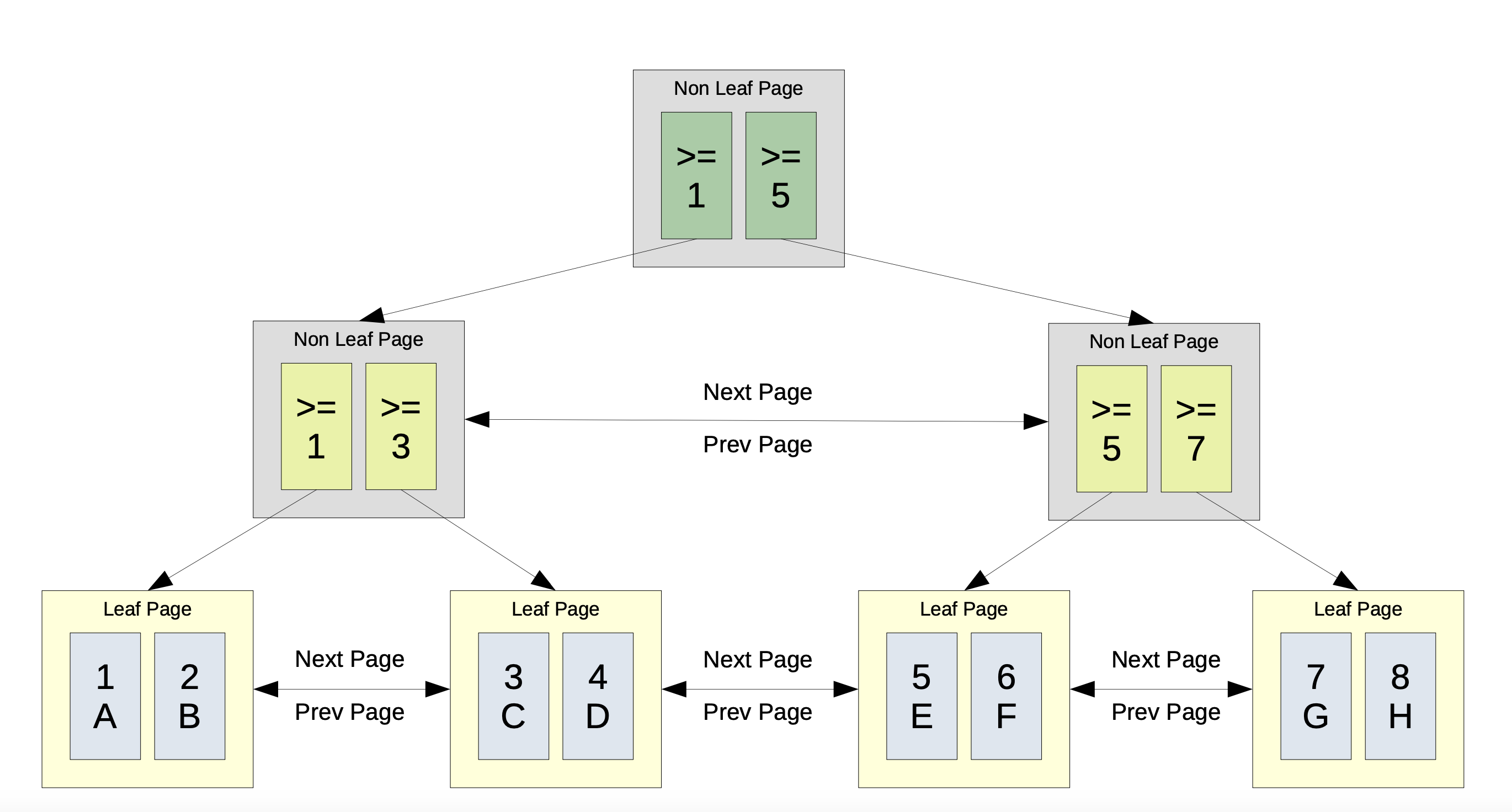
這種架構是將 Primary Key + data 做在同一個 tree,針對這種 primary key 又叫做 clustered index。但是當 page split /merge,整個 data 也是需要動的。
支援的 Index 方式
MySQL index 有 Btree index、hash index、full-text index 等等,而 Btree index 又區分為以下類型:
-
Clustered Index
-
Unique Index
-
Secondary Index
-
Partial Index
1
CREATE INDEX idx ON customer (name(10));
這個意思是取 name 的前 10 個字元為 index value。
- Functional Index (MySQL 8.0 才有)
除了 Clustered Index 之外都屬於是 secondary index,而 secondary index 的 leaf node 只存 pk value 而不存 data
(圖片來源)
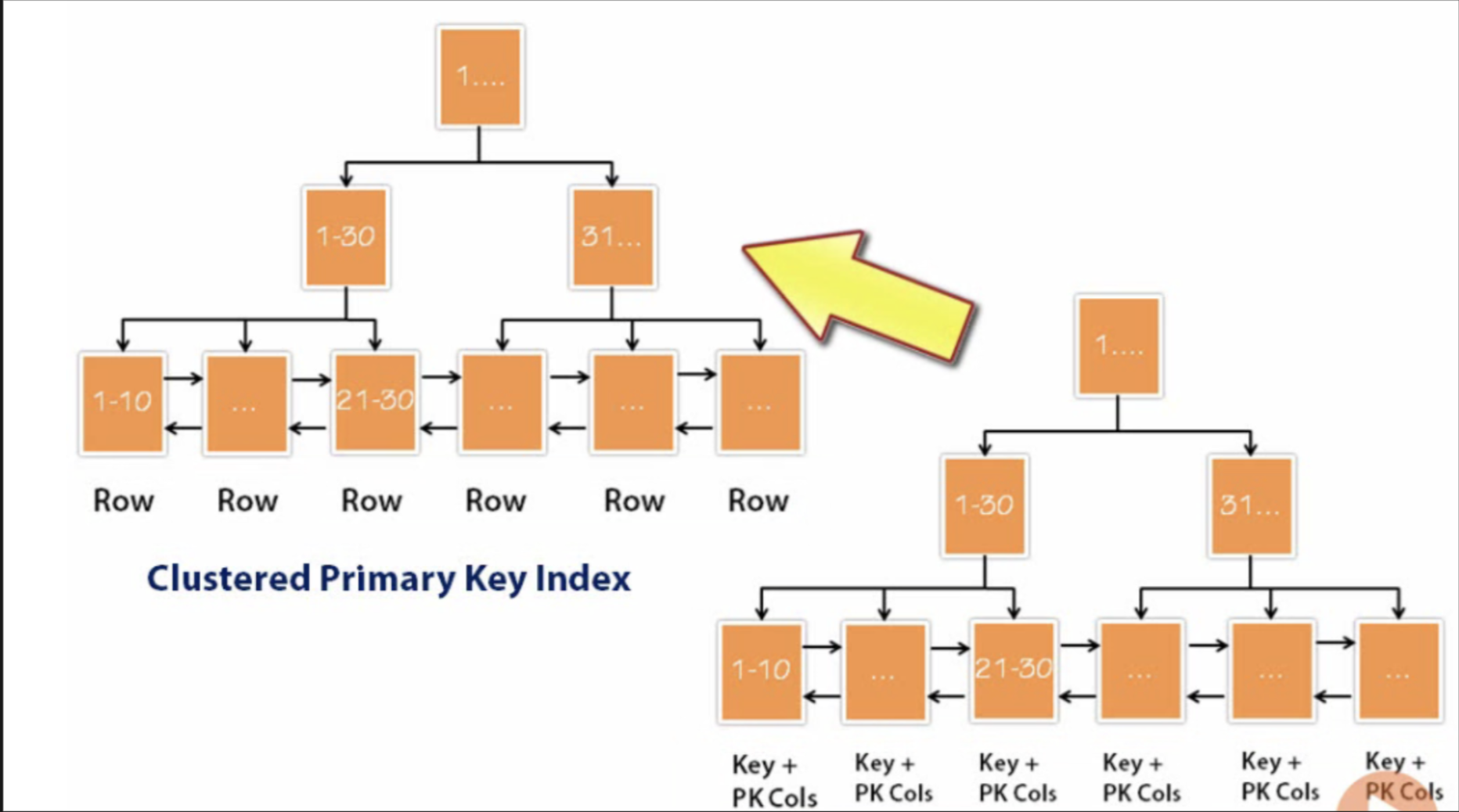
因此 secondary index 的問題在於:
- leaf node 只能存該 pk 的值
- 如果無法吃到 include index 的效果必須回 pk btree 去找
PostgreSQL (Heap Table)
PostgreSQL 底層的資料存放方式是透過 Heap Table 的方式,Heap 指的是沒特定排序的空間。PostgreSQL 存 data 的時候會 “隨機” 找一個 data page 來存放。而 PK 會透過 btree index 去維護,並且在 leaf node 會儲存指向 data page 的 pointer:
(圖片來源)
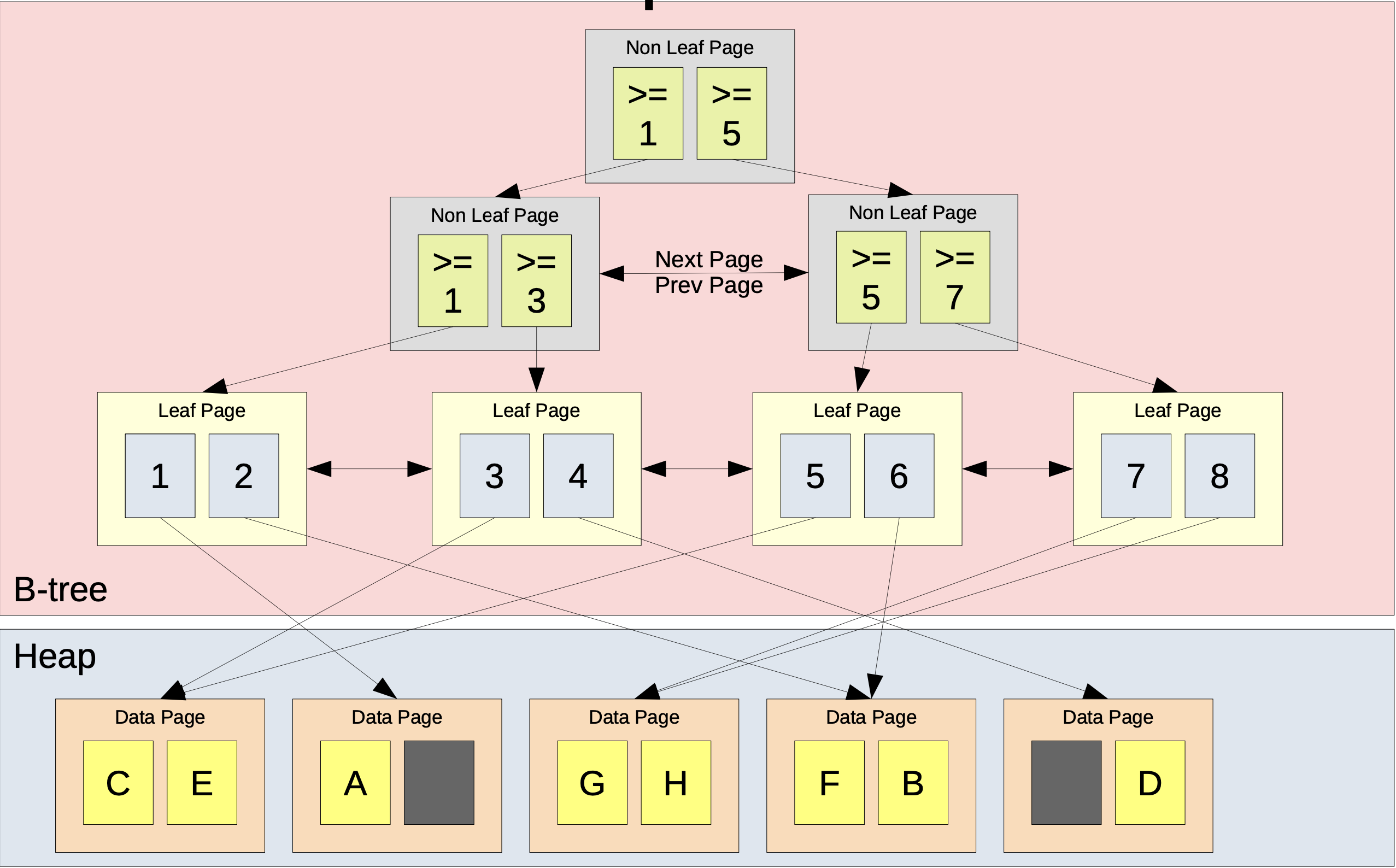
而這個指向 data page 的 pointer 其實就是存 PG 的 TID (tuple identifier),TID 由 block number 與 offset 所組成,指的就是 tuple 位於在那個 block 的 offset 上,因此才能快速找到 tuple。當 page split/merge 只需要移動 TID 即可。
實際來看 PG 的 file 內部組成:
(圖片來源)
-
每一個 file 會區分成好多個 8KB page,而每一個 page 內會存每一個 tuple 及相關 header info。
-
heap tuple (s):一個 heap tuple 代表一筆 record 的意思,heap tuple 會從 page bottom 開始按順序堆疊。
-
line pointer (s):一個 line pointer 是 4 byte 大小並且會指向對應的 tuple,也成為 item pointer。line pointers 是一個 array,array 的 index 就是指向 tuple,而每一個 index 數字是從 1 開始遞增,也稱作 offset number。當有新的 tuple 被加入到 page 上,會產生一個新的 line pointer 並加入到 line pointers array 裡面並且指向新加入的 tuple。
-
line pointers 的尾巴到最新的 tuple 這之間的空間就叫做是 free space 或是 hole。為了識別 tuple 的位置,能透過我們剛剛提到的 (TID) 來識別。一個 TID 包含一對 values,第一個 value 代表的是 page 的 block number 跟 第二個 value 是 line pointer 的 offset number 來指向 tuple。例如:
1
2
3
4
5sampledb=# SELECT ctid, data FROM sampletbl WHERE ctid = '(0,1)';
ctid | data
-------+-----------
(0,1) | AAAAAAAAA
(1 row)
剛剛我們提到 free space,我們前面又說理論上會隨機找個 data page 存 tuple,事實上 Postgres 有所謂的 free space management (FSM) 機制:
- 當 insert heap 或是 index tuple 時, PostgreSQL 會透過 FSM 來選擇要 insert 到哪個 page 上
- 所有的 tables 跟 indexes 有各自的 FSM,每一個 FSM 會存對於每一個 page 的空閑空間的資訊。
- 近期被寫進資料的 page 會優先被重用
支援的 Index 方式
- btree index
- include index
- index on several fields
- index on expression
- Partial index
- Hash
- GiST
- SP-GiST
- GIN
- RUM
- BRIN
- Bloom
非常多元。
談談 PK 對於兩種結構的影響
PK 通常就分為兩種類型:有序 (serial) 跟無序 (uuid)
我們就以這兩種性質去看說 IOT 跟 Heap 套用的優缺點。
有序性
IOT 架構下
- 通常會希望用有序性的 pk 且越小越好,這樣 leaf node 上才能放更多 record
- hotspot 會集中在少量的 leaf node,就會可能發生 blocking
- Before 5.7, every modifications to non-leaf pages required to exclude the other threads’ access to the whole index by X-lock (From MySQL document)
- range scan pk 比較快
Heap 架構下
- pk 越小的話加上 leaf node 不用放 record,所以可以比 IOT 放更多
- 但還是要考慮 page size 的問題
- page merge/split 的次數理論上會比較少
- hotspot 會集中在少量的 leaf node
- insert 理論上會比較快
- 增加 sequential io 的可能性
- range scan pk 比較慢
無序性
IOT 架構下
- 通常 pk 會比較大,leaf node 無法放更多 record
- 產生 page split/merge 機率就會更高
- random io 機率也會提高
- insert 理論上會比較慢
- hotspot 分散了,降低 contention
- range scan pk 還是快
Heap 架構下
- 就算 pk 比較大,但因為 leaf node 不用放 record,所以可以比 IOT 放更多
- page merge/split 發生機率理論上比較低
- random io 機率也會提高
- insert 理論上會比較慢
- 由於 hotspot 分散了,降低 contention
- range scan pk 比較慢
談談 Secondary Index 的影響
- IOT
- 如果無法 include index, 要回 pk 查詢會比較慢
- MySQL 的新手容易有迷思會濫用 index
- Heap
- secondary index 一樣可透過 TID 存取 record 會比較快
- 不管是 pk 還是 secondary,如果有 update,對應的 index 都要更新 (寫入放大)
- HOT 機制下可以降低發生的頻率
PostgreSQL 寫入放大問題
首先,我們先了解什麼是 Write Amplification (WA):
WA 是 SSD (固態硬碟) 特有的問題,原因在於 SSD 會將資料存在 NAND Flash Memory,而這個儲存架構下,資料是以頁面 (page) 為單位進行寫入,而一個 block 會包含多個頁面,當寫入新資料時,如果目標 block 已有資料,SSD 需要先將這些資料 copy 到另一個 block 中,然後 erase 原始 block。這個過程中,除了新資料的寫入還涉及到額外的資料讀取、複制和 erase 操作,其中快閃記憶體寫入的資料量 ÷ 主控寫入的資料量 = 寫入放大的比例
例如:NAND 快閃記憶體以每頁 4 KB 寫入資料,以每塊 256 KB 擦除資料
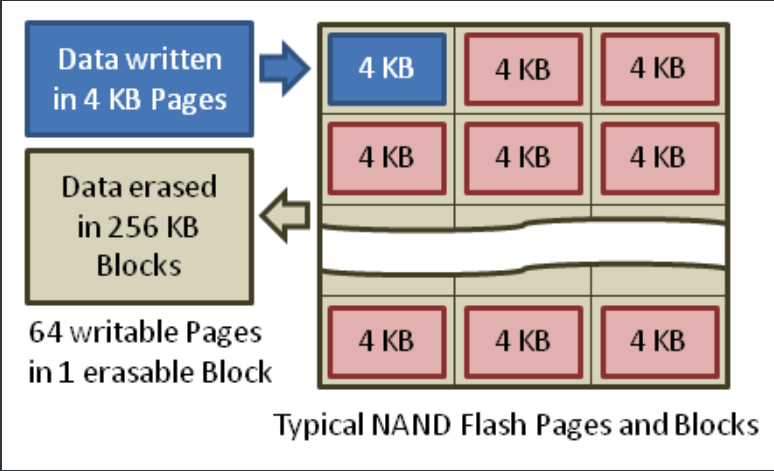
而寫入放大對 SSD 有兩個主要影響:
- 降低了寫入效率,因為需要處理更多的資料量
- 加速 SSD 的損耗,因為 NAND Flash Memory 的寫入 / 擦除次數是有限的。當然為了降低寫入放大的影響,SSD 控制器使用了多種技術,例如穿戴平衡(Wear Leveling)、垃圾回收(Garbage Collection)和 過剩配置(Over-Provisioning)。這些技術旨在優化數據的存儲和管理,從而提高 SSD 的性能和壽命。
PostgreSQL HOT 機制
HOT 是在 Version 8.3 開始實作的,主要功能是當要更新的 row 存在跟舊的 row 在同一個 table page,可以有效力的利用 index 跟 table 的 pages。HOT 也可以減少 VACUUM 處理的必要性。
假設 tbl 有兩個 column:id, data,其中 id 是 pk
1 | testdb=# \d tbl |
假設 tbl 有 1000 tuples,最後一個 tuples 的 id = 1000,並且存在第 5th page 上,最後一個 tuple 也會被對應的 index tuple 所指向,也就是 key = 1000,而 tid 為 (5,1)
(圖片來源)
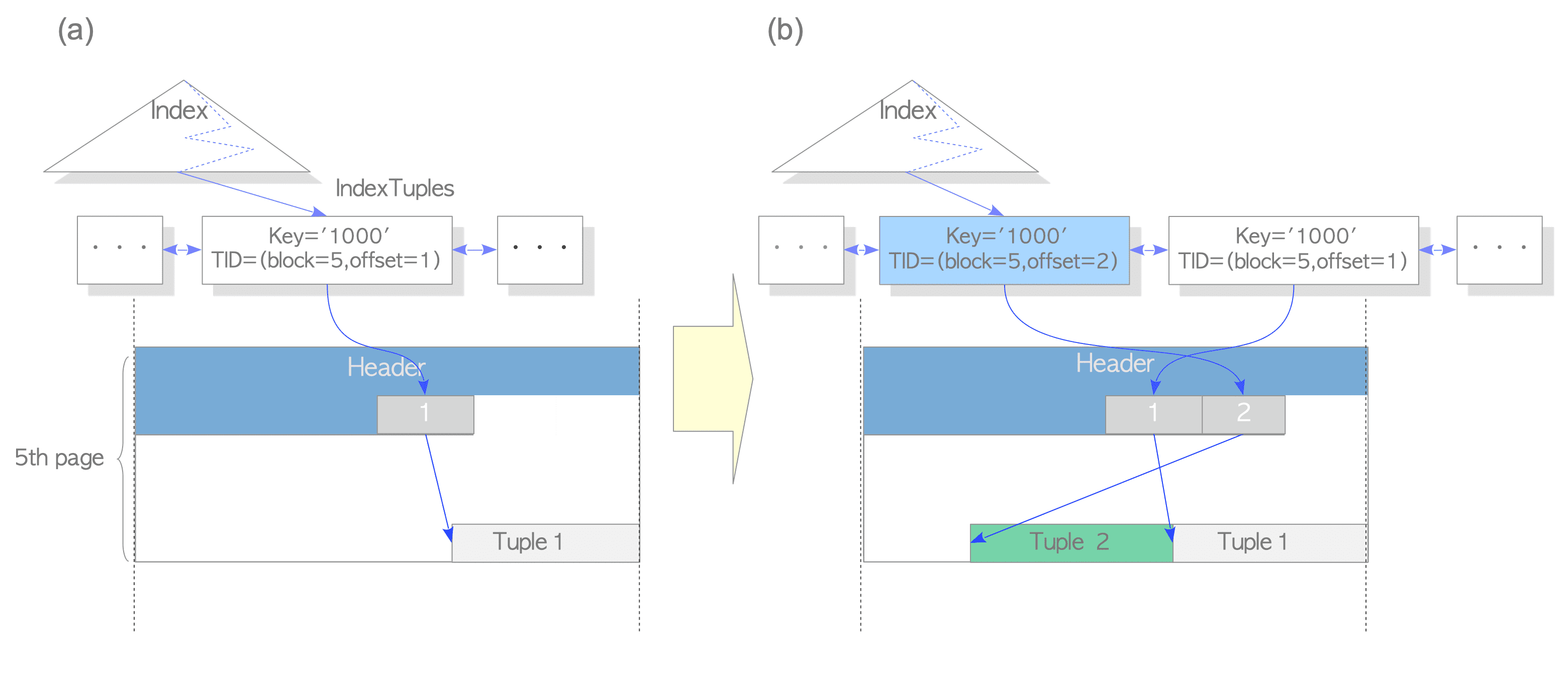
1 | testdb=# UPDATE tbl SET data = 'B' WHERE id = 1000; |
在沒有 HOT 的情況下,PostgreSQL 不只會 insert new tuple,new index tuple 也需要被加入到 index page 上,因為 insert index tuples 會消耗 index page 的空間,而且 insert index tuple 跟 vacuum costs 都會提升,HOT 就是為了解決這個問題的。
當 row 被更新時是透過 HOT 技術的話,如果 updated row 是跟 old row 放在同一個 table page 的話,PostgreSQL 不會 insert 對應的 index tuple 並且設定 HEAP_HOT_UPDATED bit 跟 HEAP_ONLY_TUPLE bit 到 t_informask2 fieds of the old tuple 跟 new tuple
(圖片來源)

但什麼情況下 HOT 不適用呢
- 當要更新的 update 是要存在另外一個 page 上,跟 old tuple 不是在同一個 page 上,新的 index tuple 指向新的 tuple 就必須建立在 index page 上
- 還有當 index tuple 的 key 被更新的話,新的 index tuple 也需要被插入到 index page 中
- 可以用 fillfactor 可控制留給 update 的比例 (預設 100% 代表沒有留給 HOT 的空間)
Logging
接著介紹 MySQL 與 PostgreSQL 的 log 機制差別
MySQL
- Undo log
- Redo log
- Bin log
Undo Log
每個事務當有修改一組的 Record,就會產生對應一組 Undo Record,這些 Undo Record 組成了這個事務的 Undo Log。除了一個個的 Undo Record 之外,還有開頭增加了一個 Undo Log Header 來記錄一些必要的資訊,一個 Undo Log 的結構如下所示:
(圖片來源)
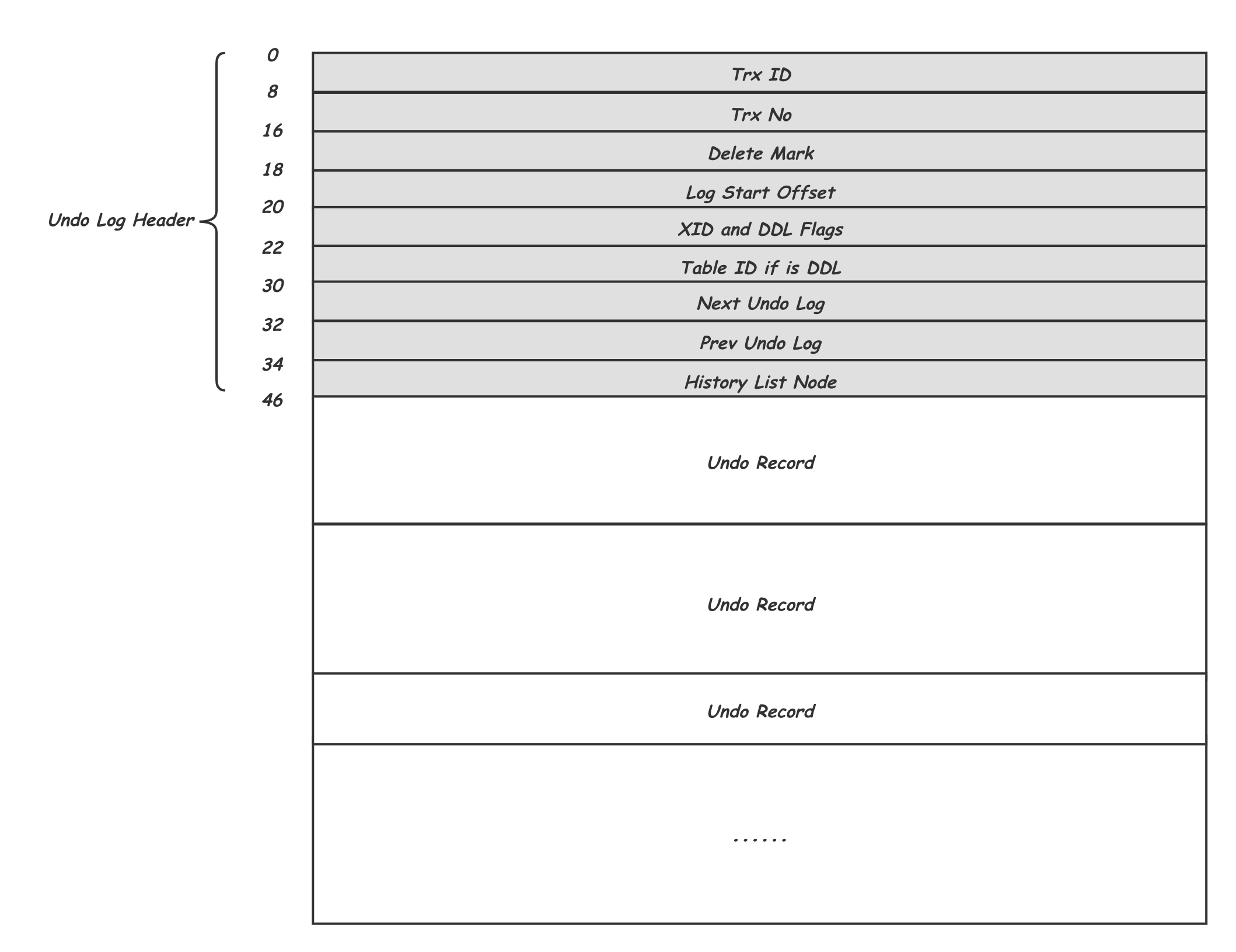
一條記錄的每一次更新操作產生的 undo log 格式都有一個 roll_pointer 指針和一個 trx_id 事務 id:
- 通過 trx_id 可以知道該記錄是被哪個事務修改的;
- 通過 roll_pointer 指針可以將這些 undo log 串成一個鏈表,這個鏈表就被稱為版本鏈
(圖片來源)
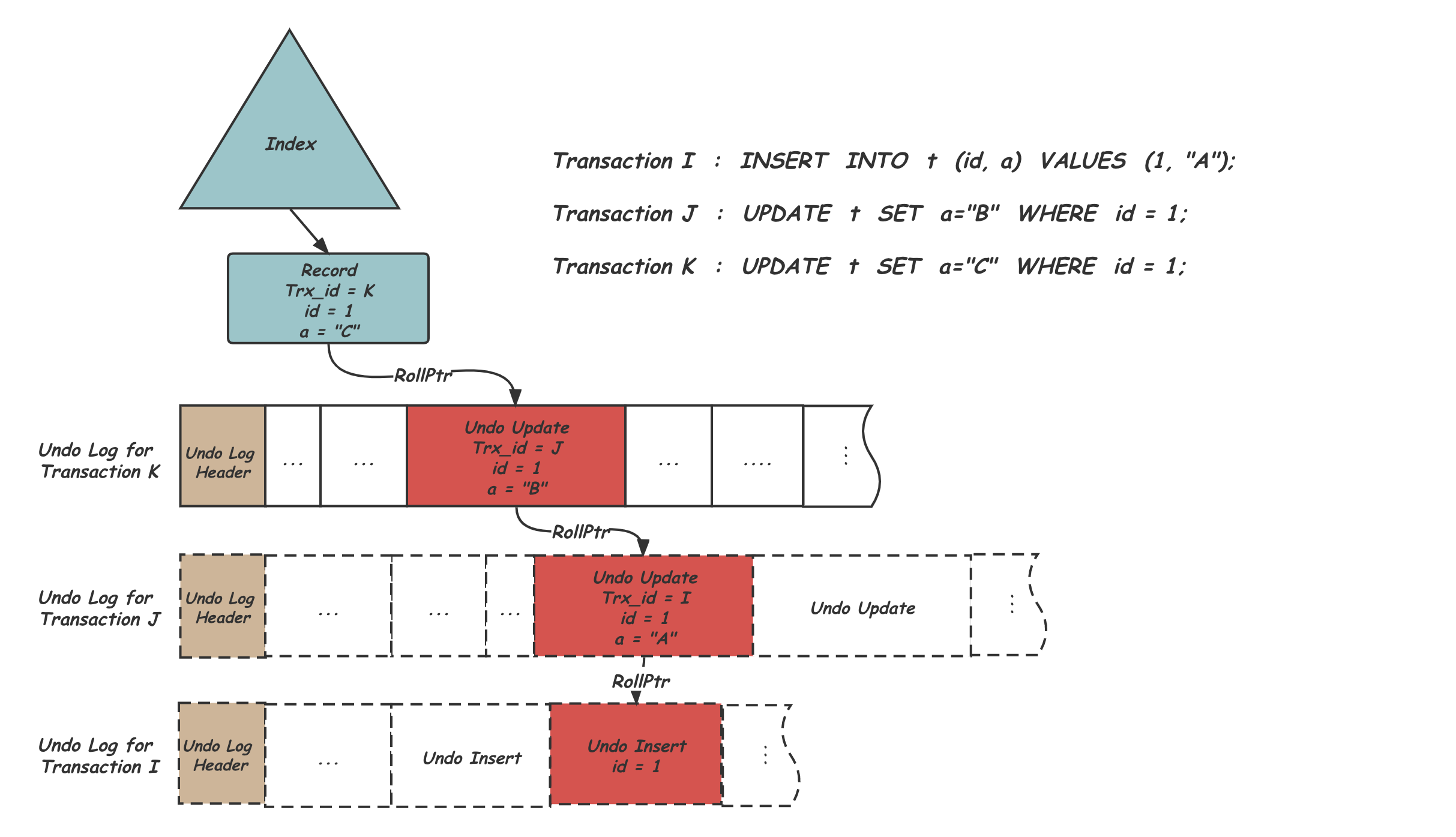
- 一個 write tx 至少會有一個 undo segment。
- 一個 undo segment 會包含至少一個 undo page。
(圖片來源)
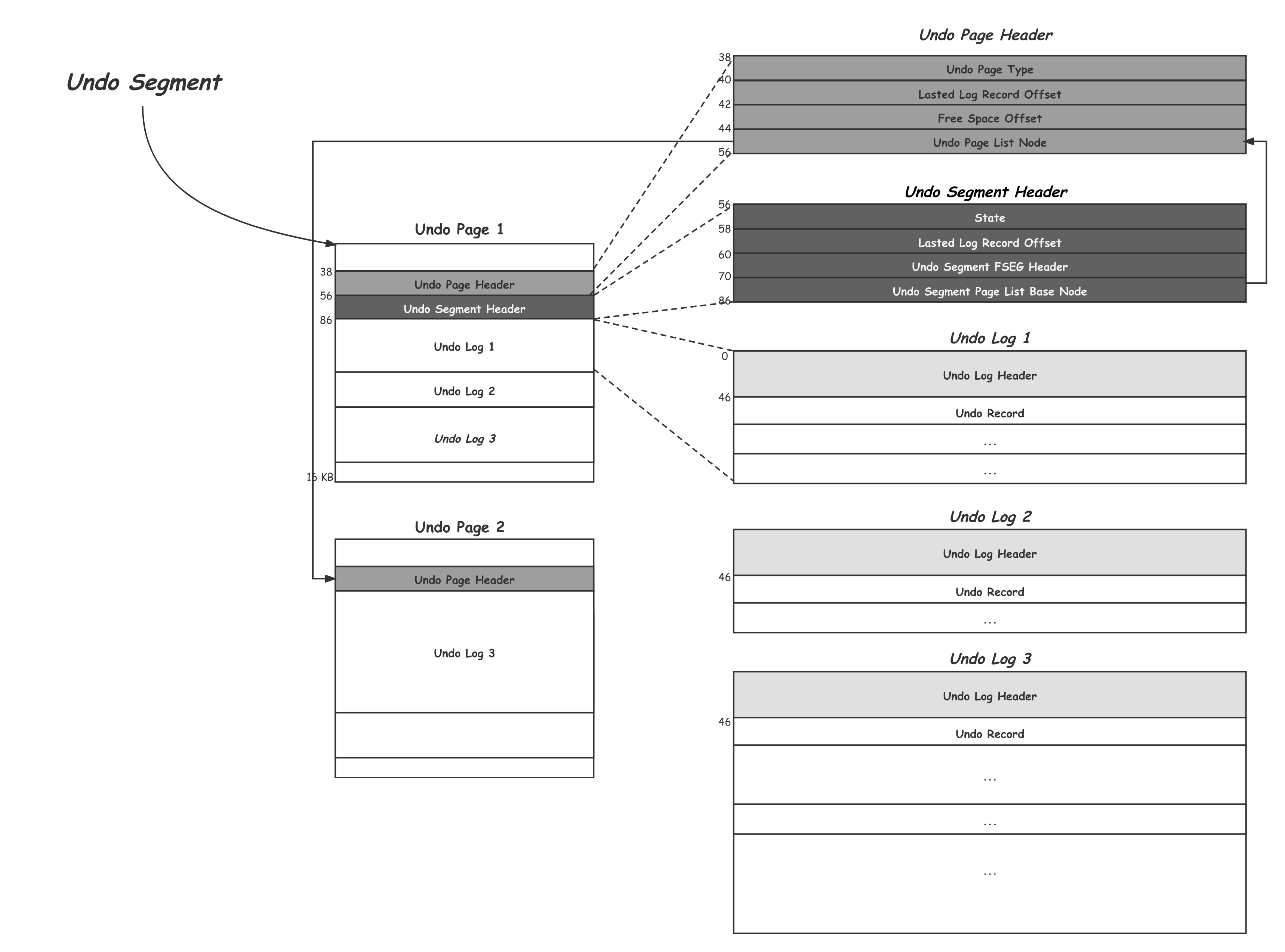
- Undo Tablespaces 會包含多個 Rollback Segement
- Rollback Segment Header 包含 1024 個 slot,每個 slot 佔 4 個 bytes,指向一個 Undo Segment 的 First Page。而 History List 拿來記已提交事務,後續的 Purge 會依序從這裡回收
- 每一個 slot 就是指向 Undo Segment
(圖片來源)
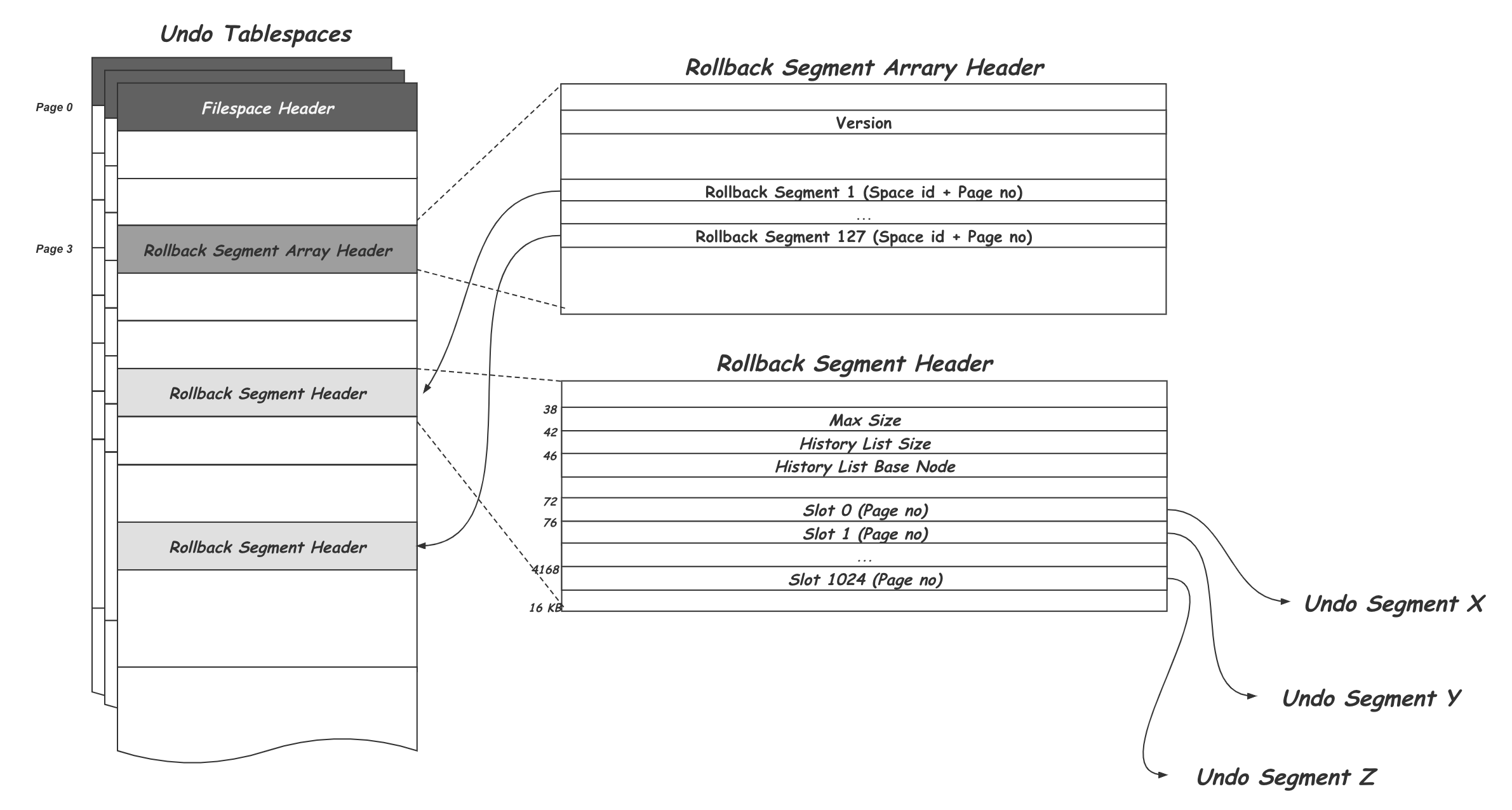
前面我們提到一個 write tx 至少會要一個 undo segment,但是 undo segment 是有數量限制的。因此會影響 tx concurrent 數量。
當滿了之後就會出現 concurrent transaction limit error。所以有太多 long running tx 無法釋放 undo segment 的話就容易出現這個問題。在 MySQL 8.0 支援了最多 127 個獨立的 Undo Tablespace,每個 undo tablespace 最多 128 個 rollback segemnt,每一個 rollback segment 根據 page size 大小決定產生 slot,預設 16KB page size 會有 1024 slot 也就是 1024 undo segment, default 會有 2 個 undo tablespace。
這邊官方有提供計算 concurrent tx 的數量:
If each transaction performs either an INSERT or an UPDATE or DELETE operation, the number of concurrent read-write transactions that InnoDB is capable of supporting is:
(innodb_page_size / 16) * innodb_rollback_segments * number of undo tablespaces = 1024*128*2 = 262144
最後:
- Undo log history list 會由 background 定期去 purge
- Undo log 的修改也需要紀錄到 Redo log (For Crash Recovery)
Redo Log
redo log 主要是為了 Crach Recovery 而存在的,也就是維持 ACID 的 D。
(圖片來源)
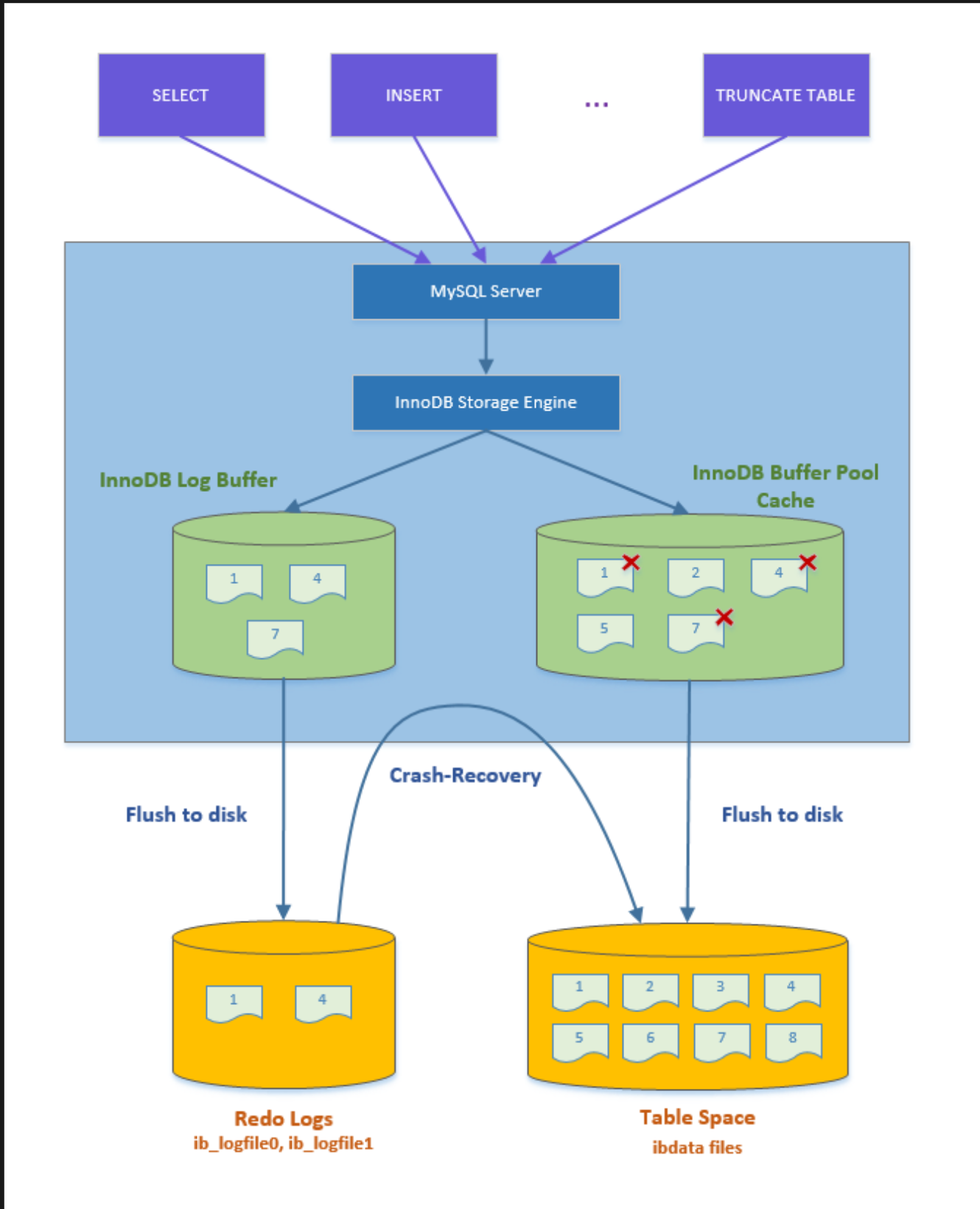
當有一筆 record 需要更新,會在 memory update page 並標記該 page 為 dirty 接著紀錄對這個 page 修改的 redo log。而 innodb_flush_log_at_trx_commit 可以控制寫入行為:
- = 0, commit 時將 redo log 留在 buffer 而不 flush
- = 1, commit 時將 buffer flush to disk (最安全)
- = 2, commit 時將 buffer wrrite to page cache
之後有 background worker 會定期將 buffer pool 裡面的 dirty page flush 到 disk 上。當系統崩潰時,雖然臟頁數據沒有持久化,但是 redo log 已經持久化,接著 MySQL 重啟後,可以根據 redo log 的內容,將所有數據恢覆到最新的狀態。
滿了怎麼辦
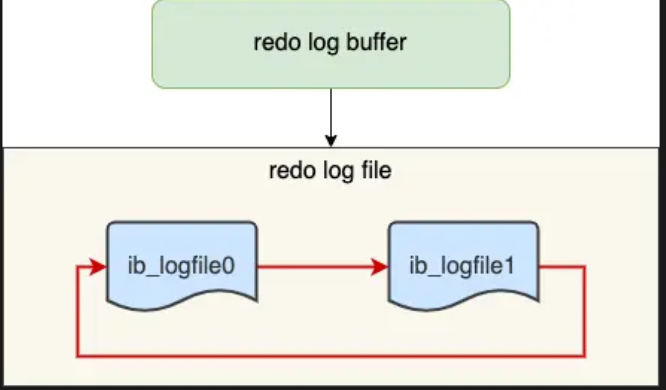
Redo log 寫的方式只會透過兩個檔案,也就是先寫 ib_logfile0 滿了再寫 ib_logfile1,造成循環寫的現象。
(圖片來源)
因為這樣,在寫的時候需要有所謂的 checkpoint 紀錄哪些 redo log 是可以清掉的:
(圖片來源)
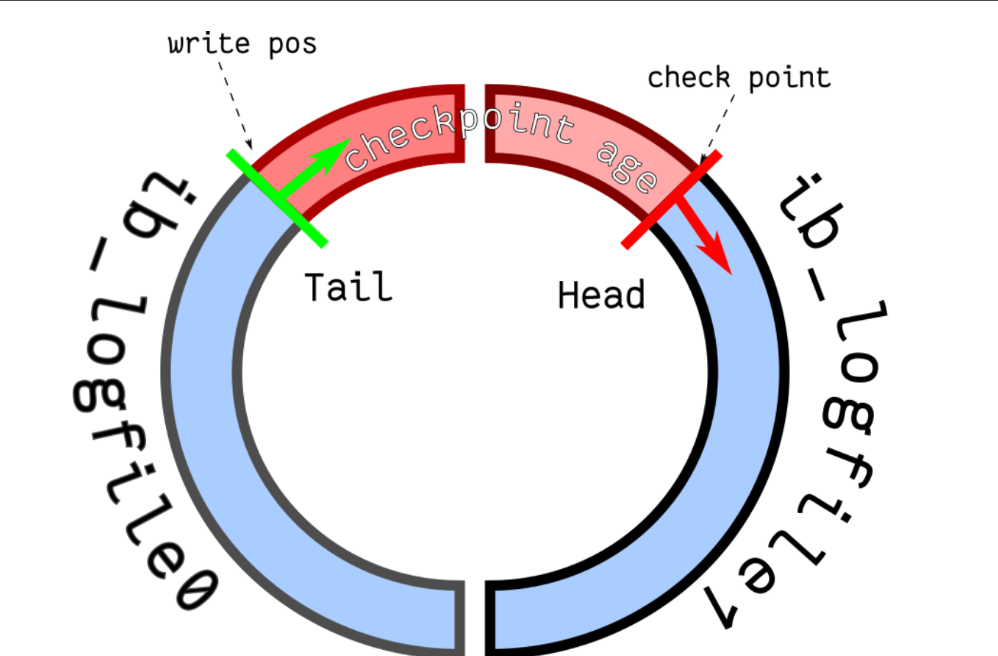
- write pos 表示當前寫的位置
- checkpoint 表示可以清除的位置
- redo log size 也會影響 tx concurrent size
Bin Log
每當有寫入操作,除了紀錄 redo log,還會紀錄 bin log,其格式分為 statement, row, mixed 三種。
- Statement: 紀錄 SQL statement,MySQL 5.7.7 之前的 default format
- uuid 與 replica 不同值的問題
- Row:紀錄實際 row 的值
- uuid 可解
- Mixed: 根據不同情況使用 Statement or Row
- 遇到 uuid 自動轉成 row format
(圖片來源)
-
之所以需要 bin log 是因為 redo log 只能 recovery 短期的資料
-
透過 backup bin log 才能 recovery 以前的資料
-
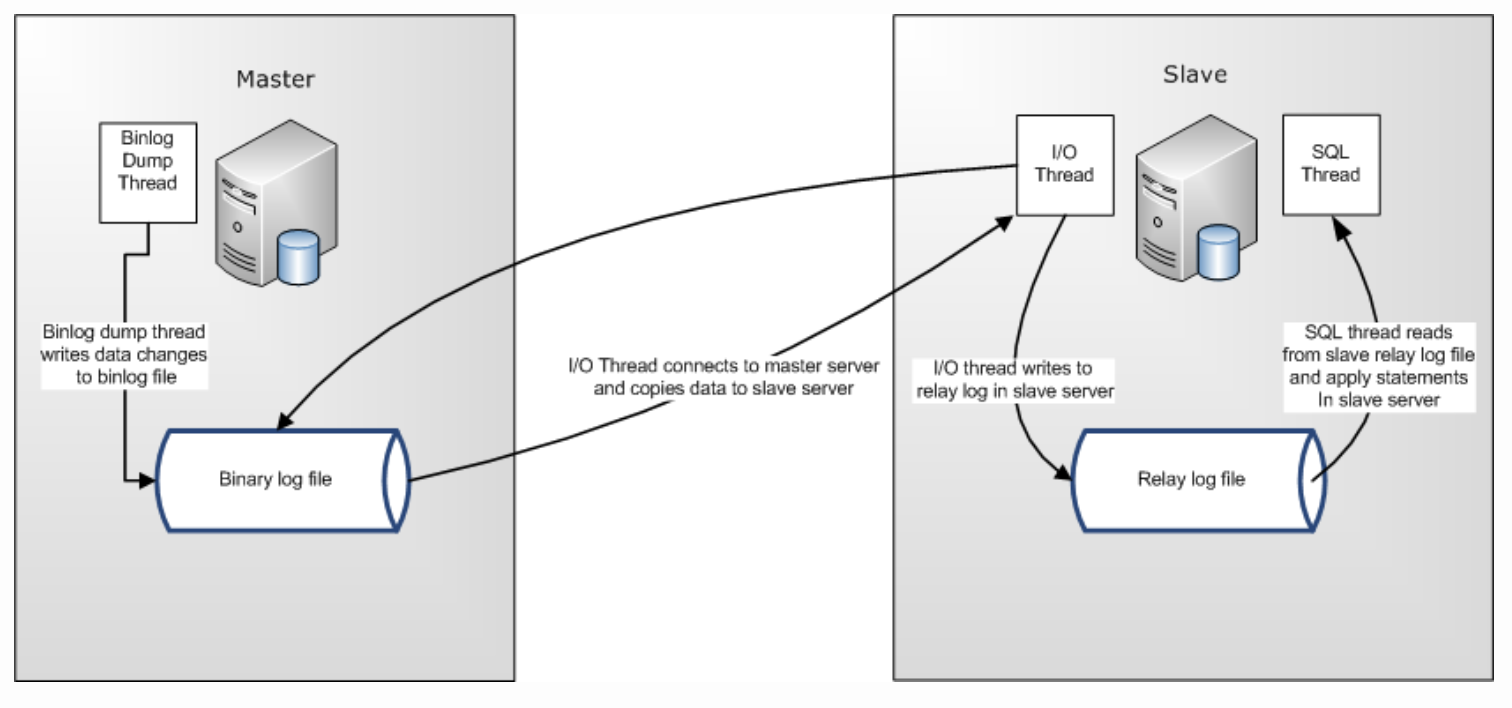
還有 replication 是透過 bin log 不是 redo log
slave I/O thread 會去拿 master 上的 bin log file 並且寫到 slave 的 relay log 讓 SQL thread 進行 replay。
(圖片來源)
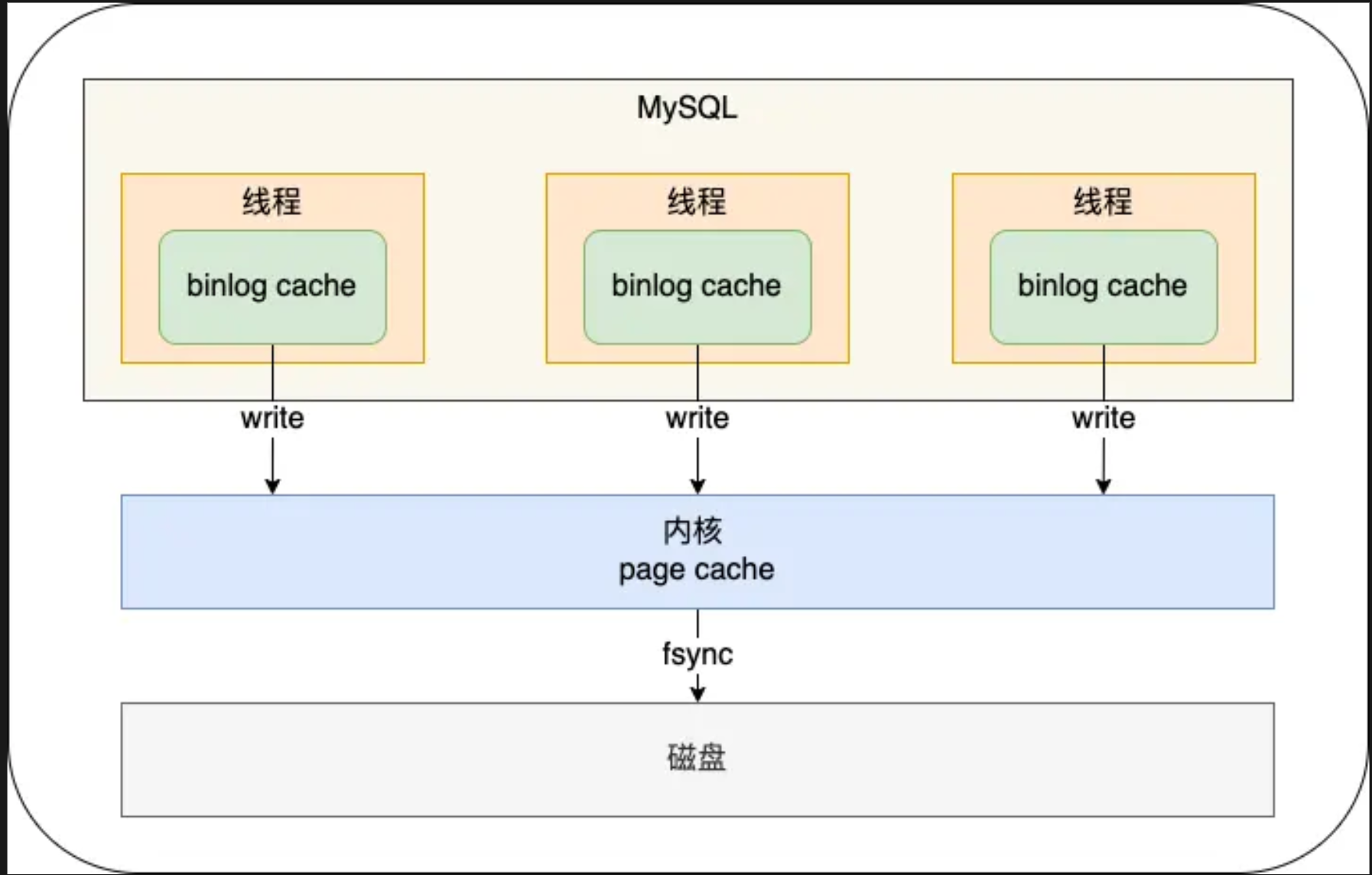
可以透過 sync_binlog 控制 flush disk 的行為
- = 0, commit 時只 write 不 flush (MySQL 5.6 前 default)
- = 1, commit 時會 flush (MySQL 5.6 開始 default, 最安全)
- = N, 累積 N 個 tx 才 flush
Redo Log 跟 Bin Log atomic 問題
2PC
因為 Redo log 與 Bin log 是寫入不同 file,commit 時兩邊會有寫入一致性問題。因此 MySQL 引入了 2PC 來解決這個問題:
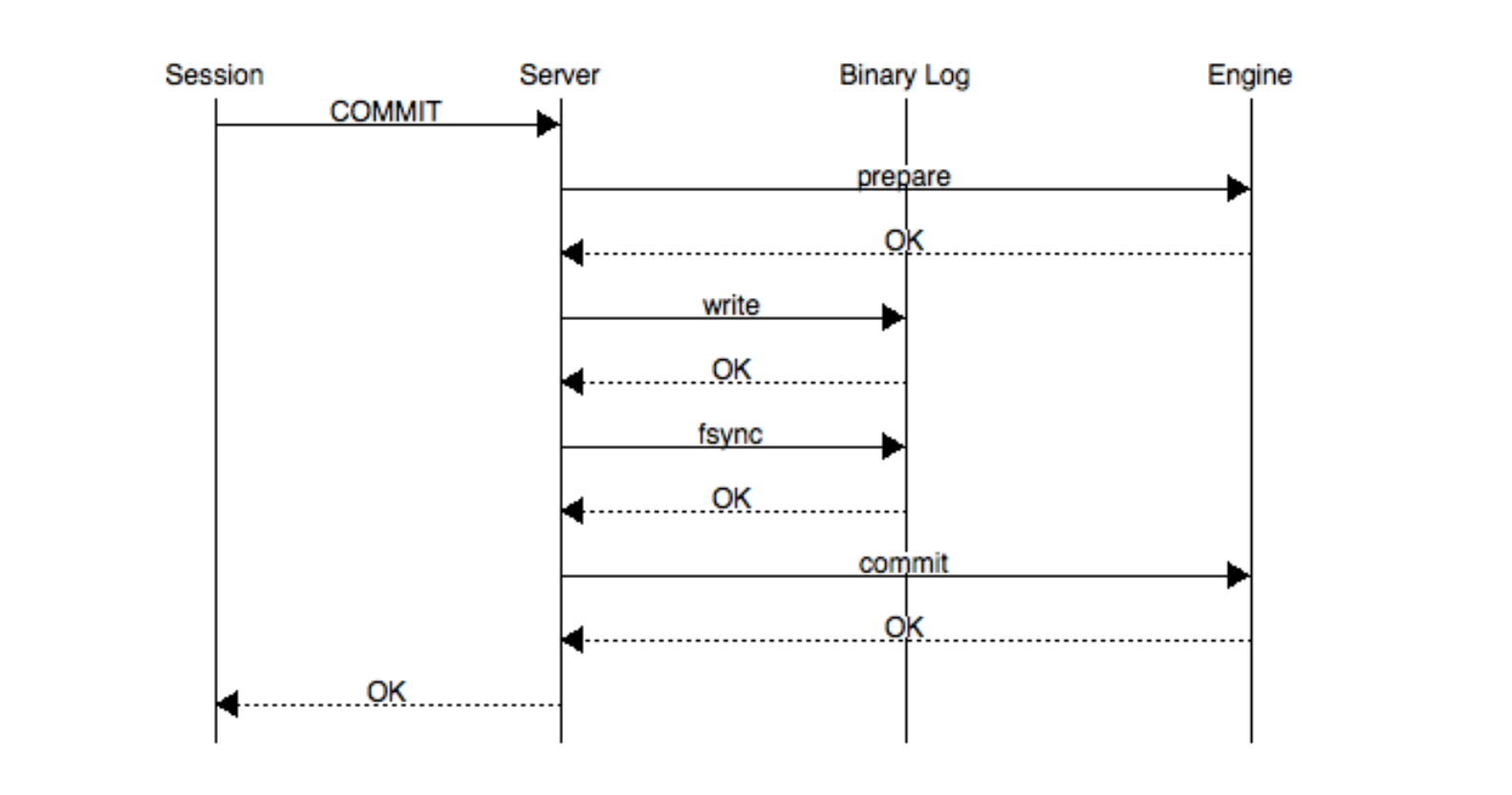
- Prepare Phase
產生好 tx id 及 redo 和 undo log。並將 tx 狀態設定為 TRX_PREPARED,並 flush - Commit Phase
將 bin log flush,callback engine commit interface,將 redo log 狀態設定為 commit
假設遇到 crash 而 redo log 處於 prepare 狀態,重啟後會去找對應的 binlog
- 如果 binlog 沒有對應的 tx id 則 rollback
- 如果 binlog 有對應的 tx id 則 commit
但是 2PC 會有效能問題:
- two fsync,為了確保兩邊 log 都能 flush to disk
- sync_binlog = 1
- innodb_flush_log_at_trx_commit = 1
- 多 tx 需要 lock 來保證兩邊 log 的順序一致
Group Commit
(圖片來源)
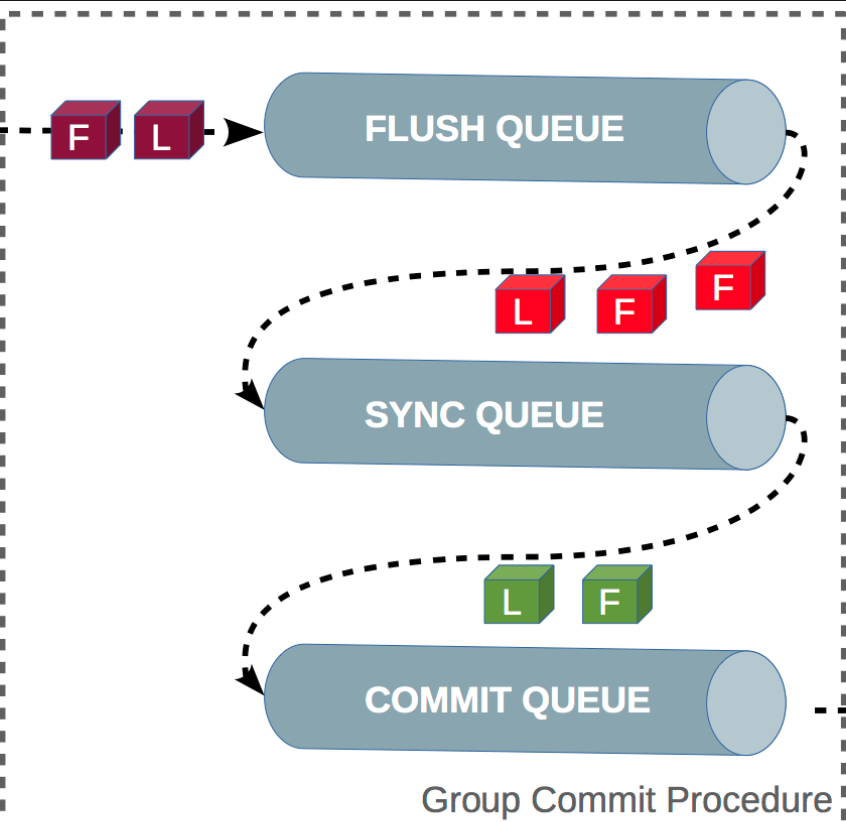
MySQL 透過 Group Commit 的方式將多個 tx commit 時的 binlog 操作合成一次 fsync 來降低 I/O 的次數。因此建立了三種 QUEUE 來做排隊:
- flush 階段:多個事務按進入的順序將 binlog 從 cache 寫入檔案 (還沒 flush)
- sync 階段:對多個 binlog 做 fsync 操作
- commit 階段:各個事務按順序做 InnoDB commit 操作
上面的每個階段都有對應的 queue,每個階段有鎖進行保護,因此保證了事務寫入的順序,第一個進入 queue 的事務會成為 leader,leader 會領導所在 queue 的所有事務,全權負責整隊的操作,完成後通知隊內其他事務操作結束。
這是 Bin Log 的 group commit,redo log 也是有對應的 group commit 不過這邊就不細談了。
另外,一直都有人在跟官方反應要將 Bin Log 與 Redo Log 合在一起比較方便,畢竟這邊的 2PC 的錯誤處理一定很麻煩且複雜,這樣其實更容易導致 bug。
PostgreSQL
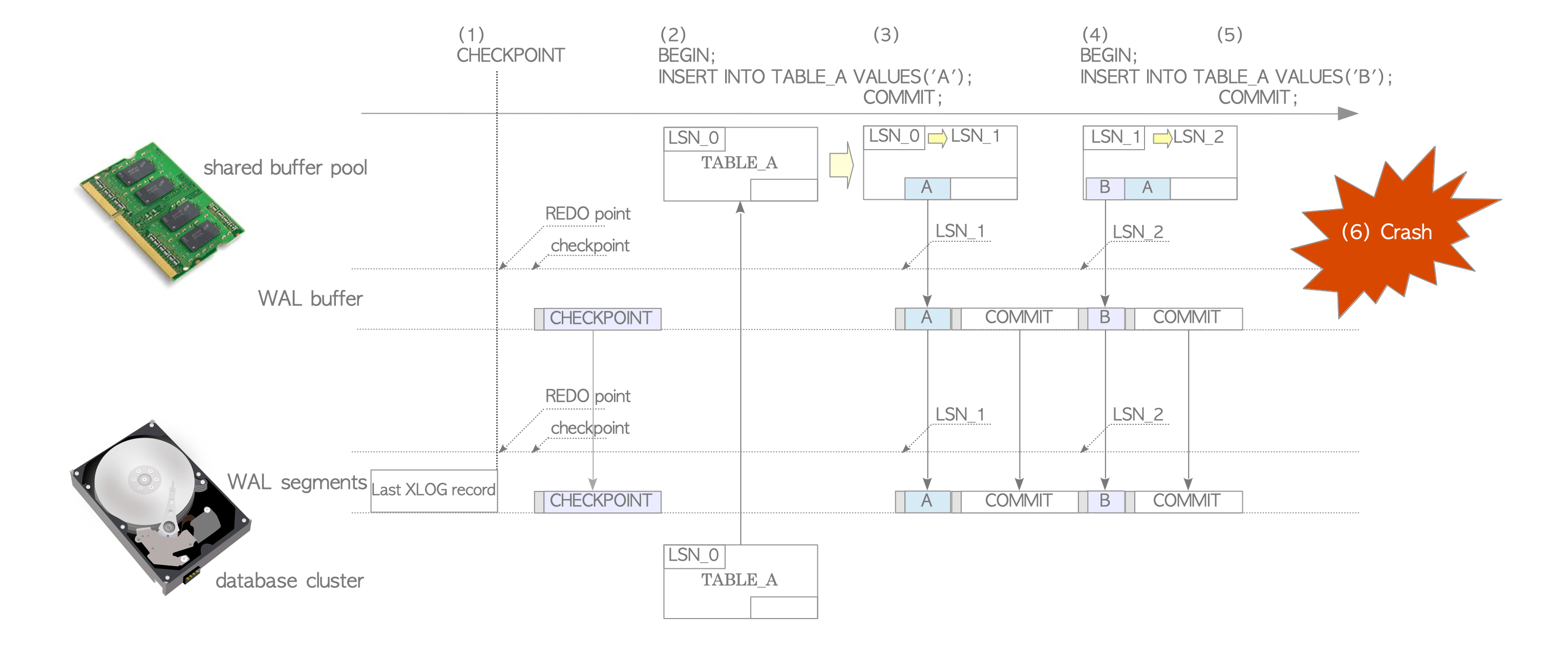
WAL log
- XLOG records 會先被寫入到 in-memory 的 WAL buffer,而當 tx commit 或 aborts 時會將 WAL buffer 的 WAL data flush。
- recovery 後按照 WAL segment XLOG 回放,是 redo log 方式
- 不支援 undo log (沒必要)
(圖片來源)
Isolation
接著來介紹 Isolation 的部分。
MySQL
- 可以支援 read committed, repeatable read, serializable
- default level: repeatable read
- MySQL 的 repeatable read 會有 lost update /write non repeatable read /phantom read 問題
Read View
- 用來實現 read committed 跟 repeatable read
- snapshot 的概念
- 實現 MVCC
- 背後由 undo log 來支持才會舊版本
其 Read View 會紀錄的屬性如下:
- m_ids:當前的 active tx id list (尚未 commit)
- min_trx_id: min(m_ids)
- max_trx_id: max(m_ids) + 1
- 建立該 Read View 的 tx id
- 每一筆 record 會紀錄 trx_id 與 roll_pointe
所以
- rc 下每一次的 query 都會產生新的 read view
- rr 下只對第一次的 query 產生 read view
都 RR 了為什麼還一堆問題!?
MySQL 最常被抨擊的點就是 RR 並不是我們想像的 RR,例如:
1 | start transaction repeatable read; |
在探討為什麼有這個現象之前我們先來好好看 RR 是什麼。
通常 RR 又稱 snanpshot isolation
- 在有了 MVCC 的概念下,各大 DB 藉此使用 snanpshot isolation 來實作 RR
- 以事務開啟的時刻(start_timestamp)做為 read snapshot,且為事務級快照,即事務內的任何語句,都使用相同的快照
- 待讀取的數據滿足:commit verison <= read snapshot
- 返回的數據是 commit 完成的
MySQL 下的 RR
- 只有 Read 讀的是 snapshot
- 不遵守 first-committer-wins 规则
- 官方認為 RR 是:Write committed Repeatable Read
- 因為 RR 下經常會出現如果兩個事務修改了同一個 record,那麼就需要後提交的事務重試這個流程,這樣對衝突多的場景是不好的
MySQL 下的 RR 基本原理與解法
- 一般的 select 都是拿 snapshot (consistent read from 官方說法,中國會叫做快照讀)
- update, insert, delete 的時候會改成走 read committed (中國會叫做當前讀)
- select … for update 會採用 next-key lock 的機制 (locking read from 官方說法)
- 鎖定本身 record 跟一個範圍,讓其他 tx 在這範圍無法執行 DML,因此解決 phantom read
- 但是 next-key lock 很容易造成 dead lock
- 而對於 DML 會走 read committed 的行為所產生的問題其解法如下:
- select … for update
- check-and-set operation
- optimism lock (version or timestamp)
- table constraint
為何 MySQL 堅持預設是 RR
歷史因素:
- 早期走 statement based replicaion 會因為 RC 而造成 primary/replica 資料不一致,但還沒推出 row based replication
- 就算現在有 mixed based replication,用 RC 還是會自動轉成 row based replication
MySQL locking 機制
-
基於 SX lock 機制
-
Intention Locks
-
分為 IS, IX 用來加速判斷衝突的效率
-
例如以下面兩個 query 來看:
1
SELECT * FROM users WHERE id = 6 FOR UPDATE;
1
LOCK TABLES users READ;
因為第一個 query 會對 users table 上 IX lock 又會對 id = 6 的 record 上 x lock
而第二個 query 則需要對 users 上 IS lock,但因為與 IX 衝突了就需要等待 lock,而不需要去 users table 一一檢查是否有 record 有上 X lock 才知道要不要等待 lock,加快判斷衝突的效率。
-
-
Row Locks
- Record Lock: 只鎖一條 record
- Gap Lock: 鎖定一個範圍,但不包含 record 本身
- Next-Key Lock:Record Lock + Gap Lock 的組合 (範圍加本身)
Record Lock
例如:
SELECT * FROM users WHERE id = 6 FOR UPDATE;
insert, update, delete
- 使用等值查詢
- 要透過 index 去上 lock
- 如果使用 secondary index 也會需要對 primary index 上 lock
Gap Lock
- 用範圍條件查詢
- 只存在 repeatable read isolation level
- 為了解決 phantom read 問題
- 對 index 間隙之間的 lock
SELECT id FROM t WHERE id BETWEEN 10 and 20 FOR UPDATE- 不管有沒有存在這範圍的 record,都對這範圍上鎖
- Gap lock 彼此不會互斥,但會跟 Insert Intention Lock 互斥,因為為了解決 phantom read (insert) 問題
Next-Key Lock
- Record Lock + Gap Lock 組合
- Next-Key lock 彼此會互斥
- 例如對 id 為 (5,10] 加上 Next-Key Lock,其他 tx 不能插入 id=7 也不能修改 id=10 的 record。
另外要注意的是 Gap Lock 跟 Next-Key Lock 是 RR 才有的,RC 只有 Record Lock 而已。而 RR 這樣的 lock 機制就很容易寫出有 dead lock 的 query。
為什麼 RR 下容易有 dead lock
1 | CREATE TABLE `t` ( |
其中 c 有上 index
而插入的這些資料可以來看看會產生的 gap 是長怎樣:
Gap Lock 造成的 dead lock
1 | TX A |
- 因為 TX A 執行 select … for update 時,id = 9 不存在因此會加上 gap lock (5, 10)
- 因為 TX B 執行 select … for update 時,id = 9 不存在因此會加上 gap lock (5, 10)
- TX B 這時想插入 (9, 9, 9) 會被 session A 的 gap lock 擋住
- TX A 這時想插入 (9, 9, 9) 會被 session B 的 gap lock 擋住
- deadlock
對 PG 而言兩邊的 for update 都不會上到 lock (no record),insert 只因為 unique 衝突,不會造成 deadlock。
Next-Key Lock 造成的 dead lock
1 | TX A |
- TX A 使用 share mode,在索引 c 上加了 next-key lock (5,10] 和 gap lock (10,15);
- TX B 的 update 在索引 c 上加 next-key lock (5,10] ,但只有 gap lock (5, 10) 加成功,row lock [10] 被阻擋
- TX A 要再插入 (8,8,8) 這個 record,被 session B 的 Next-Key 擋住
- dead lock
對 PG 而言只有對 c = 10 的 record 上 lock,session A 的 insert 不會 blocked
update 沒吃到索引會 lock table
- 如果 update 中沒吃到索引,會進行 table scan,所有的 record 都會被上鎖
- 因為會回 IOT table 找所有的 record,並且加上 record + gap lock
- 我猜測這就是為什麼 MySQL 派的很喜歡 index hint
SELECT * FROM table1 USE INDEX (col1_index,col2_index) WHERE col1=1 AND col2=2 AND col3=3; - sql_safe_updates 參數來強制噴錯,讓新手犯錯了可以被阻擋
- update 必須符合以下任一條件才能執行
- 使用 where 且條件有 index
- 使用 limit
- 同時使用 where 跟 limit 且條件可以沒有 index
- delete 必須滿足以下條件才能執行
- 同時使用 where 跟 limit 且條件可以沒有 index
- update 必須符合以下任一條件才能執行
PostgreSQL
- 沒有所謂 Gap Lock 跟 Next-Key Lock 的概念
- 只有所謂的 X Lock,寫入不會阻擋讀取
- 所謂的 For Update 就真的只對指定的 record 上 X lock
- 在 RR 下只會考慮 tx 開始前的 committed 版本,改動資料會檢查該 record 是否存在 tx 開始後的 committed 版本,有的話就會強制 rollback
Replication
接著來看看 Replication 兩邊的差異。
MySQL
- 早期的版本 log_bin 預設關閉,從 8.0 預設開啟
- 支援同步與非同步
- format
- statement based (default Before MySQL 5.7.7)
- row based (default)
- mixed based
Statement Based Format
- 只需要紀錄一模一樣的 sql statement,降低 binlog 大小,網路傳輸比較快
- 因為只紀錄 statement,所以某些函數會造成 primary /replica 資料不一致
- now () 的話 MySQL 會把實際的值傳給 replica (算是特別處理)
- uuid 的解法:
SET @my_uuid = UUID(); INSERT INTO t VALUES(@my_uuid);
Statement Based Format 不能使用 RC
binlog 會按照 commit 順序
1 | session 1 session 2 |
primary 有 record 3 但 replica 會沒有 record 3
Row Based Format
- 會紀錄每一個 row 修改,會加大 binlog,網路傳輸會比較慢
Mixed Based Format
- 根據你的 query 決定要走 statement 還是 row based
- 聽起來很美好,但有 bug
https://bugs.mysql.com/bug.php?id=107293 - 保險起見可能還是要 row based
GTID 介绍
- MySQL 5.6 推出,用來搭配傳統的 replication 機制
- global transaction identifier 可以代表某 tx id,且是 global unique
- replica 只能 replay 該 GTID 對應的 tx 一次,有助於維持一致性
- 會記在 binlog 上標示屬於哪個 tx
- 建立 replica 或 failover 情境好用
- 有點像是 PG 的 replication slot + pg_rewind 的組合
GTID 有無的差別
沒有 GTID
1 | change master to master_host="127.0.0.1",master_port=3310, MASTER_USER='repuser', MASTER_PASSWORD='password', MASTER_LOG_FILE='log-bin.000005', MASTER_LOG_POS=4111; |
開啟 GTID
1 | change master to master_host="127.0.0.1",master_port=3310,MASTER_USER='repuser',MASTER_PASSWORD='password',MASTER_AUTO_POSITION=1; |
對於建立 Replica 還是挺有幫助的。
PostgreSQL
- physical replication 跟 MySQL row based replication 差不多概念
- 但 logical replication 是不太一樣的
- 也是按照 commit 順序
- 寫入 WAL log 的內容是 tx 所改動的 record 並且用 PK 來識別來產生對應的 sql statement,因此不會有 MySQL 的問題
- 這也是為什麼複製 DDL 並沒有那麼容易
- https://wiki.postgresql.org/images/d/dd/20230602-DDL_Replication.pdf
- postgres failover 還是偏麻煩一點
Upgrades
MySQL
- 在 MySQL 8.0.16 之前,使用 mysql_upgrade
- 在 MySQL 8.0.16 之後,在 mysqld 使用 --upgrade
- 方式跟 pg_upgrade 大同小異
- 優勢的點在於很早期就支援 statement based replication,因此可以跨 major version replicated
- 不過 postgres 在 9.4 就已經推出 logical decoding 方案,因此也有 pg_logical 等的第三方套件,但的確設定起來還是挺複雜的
PostgreSQL
- 使用 pg_upgrade
- 在 PG 10 才支援 native logical replication,但還是不支援 DDL
MySQL Atomic 設計
1 | mysql> select * from t; |
wow,這邊中途有出錯還是可以繼續下去。跟 PG 的行為是完全相反。如果覺得這樣還不夠驚訝,我們繼續往下:
1 | mysql> select * from t; |
恩…
- MySQL 認為:commit /rollback 應該要用 client 端明確指定
- 如果 client driver 有 bug 的話這樣可能會滿嚴重的。
- PostgreSQL: 有錯就是會 rollback,讓資料庫幫你做正確的事情
DDL 比較
MySQL 只支援 atomic DDL
- 直到 8.0 才支援 atomic DDL
- PostgreSQL 可以支援 Transactional DDL
1 | -- atomic DDL |
MySQL Online DDL Change
-
在 5.5 之前只支援 copy 的方式
- 對 table A 建立 shadow table,並對 table A 加 exclusive lock
- 在 shadow table 執行 DDL change,並從 table A data copy to shadow table
- release exclusive lock
- drop table A and rename shadow table
-
在 5.6 加入 inplace 的方式,有三種變體
- INPLACE that updates only metadata:
alter table sbtest1 change column col1 col2 int not null default 1000;
- INPLACE that adds new object without touching existing one
alter table sbtest1 add index k_1(k);
- INPLACE that causes table rebuild
alter table sbtest1 add column col int not null default 1000;- 需要先在對應的 table 拿 MDL X lock,再來更新 metadata,之後將 X lock 降級 S lock,在執行 DDL,commit 前須在拿到 X lock,最後 release
-
在 8.0 推出 instant 方式,可以只改 metadata 就 ADD COLUMN
-
DDL blocked 的情境
1
2
3
4
5
6
7--tx1
begin -- tx2
select * from t; begin;
alter table t add column e int not null default 1000; -- tx3
-- blocked begin;
select * from t;
-- blocked
可以知道當你要 DDL change,如果前面有 long running 的 tx 就會導致 DDL change blocked 連帶後面的 tx 都跟著卡住。造成嚴重效能問題。
PostgreSQL Online DDL Change
- DDL 通常都是對 metadata 操作
- 所以 ADD COLUMN, DROP COLUMN 很快
- 大部分都不需要 rebuild table
- PG 11 前 default value 要 rewrite table
- 多數 DDL 前也先拿到 table 的 AccessExclusiveLock
- 會阻擋 read/write
- 但 create index concurrently 拿的是 ShareUpdateExclusiveLock
- 也會出現 DDL blocked 的情境
- 使用 statement_timeout 或 lock_timeout 來 backoff + jitter retry
總結
查了那麼多資料再搭配官方文件,還有一些 MySQL 與 PostgreSQL 的比較,我這邊有一些個人見解,大家可參考。
從開源的角度來看
- 可以相信 PostgreSQL 會一直屬於社區的
- Oracle 一直都有權利收回開源
- 可以考慮選擇 MariaDB,因為兩者 87% 像,甚至好用的功能 (window function 之類的) 都比 MySQL 早出現,性能也差不多
- 不過 MariaDB 從 10 版本開始脫勾 MySQL,可能開始不兼容
- 換個角度想有 MariaDB 的存在,Oracle 才會不太敢閉源
從 Architecture 的角度來看
MySQL
- 本身 storage engine 可拆分的特性,可以很方便替換不同的 engine
- support OLTP, OLAP
- 不過 PostgreSQL extension 也有不少彈性
- clustered table 的特性在 range scan on PK 有很好的成效或是維持 index 降低寫入放大的可能性
- 但 secondary index 的效能就有待考量
- default RR 下很容易發生 dead lock,也會因此降低 concurrent write 的性能,設計跟使用 index 也要很小心
- 大部分 benchmark 用簡單的 read/write query 去測試,現實是商業邏輯的 query 是複雜的,以 MySQL RR 的 lock 機制效能有待考量
- 但如果改為 RC 又有 replication 問題要處理
- rollback segment 也是會影響 concurrent tx 數量
- json 與 array 功能簡單
- 不會有 dead tuple 問題,但 undo log history 的問題一樣要處理
PostgreSQL
- 走 heap table 所以 range scan on PK 沒優勢,寫入放大有 HOT 幫忙,但無法總是成功
- 可以 by table 去設定 fillfactor
- default RC 下就足夠大部分的應用,即使用 RR 也沒有那麼多 lock 需要處理
- 相對來說開發就比較簡單,比較不會踩到坑,index 設計也比較直覺
- json 與 array 功能豐富
- 要處理 vacuum 及 replication slot 的問題,disk 很容易炸裂
- 太多 dead tuple 也是會影響 query performance
- logical replication 沒有像 MySQL 走得那麼前面
- failover 不比 MySQL 方便
- 大部分 tx 單純在 memory 修改 data page 並透過寫下 log 來保證持久性,所以都是 sequential io,但是 MySQL 卻需要另外的 2PC 機制來處理 redo log 與 bin log 的問題
結論
- MySQL 比 PostgreSQL 受歡迎很大一部份早期 PostgreSQL 不支援 Windows,加上 MySQL 搭配 wordpress 的興起與 LAMP 的風潮促使了大量的應用都是使用 MySQL
- 早期這種簡單的 web 應用資料一致性與效能不是真的那麼重要,用量不多且沒有複雜 query,因此 RR 很多坑沒錯,但無所謂
- PG 太晚開發 native logical replication 無法 rolling upgrade 也是一個痛點
- PostgreSQL 起步慢,很像是學術派的資料庫,在乎資料一致性,實現正確的 isolation ; MySQL 很像是自由派的資料庫,看起來啥都有,但又不夠 "細緻"
- PostgreSQL 很適合推薦新手的資料庫
Ref
- https://dbconvert.com/blog/mysql-vs-postgresql/
- https://www.datasciencecentral.com/history-of-mysql/
- https://www.postgresql.fastware.com/blog/postgresql-14-and-beyond
- https://medium.com/@ellierellier / 概念筆記 - 什麼是軟體授權條款 - software-license - 授權條款相關概念一次釐清 - 9d70e29f3a29
- https://www.interdb.jp/pg/pgsql01.html
- https://github.com/TritonHo/slides/blob/master/Taipei 2019-04 course/lesson2.pdf
- https://ducmanhphan.github.io/2020-04-12-Understanding-about-clustered-index-in-RDBMS/
- http://mysql.taobao.org/monthly/2021/10/01/
- http://www.notedeep.com/page/222
- https://gilbertasm.github.io/mysql/2018/04/15/understanding-mysql-replication-coordinates.html
- https://www.interdb.jp/pg/pgsql09.html
- https://juejin.cn/post/6962064785374445582
- https://zhuanlan.zhihu.com/p/3547197
- https://zhuanlan.zhihu.com/p/73637459
- https://xiaolincoding.com/mysql/