How We Achieved Minimal Downtime During Our PostgreSQL Database Upgrade (English Version)

Hello everyone, I’m Kenny, a Backend Engineer from Dcard.
Dcard is a social networking platform that allows everyone to share ideas with confidence, regardless of background, age, or interest. It is Taiwan’s largest anonymous communication platform.
Recently, we upgraded the primary PG 9.6 Cluster of Dcard’s services to the 11 version, managing to limit write downtime within ten minutes, and successfully rebuilt the OfflineDB and CDC services within an hour. In this article, we will share how we accomplished this challenging task.
Why the upgrade?
We decided to upgrade from version 9.6 to 11 for the following reasons:
- Official support for version 9.6 has ended, with the current minimum supported version being 11.
- Between versions 9.6 and 11, numerous new features and improvements were introduced:
- Version 10 introduced native logical replication.
- Version 10 enhanced the Query Parallelism feature, including support for parallel b-tree index scans and parallel bitmap heap scans.
- Version 10 added the CREATE STATISTICS feature to build additional statistics information that helps the planner use better plans and improve query efficiency.
- Version 11 introduced Parallel CREATE INDEX, improving efficiency.
- In version 11, default values no longer require a table rewrite.
- In version 11, vacuum efficiency was improved.
- Version 11 introduced the CREATE INDEX… INCLUDE feature that allows for index-only scans.
Additionally, Dcard’s current PG Cluster has a disk setup without partitioning, with the OS and PG data concentrated on a single disk. This makes handling backups and recovery cumbersome. We wanted to leverage the upgrade to improve PG performance and offer a better experience to users, as well as reorganize the disk partitioning for more convenient future maintenance and operations.
Common Upgrade Strategies
Below is an analysis of the advantages and disadvantages of common strategies for upgrading the major version of PostgreSQL.
dump / restore
Using pg_dump to dump data from the old version of PG and restore it in the new version of PG.
Disadvantages:
- Given the size of our database, it takes a significant amount of time to perform both the dump and restore operations.
- The dump process consumes a large amount of the DB’s CPU and memory resources, which can impact the experience of online users.
- The dump can only create a snapshot of the current state, and any subsequent new writes to the DB will not be captured.
pg_upgrade
pg_upgrade is an official in-place tool for upgrading from an older version to a newer version of PostgreSQL. Since the internal data structure of PG rarely changes between major versions, the pg_upgrade tool can reuse old data and use the --link option to create hard links instead of copying existing data to the new PG. The entire upgrade process can be completed within a few seconds.
Disadvantages:
- The old PG must be shut down.
- Performing an in-place upgrade on the OnlineDB can easily contaminate the data inside, making rollback difficult. Even if disk snapshots are used, the time from creating the snapshot to starting the VM will significantly extend the overall downtime.
logical replication
Logical replication is a statement-level replication, so it can support synchronization between different major versions of PG. Therefore, you can synchronize the current old version of the PG cluster to the new version of the PG cluster. When both are synchronized and during off-peak hours, you can simply switch the client to connect to the new PG cluster.
Disadvantages:
- Native logical replication is only supported from PG version 10 onwards.
- It cannot replicate DDL (Data Definition Language) commands.
The Upgrade Strategy We Chose
Before discussing the upgrade strategy we chose, let me first introduce a simplified architecture diagram of the current Dcard system:
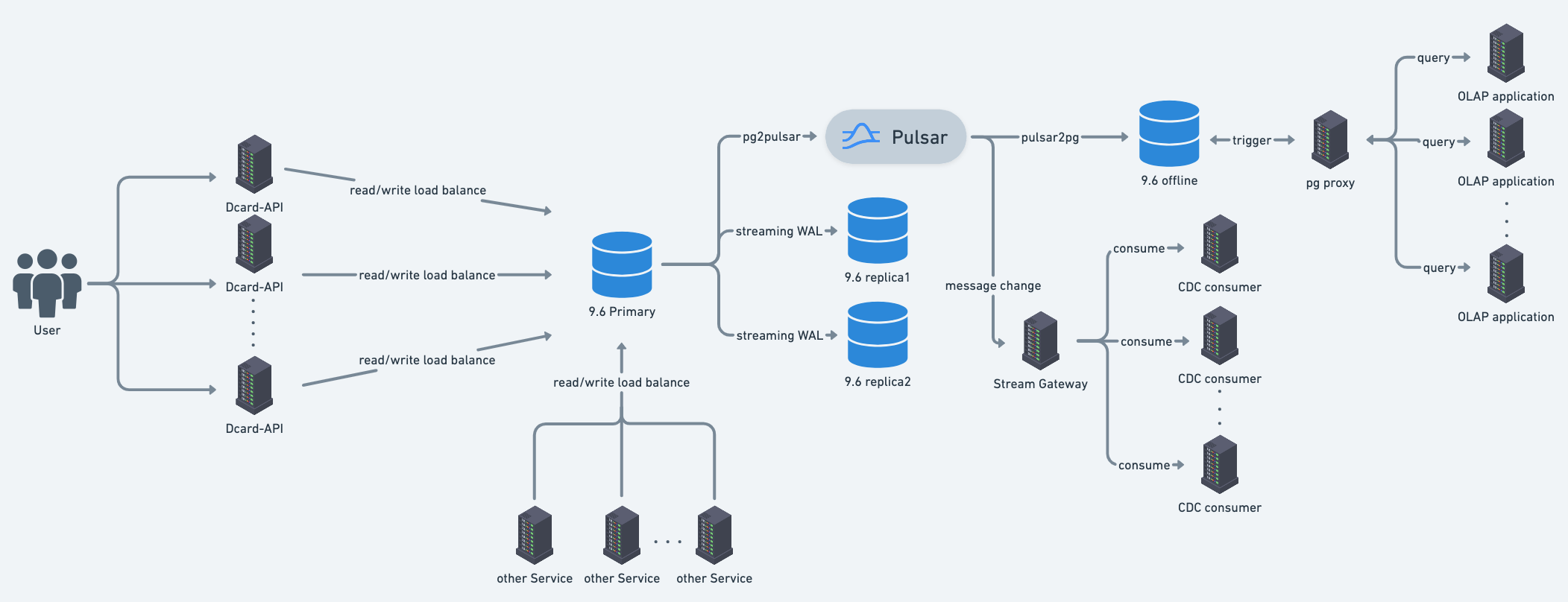
- Dcard’s main database is a PG 9.6 Cluster, which uses streaming replication. As a result, all major versions of PG within the cluster must be the same.
- The Dcard-API Server is mainly responsible for the core functions of Dcard, and its data comes from the underlying PG 9.6 Cluster.
- The PG 9.6 Primary sends logical decoding changes to Pulsar, which are then used by downstream OfflineDB and CDC consumers.
- Since Dcard’s architecture is based on microservices, there are also other services that directly connect to the PG 9.6 Cluster.
Based on the above architecture diagram, we can see that the PG 9.6 Cluster is involved in many services. However, we do not want to modify the existing service architecture specifically for the upgrade. In conjunction with the common upgrade strategies discussed earlier, we ultimately decided to use a combination of pg_upgrade and logical replication. We also accepted some write downtime rather than aiming for complete zero downtime, for the following reasons:
- pg_upgrade is very fast for upgrading a single machine.
- Dcard already has a mature CDC (Change Data Capture) architecture (which implemented by ourselves), which can overcome the limitations of native logical replication.
- To achieve zero downtime, we would inevitably have to deal with dual writes to both the PG 9.6 Cluster and the PG 11 Cluster. Given our data usage scenario, conflicts would likely arise. The resolution might require special handling at the application layer or manual intervention. Poor handling could result in a large amount of dirty data, which would be costly for us to manage in the future. After weighing these factors, we decided not to pursue zero downtime.
In light of the above reasons, our final upgrade goals are as follows:
- Accept write downtime (controlled within 10 minutes) but allow for reading, maintaining the user experience as much as possible.
- The underlying OfflineDB and CDC services can be rebuilt within 1 hour.
- The upgrade process should not affect the existing service architecture, such as migration handling at the application layer.
The entire upgrade process is as follows:
- During the day, set up a new PG 11 Cluster and use CDC to sync with the PG 9.6 Cluster.
- In the off-peak hours at night, switch the client to connect to the PG 11 Cluster, and control write downtime within ten minutes. Users can still perform any reading during this switch period.
- After the switch is successful, start rebuilding the underlying OfflineDB to ensure that OLAP Applications can process new data from the new OfflineDB in the future.
- Ensure that all current CDC Consumers have consumed all messages from the old topics, then switch all CDC Consumers to listen to the new topics.
Practice Exercise
After planning the upgrade strategy, we then conducted experiments on critical steps to confirm the required time and resources. We also needed to ensure that the entire upgrade practice would proceed smoothly before scheduling the official upgrade time.
Experiment with pg_upgrade
In the preliminary work of setting up the PG 11 Cluster, we first needed to clone the current PG 9.6 Primary and then use pg_upgrade for an in-place upgrade. In addition, we needed to test whether there were any incompatibility issues when upgrading PG 9.6 to PG 11 using pg_upgrade, as well as confirming the required time for the upgrade. The experimental results were as follows:
- The original PG 9.6 machine’s OS version was too old, and its apt repository could no longer install the newer version of PG. As a result, we installed PG 11 using the source code method.
- We needed to first install all third-party extensions that were installed in the old version of PG onto the new version of PG before using pg_upgrade for the upgrade.
- To perform a quick upgrade, pg_upgrade needed to use the --link option. According to the results, it only took 10 seconds.
Experiment with VACUUM FULL
As part of this upgrade, we checked the current state of dead tuples and free space in our database and experimented with VACUUM FULL to see how much disk space could be reclaimed. According to the results, we could free up 200 GB of space, so we decided to use VACUUM FULL for cleaning during this upgrade.
Experiment with PG 11 in the development environment
To ensure that the current services’ ORM Library behavior is compatible with PG 11, we conducted tests on important APIs in the development environment first.
Experiment with PG 11 in the production environment
When testing for compatibility of our current services with PG 11, we first conducted tests on important APIs in the development environment. Once the development environment was confirmed to be problem-free, we proceeded to test PG 11 in the online environment. We added a PG 11 Replica to the current PG 9.6 Cluster, and the replica synced with the PG 9.6 Primary through CDC. However, the limitation of this test was that we could only test reading behavior on PG 11, not writing behavior. To perform a writing behavior test on the production environment would necessitate special handling at the application layer or use of a custom-made proxy. After weighing the options, we decided only to test the writing behavior of important APIs, avoiding the extra cost of upgrading.
Experimenting with CDC Sync between PG 9.6 and PG 11.
When setting up the PG 11 Cluster, this process may require several hours of preparation time. During this time, PG 11 will have a data gap with PG 9.6. We need to experiment whether the time for the PG 11 Cluster to catch up with the PG 9.6 Cluster will be too long, and we also need to monitor whether the subsequent replication lag is short and stable. According to our experimental results, even with several hours of data gap, our mature CDC architecture allows the catch-up process to be completed within an hour.
Experimenting with Rebuilding OfflineDB
After the upgrade is completed, we need to select a data disk from a PG 11 machine to generate a snapshot, and then create a new OfflineDB for the OLAP application to use. Therefore, we need to experiment on how long it takes to rebuild the OfflineDB, and also confirm whether the CDC sync mechanism of the new OfflineDB is functioning properly.
Experimenting with CDC Consumer Switching to New Topic
The existing PG 9.6 Primary uses pg2pulsar to send logical decoding messages to the pulsar topic: dcard_api. It is important to note: if after switching to the new PG 11 Cluster, we also send new logical decoding messages to the same topic via pg2pulsar, the LSN of the two PGs will be mixed in the same topic, making it difficult to perform subsequent rollback. And our goal is not to affect the existing architecture, so we decided that the new PG 11 Primary will send logical decoding messages to the new pulsar topic: dcard_api_11.
In addition, by monitoring the existing CDC consumers, we found that they can consume all the messages in the topic during the past early morning hours. This way, we can quickly switch the CDC consumers to listen to the new topic after upgrading to PG 11. It should be noted: when consumers create pulsar subscriptions, they will by default fetch the latest messages from the topic and will not replay previous messages. However, after we upgrade to PG 11, we will immediately open it to client-side writes. Therefore, we need to manually create subscriptions for all current CDC Consumers on the new topic and set their cursors to start fetching from the earliest message. This way, we can ensure that CDC Consumers can consume all messages from the new topic.
Rehearse the Complete Upgrade Process
Once all the previous testing and rehearsal steps have been verified to be error-free, we conduct a rehearsal of the upgrade process by setting up a replica of Dcard’s current architecture in the production environment. Every rehearsal is recorded, and we review the recordings afterwards to identify and address issues in the process, such as refining the upgrade scripts or ensuring that downtime stays within the 10-minute window.
During these upgrade rehearsals, we discovered a critical issue: our current CDC (Change Data Capture) architecture cannot handle sequences. Due to inherent limitations in logical decoding, we can only get the new value of each column. The CDC sync then directly updates or inserts this new value into the corresponding table. As a result, the last value of the sequence cannot be updated. If we allow clients to write to the PG 11 cluster, errors such as unique constraint violations will occur due to the auto-increment feature. To resolve this issue, we use a script to query all columns using the sequence feature and correct the last value.
Upgrade Steps
Below, I’ll walk you through each step of the entire upgrade process.
Create a PG 9.6 Primary using Disk Snapshot.
To facilitate the in-place upgrade and disk partitioning planning, we start by cloning a PG 9.6 Primary machine.
Here are the detailed steps:
- Create a Disk Snapshot of the production environment’s PG 9.6 Primary and use it to generate a PG 9.6 Primary machine.
- Take note of the latest Checkpoint LSN after PG 9.6 recovery to facilitate CDC Sync with the PG 11 Cluster from this point.
- Install PG 11 on this machine.
- Use pg_upgrade to perform an in-place upgrade.
- Use VACUUM FULL to clean dead tuples and release disk space.
Note that this process will take several hours due to the VACUUM FULL operation.
Establish a New PG 11 Cluster
As the PG 11 machine prepared earlier still uses a single disk, we first need to set up a new PG 11 Primary machine with the appropriate boot disk, data disk, and archive disk configurations. Then, we can simply copy the data portion from the prepared PG 11 machine to the new PG 11 Primary using pg_basebackup.
Detailed steps are as follows:
- Use pg_basebackup to transfer the data from the temp PG 11 Primary to the new PG 11 machine.
- Configure postgresql.conf based on the specifications of the PG 11 machine.
- Create the required physical replication slots for each replica.
- Manually initiate a checkpoint to flush the current WAL buffer to disk.
- Quickly establish multiple Replicas using disk snapshots of the PG 11 Primary, and set up streaming replication accordingly.
- Set up pulsar2pg on the PG 11 Primary and fill in the previously recorded PG 9.6 checkpoint. This will allow CDC sync with the PG 9.6 Cluster to start from the correct LSN breakpoint.
After setting up the CDC sync, you can use Grafana to monitor the progress of backlog consumption for the corresponding pulsar topic subscriptions through the pre-configured dashboard. This will give you a clear view of the CDC sync status.
Switching from PG 9.6 Cluster to PG 11 Cluster
Here are the steps for switching from PG 9.6 Cluster to PG 11 Cluster, translated into English:
- Set up a firewall to block any external connections to the PG 9.6 Primary.
- Terminate all existing connections to the PG 9.6 Primary, and wait a few seconds.
- Create a marker table on the PG 9.6 Primary as the final write. Ensure that the PG 11 Primary receives this final write, indicating that both sides are fully synchronized. Additionally, due to limitations in logical decoding, the latest value of the sequence cannot be updated, so a script is run on PG 11 to update the sequence-related fields.
- Stop the pg2pulsar on the PG 9.6 Primary and start pulsar2pg. Also, start pg2pulsar on the PG 11 Primary to continue synchronization between the two clusters, facilitating future rollbacks.
- On the PG 11 Primary, drop the previously created marker table as the last write, and ensure that the PG 9.6 Primary also drops the marker table, indicating that both sides can synchronize normally.
- Redirect all services connecting to the PG 9.6 Cluster to the PG 11 Cluster, allowing users to start writing to the new PG 11, and ending downtime.
- Create a disk snapshot of PG 11 and rebuild a new OfflineDB for OLAP services to connect to the new OfflineDB.
- Ensure that all existing CDC consumers have consumed all messages from the old topic and recreate subscriptions for each consumer on the new topic. Set the cursor to start consuming from the first message of the topic, then redirect all existing CDC consumers to the new topic.
Additionally, to ensure the smooth transition of the upgrade process, we have pre-set dashboards in Grafana to monitor the affected services. The relevant metrics include:
- The status and replica count of the K8S pods for each service.
- The success and fail rate of crucial APIs.
- The pulsar backlog quantity and acknowledgment rate of the new and old OfflineDB and CDC consumers.
Finally, the actual switching and upgrading process resulted in a write downtime of approximately 8 to 9 minutes.
Rollback Plan
After the upgrade and switch, these two clusters will continue to synchronize. Even if a rollback is necessary, you can simply follow the upgrade and switch steps mentioned above.
Note: If you intend to switch the CDC consumer back to the old topic, it’s necessary to manually create a cursor table on the PG 9.6 Primary beforehand. This cursor table serves the purpose of helping us locate the cursor position within the old topic. Resetting the cursor through this table prevents the CDC consumer from encountering issues with consuming duplicate messages.
Further detailed steps are omitted here.
Conclusion
The entire migration process is not something readily achievable. We need to:
- Research all feasible upgrade and rollback scenarios, analyzing their pros and cons in conjunction with our current Infra structure, to determine the strategy that best aligns with our upgrade goals.
- Conduct multiple rounds of experimentation and rehearsal, recording each session and identifying areas for improvement.
- Coordinate with the operations and development teams to set a definitive upgrade schedule.
- Continuously monitor each component before the switch to ensure each phase proceeds smoothly before the formal transition.
Ultimately, there are still manual confirmation steps involved in the migration process. We will continue refining the migration process and strive to minimize downtime as well as the time taken for OfflineDB and CDC consumer reconstruction.
Furthermore, given the performance enhancements made between PG 12 and PG 15, we will also continue planning for future upgrades. We look forward to the opportunity to share related content with everyone in the future.