Programming Language Memory Models - 筆記
今天分享這篇文章的筆記,主要內容是在講現在常見的程式語言的 memory model 的內容是什麼,因為我對 c/c++ 也很久沒碰了,所以可能我會理解錯誤,再歡迎指教。
再來回顧這個例子:
1 | // Thread 1 // Thread 2 |
在沒有做任何同步的操作,這個例子會出現以下的問題:
- Thread 2 可能永遠都不會停止卡在 while loop 裡面,因為編譯器的優化策略可能會將 done 變數在首次使用的時候存在 register 中,並且盡可能長時間的使用該 register,因此 Thread 2 存取到的 done 變數都會是相同的值,當然也不會注意到 Thread 1 後來修改 done 變數的值的操作。
- Thread 2 也是有可能會跳脫 while loop,但是 print x 還是有可能會是 0。因為編譯器優化策略通常會在不影響程式運行結果的前提下將程式進行重新排序 (reorder) 來提高執行效率,所以 done = 1 可能會變成在 x = 1 之前,所以 Thread 2 有可能會讀到 x = 0 的結果。
如何解決同步問題
在程式語言常見的方式提供 atomic variable 及 atomic operation 的方式,讓 thread 之間可以進行同步,如果 done 是 atomic variable:
- Thread 1 編譯後的程式碼要保證在寫 done 之前的寫 x 操作必須先完成且其他 Thread 是可以看到 x 的寫入結果
- Thread 2 編譯後的程式碼必須在每次 while loop 會重新讀取 (拿取) done 最新的值
- 因為有上面這兩條的限制,所以編譯器就必須禁止相關重排優化策略
這樣的方式就像是讓程式可以用 sequentially consistent 的方式執行,上篇我們提到 DRF-SC 同步模型,程式語言等同於做這件事情。
而不同的程式語言有不同的實作方式去避免編譯器重排的問題,以下的問題是需要去克服或者說程式語言要去回答的,讓我們 programmer 能夠更清楚該語言的實作方式可以避免怎樣的情境:
- What are the ordering guarantees for atomic variables themselves?
- Can a variable be accessed by both atomic and non-atomic operations?
- Are there synchronization mechanisms besides atomics?
- Are there atomic operations that don’t synchronize?
- Do programs with races have any guarantees at all?
Hardware, Litmus Tests, Happens Before, and DRF-SC
來看上篇文章給的例子:
1 | Litmus Test: Message Passing |
在現代的程式語言的編譯器使用重排策略是有可能導致 r1= 1, r2 = 0 的。
而現在處理器通常都因為效能考量不採用 sequentially consistent,而保證有 DRF-SC 的屬性,要做到這樣的屬性,就必須提供特定指令是可以讓 thread 彼此之間建立 happens before 關係。
happens before 關係
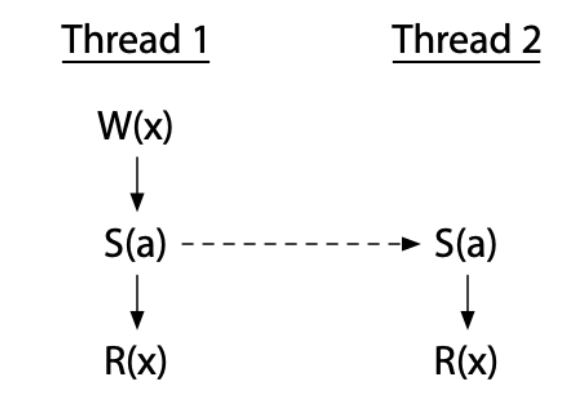
假設 S (a) 是同步指令,透過 Thread 1 與 Thread 2 利用 S (a) 建立了 Thread 1 到 Thread 2 的 happens before 關係,代表 Thread 1 W (x) 會發生在 Thread 2 的 R (x) 之前,這樣就不會有 data race 的出現。這邊的 data race 定義為對同一個變數的寫操作與對同一變數的寫操作或讀操作同時執行,就會發生 data race。
這樣就是提供類似 DRF-SC 的同步模型的效果,也是現代的程式語言提供的基本保證,來讓我們 programmer 更好的寫 multi-thread programs。
Compilers and Optimizations
來看個例子:
1 | Litmus Test: Coherence |
-
由於編譯器的 reorder 的策略,使得一致性可能還會比 ARM/POWER 還弱:
1
2
3
4// Thread 1 // Thread 2 // Thread 3 // Thread 4
// (reordered)
(1) x = 1 (2) r1 = x (3) r4 = x
(4) x = 2 (5) r2 = x (6) r3 = x如果按照上面的 order 就會得出
r1 = 1, r2 = 2, r3 = 2, r4 = 1 -
但是編譯器的這種 reorder 方式在 single thread 反而是好的,例如:
1
2
3
4
5if(c) {
x++;
} else {
... lots of code ...
}編譯器為了省略更多 if else 來增進效率,可能會將程式碼改成這樣:
1
2
3
4
5x++;
if(!c) {
x--;
... lots of code ...
}但是如果在 multi-thread 中,當 c 為 false 的時候, x 就很有可能會被其他 thread 做更改。
之後就是介紹 Java, c, c++, JavaScript 等等的這些語言的 memory model 怎麼去定義怎樣的編譯器的優化策略是可以的什麼是不行的,來幫助我們寫好 multi-thread programs。
Original Java Memory Model 1996
Java 是第一個試圖寫下 multi-thread 保證的程式語言,透過 volatile 或是 mutex 避免 data race,但是在 1996 的第一版卻有著缺陷,一起來看看吧。
Atomics need to synchronize
volatile atomic variable 是 non-synchronizing,來看個例子:
1 | int x; |
因為 done 被聲明為 volatile,thread 2 的 while loop 會結束,但是 print x 不能保證會 print 1,因為編譯器沒有禁止重新排序對 x 和 done 的 access,在這種 case 下一致性太弱了。
Coherence is incompatible with compiler optimizations
會遇到 mandating coherence 問題,也就是強致一制性的意思,一但 Thread 讀取了 new value of memory address,就不能在讀取 old value,看個例子:
1 | // p and q may or may not point at the same object. |
根據這段程式,編譯器會採用常見的優化策略叫做:CSE (Common subexpression elimination),編譯器會視情況將多個相同的表達是替換成一個 variable,這個 variable 會儲存著計算該表達式所得到的值。
例如:
1 | a = b * c + g; |
可以觀察到 b * c 這邊是兩項表達式中的 CSE,如果計算這個子表達式並將其計算結果存儲起來的開銷,低於重複計算這個子表達式的開銷,則能夠將以上程式碼轉換成以下程式碼:
1 | temp = b * c; |
再回過頭看我們最初的例子,編譯器可能會優化成 k = i。但是如果這時候 p 和 q 是 reference 相同的 object,並且另外一個 Thread 在讀入 i 跟 j 的之間向 p.x 進行寫入,那麼 k 就會用到舊值的 i,這樣違反了前面說的強制一致性的意思。但是如果禁止這樣的優化,會讓許多的編譯器產生的程式碼效率變慢,且因為這個是基本的優化不太能捨棄。
這邊可以知道在面對這樣的情況,hardware 會比編譯器更容易解決這樣的問題,因為 hardware 可以根據給定的 memory 讀寫的序列中涉及的 address 來明確調整優化的 path,也叫做 dynamic optimizations,但是編譯器只能使用 static optimizations,無論涉及怎樣的 memory address or value,都只能提前寫出正確的 instruction sequence,所以編譯器不能輕易根據 p 和 q 是否剛好指向同一個 object 而去改變優化策略,只能特地為這種情況去設計但是這樣就會導致有不少 time and space overheads。
New Java Memory Model (2004)
由於 1996 的版本有許多問題,在 2004 年出現新的 memory model,在 Java 5.0 中採用。提供的同步操作有:
- Thread 的建立發生在它的第一個動作之前
- mutex 的 unlock 要發生在 lock 之前
- volatile 的變數的寫入要發生在讀取之前
這邊的三個概念牽涉到到一個名詞,那就是 subsequent ,指的是較晚發生的意思,因為這些同步操作會定義整個程式中所有操作的 total order,這些 total order 會決定先後順序,這就造成了所謂的 happen before 的關係,有了 happen before 的關係就能定義這樣的執行是否有 data race。
Synchronizing atomics and other operations
來看個例子:
1 | Litmus Test: Store Buffering |
- 對於 volatile 變數 x 跟 y,讀取和寫入的行為不能被 reorder
- 對同一個變數的寫入,第二個寫入一定會看到第一個寫入的結果
這邊要注意的是:
同步操作中的不同 mutex lock 或是 volatile 變數的訪問順序並沒有 happen-before 的關係,只有對同一個變數的寫入 / 讀取,才有所謂的 happen-before 的關係。
Semantics for racy programs
這樣的 memory model 提供了以下的好處:
- 支持 Java 的 security 及 safety guarantee
- 讓 programmer 更容易發現錯誤
- 使攻擊者更難利用 data race 的方式造成損失
- 讓 programmer 可以根據這樣的 memory model 去理解程式是會怎麼運行的
所以相較於 1996 的版本,不再強調強一致性,而是善用 happen before 的概念來決定 read /write 的順序,避免 data race。
具體規則就是:
- 對變數 x 的讀取時必須能夠看到對 x 某一次寫入所儲存的值
- 如果讀取 r 可以觀察到對 x 寫入的 W,那麼 r 就不會發生在 w 之前,所以 r 可以觀察到所有發生在 r 之前的所有寫入,也可以知道與 r 競爭的寫入。
但是對於定義 data race program 的話,用 happen-before 仍然是有問題的,我們接下去看。
Happens-before does not rule out incoherence
來看個例子:
1 | // Thread 1 // Thread 2 // Thread 3 |
假設 Thread 1 和 Thread 2 的寫入動作是在 Thread 3 開始之前完成,由於兩個 Thread 的寫入是透過不同的 mutex 所以彼此是有競爭關係的,而 Thread 3 讀取 x 是在獲取兩個 mutex 的,由於兩者的寫入 happen before 在 r1 之前,這兩個寫入不應該會有 overwrite 的行為存在,所以以 Java Memory Model 理論來看,r1 = x, r2 = x 是可以讀取到不同的 value 的,因為 Java Memory Model 沒有規範到這種行為。
而實際上運行的時候不會產生不同的 r1 和 r2,但是以這個論點去看待,Java Memory Model 理論有其缺陷。

另外這邊還探討的問題是:由於編譯器的優化策略可能會將 x = r1 將 r2 = x 視為相同,所以省略成 r2 = x,再加上 r1= x 整個優化策略可能就變成:r1 = r2,但是以剛剛我們說的問題,應該是會讀到不同值,但是因為優化策略導致 r1 跟 r2 會都是相等的。所以整個看下來你可以說編譯器這樣的優化策略會跟 Java Memory Model 有 conflict,使得不會採取這樣的優化策略。
我猜作者是想表達這件事情。
Happens-before does not rule out acausality
1 | Litmus Test: Racy Out Of Thin Air Values |
在這個 happen-before 的理論中,無法假設上面的 program 跑出來不會有 r1 = 42, r2 = 42 的情況,因為會類似這樣的概念去跑:
- S(Store) 1 predicts that L1 will read 42 and then speculatively writes 42 to y,
- L(Load) 2 reads 42 from y into r2,
- S2 writes 42 to x, and
- L1 reads 42 from x into r1, thereby making the initial prediction “correct.”
然後也可以想成編譯器的策略將程式碼變成以下這樣:
1 | // Thread 1 // Thread 2 |
還有個例子:
1 | Litmus Test: Non-Racy Out Of Thin Air Values |
Happen-before 不排除 r1 = x 這段沒有 not-quite-write 指的是可能讀到不完整的寫入或是未初始化的值或是錯誤的預測值,而 c++ 其實也有說明這樣的行為:
1 | Implementations should ensure that no “out-of-thin-air” values are computed that circularly depend on their own computation. |
什麼是 memory_order_relaxed,後面提 c++ memory model 會在講到。
但是不管怎樣 DRF-SC 的定義是確保上面的程式最後都只能看到全 0,然後在 happen-before 的理論下這就是會出現的缺陷。
C++11 Memory Model (2011)
接著我們來看看 C++11 在 Java 先出來的 memory model 後,c++11 的 memory model 又有什麼不同呢?主要是以下兩點:
- c++ 對具有 data race program 不做任何 guarantees,所以 memory model 可能不像 Java 那麼複雜
- c++ 提供三種原子性的特性:
- 強同步 (順序一致)
- 弱同步 (acquire/release, coherence-only)
- 無同步 (relaxed)
因為帶入 relaxed 的概念,使得 c++ memory model 反而加深了複雜性,但是對於 programmer 設計 multi-thread 的幫助更小,此外還有帶入了 memory barrier 操作可以使用。
DRF-SC or Catch Fire
C++ 對於任何有 data race program 都屬於 undefined behavior,允許程式在執行的最初幾微秒就有可能發生 data race,進而導致長時間的錯誤行為,這種行為通常稱為 DRF-SC or Catch Fire:如果 program 沒有 data race,則以順序一致的行為運行,如果有 data race,會出現任何出乎意料的事情,就叫做 Catch Fire。
之所以給出這樣的結論,主要是基於以下這四個論點:
- C/C++ 因為編譯器優化策略的關係,到處都有 undefined behavior,多一個又有什麼差呢?(我覺得英文的意思是這樣翻的… 應該算是自嘲?)
- 現有的 compiler 或是 library 在設計的時候沒有考慮到 multi-thread 的情況,要修復這樣的情況太難了,不知道怎麼對付 relaxed atomic 的行為
- programmer 明白自己在寫什麼 code (?),那你可以使用 relaxed atomic 來試試看
- 不去定義 race semantics,並使用 detect and diagnose races and stop execution。作者認為 (或者是說希望) 意思是說,允許使用 detect race tool 來去發現 data race,而不是說一個整數的 data race 就會使整個程式無效。
來看個例子:
1 | unsigned i = x; |
-
c++ 編譯器會將 i 存在 register 上,但是如果 foo: 這邊的程式碼很複雜,則需要使用 register 的值,但是不會 將 i 的值轉移到
function stack 上,編譯器可能會在到下面 switch 之前,再次從 global x 讀取 i,那沒有可能在 if 中的 i < 2 的條件可能不再成立。
加上編譯器 jump using a table indexed by
i,這個 index 可能會到一個意外的 address。
C++ 的 memory model 作者說:任何有 race 的 access 都允許對程式的未來執行造成損害,該篇文章作者表示:在 multi-thread 中,編譯器不應該認為它們可以透過重新執行初始化局部變數的 memory 讀取來重新加載像 i 這樣的局部變數,想要指望 c++ 專門針對 single thread 的世界並修復這樣的問題可能是不切實際的,但是在新的語言 (想指 Go),可以有更遠大的目標。
Digression: Undefined behavior in C and C++
另外 C and C++ 充斥太多 undefined behavior ,就會導致許多 data race,例如:
1 |
|
如果你用 Clang 的現代編譯器進行編譯,程式會這樣跑:
- main 函式中, Do 要麼為 null or EraseAll
- 如果 Do 是 EraseAll,那麼 Do () 與 EraseAll () 的作用相同
- 如果 Do 是 null,那麼 Do () 是 undefined behavior,compiler 表示我可以隨心隨遇的實現 (?),包括直接拿 EraseAll () 作為實現
- 所以可以間接調用 Do () 變成直接調用 EraseAll ()
- 最後變成 inline EraseAll ()
1 | int main() { |
補充到底何謂 undefined behavior 跟 unspecified behavior
undefined behavior
程式的行為並未在語言規範中,就是語言規格在定義時會為了編譯器實作的彈性和效率考量,不去定義某些 spec,所以當成是寫出了 undefined behavior 則編譯器可能編譯時會發生各種可能,有可能無法編譯,或是執行不正確而產生不正確的結果,或是剛好按照 programmer 心裡所想的意圖去執行
來看個例子:
1 | int i = 10; |
C 語言沒規定 i++ 或 ++i 的「加 1」動作到底是在哪個敘述的哪個時刻執行,因此,不同 C 編譯器若在不同的位置 + 1,就可能導致截然不同的結果。
再來看個經典例子:
1 |
|
這是有關於費馬最後定理:
$$
n >= 3, x^n + y^n = z^n
$$
找不到正整數解。
但是當你用 clang 編譯器去編譯的時候會發現居然會推翻費馬最後定理,這是為什麼呢?因為編譯器優化策略的關係。它的 assembly code 會長這樣:
1 | fermat(): # @fermat() |
可以發現 main 程式那邊,不會呼叫 fermat (),而是直接 ouput “Fermat’s Last Theorem has been disproved.\n”,居然直接把 fermat () 這段 code 省略掉了。
fermat () 這邊會變成這樣:
1 | bool fermat() { |
主程式變成這樣:
1 | int main() { |
最後 c++ standard 有提到這件規範:
Here’s the relevant part of the C++ standard:> 6.9.2.2 Forward progress [intro.progress]> The implementation may assume that any thread will eventually do one of the following:
— terminate,
— make a call to a library I/O function
— perform an access through a volatile glvalue, or
— perform a synchronization operation or an atomic operation.
That loop doesn’t ever do any of the second through fourth things, and if it didn’t return true, then it would never terminate either, so Clang is allowed to assume that it will eventually return true. And since the loop doesn’t have any other effects visible outside the function, it can be optimized away entirely.
最後程式碼就被簡化成這樣:
1 | int main() { |
真是有趣又難以理解的現象啊!
Unspecified behavior
指的是標準沒有明確規定、也不要求每個 C++ implementation 必須在其文檔中明確規定的行為。但是標準會規定一組可能的行為,unspecified behavior 的具體運行時行為只能是這一組可能的行為中的一個或多個。
例如最簡單的例子是:fun1() + fun2() 的求值順序,是先呼叫 fun1 函數還是先呼叫 fun2 函數,這件事情本身是 unspecified behavior。
Acquire/release atomic
在 c++ 中也有提供 atomic 的使用方式,類似於 Java 的 volatile 用法,例如:atomic<int> done;
或者是也可以這樣使用:atomic_store(&done, 1); and while(atomic_load(&done) == 0) { /* loop */ } 來做存取已經讀取的操作。
而關於原子操作的部分,其實還有提供一個可選參數做使用,那就是可以指定 memory_order 來控制,目前的類型如下:
1 | typedef enum memory_order { |
如果是上面的用法,預設都是採用 memory_order_seq_cst,這種 memory 排序會有兩個保證:
- 程式指令與程式碼順序一致
- 所有 thread 的所有操作存在一個 total order。
在这種模型下,每個 thread 的所有操作先後關係,所有 thread 都是可見的。
較弱的原子操作可以使用 acquire/release 的方式:
- 如果一個 release 被後來的 acquire 觀察到,那麼就建立了一個 happen-before 的關係
- release 之前執行的寫入必須對後續的 acquire 之後執行讀取可見,就像是 unlock mutex 之前執行的寫入必須對後來 unlock mutex 之後執行的讀取可見一樣,恩… 一樣的饒口
來看 C++ 標準說寫的會比較清楚:
An atomic operation A that performs a release operation on an atomic object M synchronized with an atomic operation B that performs an acquire operation on M and takes its value from any side effect in the release seqeunce headed by A.
- 同一個對象中的 atomic operation 不允許被亂序
- release 操作禁止了所有在它之前的讀取寫操作與它之後的寫操作亂序
- acquire 操作禁止了所有在它之前的讀取操作與在它之後的讀寫操作亂序
使用方式如這樣:atomic_store(&done, 1, memory_order_release); and while(atomic_load(&done, memory_order_acquire) == 0) { /* loop */ }
那麼前面順序一致原子操作跟 acquire/realease 原子操作差別在哪呢?
- 順序一致的原子要求程式中所有的原子行為與執行的 total order 一致,但是 acquire/realease 原子不會遵守
- acquire/realease 原子只需要對單個 memory address 的操作進行順序一致的交替執行,也就是說只需要一致性
所以 acquire/release 可能會無法觀察到程式中所有 acquire/release 原子的顺序一致的交替行為,因此會造成 data race,而違反了 DRF-SC。
1 | Litmus Test: Store Buffering |
- 因為 acquire/release 原子在 x 的順序和 y 的順序之間沒有去做規範
- 因此 r1 = y 可能會跟 x = 1 交換順序, r2 = x 也會跟 y = 1 交換順序,而這樣的話 r1 = y 與 y = 1 誰先發生就不一定了,因此會造成 r1 = 0 跟 r2 = 0 的結果發生。
- 這邊我想再講得更清楚一點,因為 x 跟 y 都是 acquire/release 原子的前提下,無法適用前面 C++ 標準說的後兩點亂序的問題,因為沒有去做規範。
我們再來看個例子:
1 | class Cond { |
如果採用順序一致的原子操作,則並發調用 notify 和 wait 不會導致 notify 立即返回並且 wait sleep 的情況發生。但是如果使用 acquire/release 的話,有可能會發生這樣的問題。
最後作者這邊有提到在 ARM 架構下實現 acquire/release 原子的方式是使用順序一致原子的方式,所以可能這個程式你在 ARM 架構跑都不會有問題,但是移植到其他架構才會發現出錯,另外是覺得 acquire/release 取名不好,因為順序一致也是做類似的動作。
Relaxed atomic
relaxed atomic 可以說根本沒有同步的效果,也沒有順序保證,跟普通的讀取跟寫入沒有區別,只有保證單個原子的操作不會有 data race 而已。
1 | Litmus Test: Non-Racy Out Of Thin Air Values |
以這個例子來看,C++ 規範保證當 x 和 y 是普通變數時,程式必須給 x = 0 and y = 0 的情況結束,但是如果 x 和 y 是 relaxed 的原子,則 C++ 規範不排除 r1 跟 r2 最終都可能達到 42 的可能性。
而其實這樣的問題就是著名的 The Thin-air Problem,因為 Thread 2 可能會被編譯成這樣:
1 | r2 = y.load(mo_relaxed); |
這樣你可以說兩者的程式碼意思是一樣的,然後經過重排就可能導致 r1 = 42, r2 = 42 的情況發生。
但是要注意的是真的在硬體上跑不會有出現這個結果,是這個 relaxed 造成了這樣的結果,可以說是理論導致有任意值的存在,所以這邊作者才會指出這邊有缺陷。
最後這邊作者想表達的應該是定義 concurrency semantics 這件事情很困難,想出來的 memory model 理論要避開上面這些缺陷,且要明確指出什麼情況會遇到這些問題是很困難的 (?),真的有點難懂,但我猜要表達的是這件事情。
C, Rust and Swift Memory Models
C11 也是採用 C++11 內存模型,而 Rust 1.0.0 和 Swift 5.3 也是,擁有 DRF-SC or Catch Fire 的特性,因為這兩個語言都是建立在 LLVM 的 tool chain 上,並且與 C/C++ 程式碼十分耦合。
Hardware Digression: Efficient Sequentially Consistent Atomics
這邊作者提到,因為早期的處理器各自有自己的同步機制及 memory model,為了在每個處理器架構實現順序一致的行為,通常只能使用到 memory barriers,但是這種的 cost 會比較高,尤其是 ARM/POWER 架構上。但是隨著程式語言都提供了這種順序一致的抽象層,硬體也需要提供相對應的支持才可以。
因此 ARMv8 的架構下引入了 LDAR (Load-Acquire) 及 STLR (Store-Release 指令,是一種單向的 memory barrier,不像雙向的 memory barrier 那麼強順序一致。
- LDAR:這條指令之後的所有 load & acquire 的操作不會被重新排序到這條指令之前,但是沒有要求不能排在之後。
- STLR:這條指令之前的所有 Store & Release 的操作不會被重新排序到這條指令之後,但是沒有要求不能排在之前。
LDAR 與 STLR 的搭配來實現了 C++ 的 Sequencial Consistent memory order,關於其他處理器的指令 mapping C++ 的關係可以參考這個網頁:https://www.cl.cam.ac.uk/~pes20/cpp/cpp0xmappings.html
JavaScript Memory Model (2017)
恩… 終於結束 C/C++ 的探索,不得不說真的有點硬,還看組語我的天啊。
接著來介紹 JavaScript 的 Memory Model。
JavaScript 雖然是 Single thread 但是還是會遇到 data race 的問題,但是這邊不是討論的範圍。而是 JavaScript 推出 web workers 之後,就會遇到 Multi-Thread 的問題。
Web Worker 介紹
什麼是 Web Workers 呢?
這個要從網頁 UI 開始講起,因為如果網頁 UI 遇到需要計算密集的事件,畫面就會卡住不動,這時候使用者體驗就會很差,而 web worker 相當於就是將計算密集的工作交給另外一個 Thread 去做,而主要的 Thread 則是負責 UI 的操作,當 web worker 做好事情後就會通知 main thread。
這不是代表 JavaScript 支援 Multi-thread,而是瀏覽器提供環境讓 JS 可以多跑一個 JS 程式來執行,而且要看瀏覽器是否有支援才能使用:https://caniuse.com/?search=webworker
1 | const first = document.querySelector('#number1'); |
這個是個簡單的範例,來自於 MDN。透過建立 worker const myWorker = new Worker("worker.js");,其中可以要給可以運行 js 檔案,接著可以 main thread 可以透過 postMessage 的方式將資料傳過去給 worker,而 main thread 透過使用 onmessage 可以收到 worker 丟過來的資料。
接著來看 worker.js 的程式碼:
1 | onmessage = function(e) { |
worker 本身也可以定義 onmessage 來收到 main thread 丟過來的資料並且進行自己的邏輯,再一樣透過 postMessage 與 main thread 進行溝通。而 Node.JS 則提供了 worker_threads module 可以用,是類似的功能的。
那回過頭來講,為什麼會有 data race 呢?原因在於 main thread 與 worker thread 的溝通方式的進行。
再講之前,先介紹 JS 當中的 ArrayBuffer,ArrayBuffer 是一種表示通用、固定大小的原始二進制資料緩衝,想要直接操作一個 ArrayBuffer 物件的內容是不可能的。若要讀寫該緩衝的內容則必須透過視圖,可以選擇建立一個 DataView 視圖物件或是一個限定其成員為某種型別的 TypedArray 視圖物件,它們皆能以特定的型別解讀、修改 ArrayBuffer。這邊有興趣可以直接去看 MDN 的介紹。
使用範例如下:
1 | var buffer = new ArrayBuffer(8); |
Web Worker 與 main thread 的溝通方式
-
在預設的情況下 Web Worker 與 main thread 不會共享 memory,而前面我們提到用 postMessage 通訊的方式,其實是直接透過複製的方式過來的,也就是 postMessage 傳遞的資料會進行序列化,再發送給 webWorker,接著反序列化在存到 worker 的 memory,所以其實是直接複製一份資料過來的意思。
想當然這樣的 cost 跟效率會比較低。
-
第二種方式就是 ArrayBuffer 的改編,那就是 SharedArrayBuffer,當然就是兩個 thread 共享同一塊 memory 來進行資料讀取和寫入,所以就會遇到 data race 的問題,因此提供了 原子操作 來進行同步。
回過頭來看文章,JavaScript 的 memory model 與 C++ 差別在於:
- 原子操作只有順序一致的方式,正確性提高,效率當然會降低
- JS 不採用 DRF-SC or Catch Fire 的規則,反而像 Java 一樣有仔細定義了 data race 發生的各種情況,但是允許 data race read 的時候可以 return 任何值,可能會導致 private data leak 的問題:https://github.com/tc39/proposal-ecmascript-sharedmem/blob/main/DISCUSSION.md#races-leaking-private-data-at-run-time
- 有定義當原子和非原子操作在同一個 memory address 使用時會發生什麼問題
這邊有提到 ES2017 因為 ARMv8 的原子指令與 JS memory model 不一致造成 data race,理論上 ARMv8 有 LDAR 及 STLR 指令,應該能夠提供順序一致的原子 store & acquire 的。
來看個例子:
1 | Litmus Test: ES2017 racy reads on ARMv8 |
在 C++ 中 sequential conistent 是可以 r1 = 0, r2 =1 的,因為 x = 2 本身可能會 reorder 到 y = 1 前面。在 Java 中沒辦法寫成這樣,因為 volatile 的變數就只能原子訪問,不能有時候非原子有時候走原子。在 JS 當中反而會變成,如果 r1 = y 是讀取到 0,那麼 thread 1 就必須在 thread 2 開始之前完成,在這種情況下,x = 2 的操作只能發生在 x = 1 之後並且覆蓋 x 的值,因此 r2 = x 會讀取到 2,所以不會發生上面的情況。
但是這樣的行為 ARMv8 的指令行為有牴觸,因此有提到修復這個問題:“Repairing and Mechanising the JavaScript Relaxed Memory Model.”,不確定是不是已經修復了。
再來還有個 bug 例子:
1 | Litmus Test: ES2017 data-race-free program |
在順序一致的情況,因為 if 條件成立是 == 1 ,那麼會形成一個 happen before 的關係, x = 1 一定會在 r1 = x 之前,那麼 r2 = 2 就不可能會發生。
作者這邊表示不確定 C++ 會不會出現這樣的行為,恩… 如果是以 C++ sequencial consistent 的行為去看,感覺應該是不會出現吧 (?)
至於 ES2017 卻會出現這種情況,不過錯誤應該已經是被改正了。
總結
終於到了結論,說真的我查了文件跟資料,還是覺得真的滿抽象的。
這邊作者有總結一些結論:
- 這些語言都有提供順序一致的原子操作
- Java 和 JavaScript 沒有引入類似 C++ acquire/release 這種弱原子的操作,所以少了 C++ 那些的問題
- C++, Rust, Swift 都提供 relaxed 的機制,但是在 Java 和 JavaScript 中就沒有提供類似的操作。
- 沒有任何語言可以證明自己的理論可以不會出現 The Thin-air Problem,但是所有語言都非正式的不允許這樣的行為 (?),應該就是說理論上會出這樣的缺陷,但是實現上會去不允許發生這樣的行為。
最後我個人認為作者一直想強調的是,要有一個厲害的 memory model 且說明所有的 data race 發生的可能以及如何去避免並證明自己的理論是沒有缺陷的是很難的,而作者也期望未來的發展可以 formalize entire memory models,讓我們可以更理解 memory model 的行為。
要真的深入了解,真的難 Orz