Hardware Memory Models - 筆記
今天分享這篇文章的相關筆記,該文章的作者也是主要 Go 的 contributor 其中之一。這篇文章主要是介紹硬體記憶體模型有什麼類型以及其差別。作者這系列的文章總共有三篇,前面兩篇都算是鋪陳第三篇的 Go 的記憶體模型設計,所以透過前兩篇文章先講講硬體記憶體模型是什麼及區別,第二篇是講講其他語言的記憶體模型設計為何。
在以前寫 single-threaded programs 的時代
在以前的年代,大家都還在只能寫 single-threaded programs 的時候,當下一代的硬體或是編譯器升級後,要怎麼判斷程式有沒有性能上的提升呢?
如果 programmer 無法判斷硬體升級前後的程式執行結果有什麼差別,那麼這個硬體的升級就是有效的。
我認為講白的就是,硬體升級後,如果速度上有提升,且執行結果沒有差別,就斷定硬體的升級是有效的。
當 multi processor 的時候來臨
隨著時代的演進,multi-processor 來臨後,我們開始可以寫 multi-thread 程式,這時許多在 single-threaded programs 看不到的問題就會產生了,無法再用以前的方式看待程式性能是否有提升,因為如果沒解決 multi-thread 會出現的問題,你的執行結果可能就會跟以前不同!
來看個例子:
1 | // Thread 1 // Thread 2 |
問題:Thread 2 有可能 print 0 嗎?
- 根據硬體及編譯器才能決定是否會出現這種結果
- 如果是 x86 且採用逐行轉成 assembly language,會 always print 1
- 如果是 ARM or POWER 且一樣採用逐行轉成 assembly language 會有機會 print 0
- 但是不管底層硬體是什麼,編譯器的優化策略也會導致有 print 0 或是進行無限 loop 的可能
之所以會有多種運行結果產生,是因為對 memory 裡面的資料存取或更改的策略不同導致的結果,也就所謂的可見性及一致性,因為不同的硬體架構下,處理器對於 memory 的策略會不同,而這種策略,我們就叫做 memory model。
memory model 的分類
在最一開始 memory model 來自於硬體對於操作記憶體的概念,這時候還沒有所謂的編譯器的參與。而之後幾年開始有了編譯器之後,那 memory model 就可以分為硬體或軟體的 memory model
- hardware memory model
- 可以理解硬體 (其實也就是處理器) 與 memory 操作的協議,說明什麼情況的可見性及一致性怎麼發生
- software memory model
- 由於在程式語言及編譯器的出現後,編譯器會有所謂的優化策略,可以將每一行程式碼進行重排來獲得更好的執行效率,這時候對於 memory 的存取就會有其可見性及一致性需要規範,這些機制來告訴 programmer 要怎麼寫 code
而 memory model 又根據一致性區分出強一致性與弱一致性的類型,所以這篇文章主要要著重於 hardware memory model 強與弱的類型介紹。
Sequential Consistency
Sequential Consistency 來自於 Leslie Lamport 1979 年的論文《How to Make a Multiprocessor Computer That Correctly Executes Multiprocess Programs》:
The customary approach to designing and proving the correctness of multiprocess algorithms for such a computer assumes that the following condition is satisfied: the result of any execution is the same as if the operations of all the processors were executed in some sequential order, and the operations of each individual processor appear in this sequence in the order specified by its program. A multiprocessor satisfying this condition will be called sequentially consistent.
直白來說就是:所有處理器的操作都是按某種順序執行的,每個處理器的操作都是按程式指定的順序出現的,滿足這一條件的多處理器系統將被稱為順序一致 (Sequential Consistency) 的。
而這樣的順序一致的方式也是符合 progammer 的寫程式的直覺,因為就是程式碼按照我們寫的一行一行依序去執行,不會有重排的問題發生。而在 multi-thread 上,sequential consistency 保證不同 thread 的執行方式只是以某種順序來進行交替 (interleaving),而不是以其他方式排列。
來看個例子:
1 | Litmus Test: Message Passing |
- Litmus Test 代表測試只有兩種答案,這個運行結果是可能還是不可能發生。
- 這個例子中,假設沒有編譯器的優化策略干擾,每一個 thread 的指令就是處理器要執行的指令。
如果是 Sequential Consistency 會出現六種可能的交替執行結果:
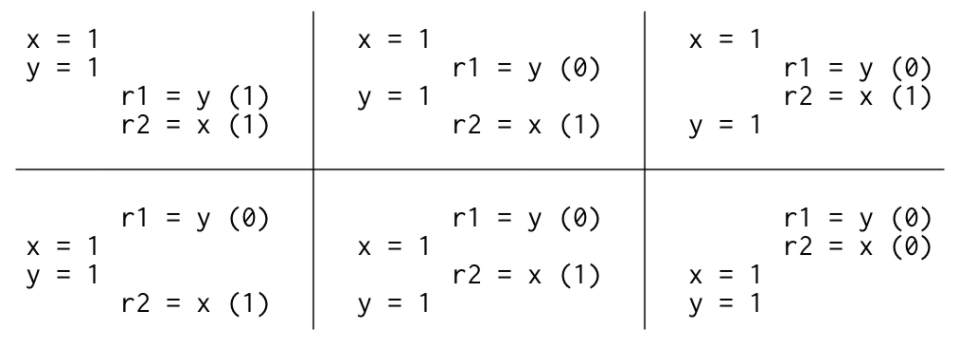
根據這樣的結果得知:r1 = 1 , r2 = 0 是不可能發生的。
Sequential Consistency 的實現方式可以想像是所有處理器共享一個 shared memory,它可以一次處理一個 thread 的 read or write,不涉及 cache,因此每個處理器需要讀取或寫入 memory 時,該請求都會到 shared memory,一次使用一次的 shared memory 對所有 memory 存取的執行添加了順序,所以導致了 Sequential Consistency,看圖會更理解:
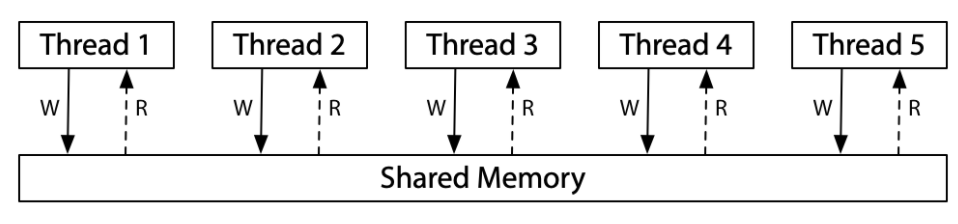
但是夢想是美好的,現實是殘忍的,要實現這樣 Sequential Consistency 並不容易,而且最大問題是同一時間只有 single thread 可以存取 memory,這樣的方式削弱 multi-processor 的幫助。因此現今的硬體都不是走 Sequential Consistency 來提升性能。
總結 Sequential Consistency:
- 程式的執行順序按照程式碼順序
- 程式碼中對於記憶體的訪問不會被亂序
x86 Total Store Order (x86-TSO)
x86 的 memory model 如下圖:
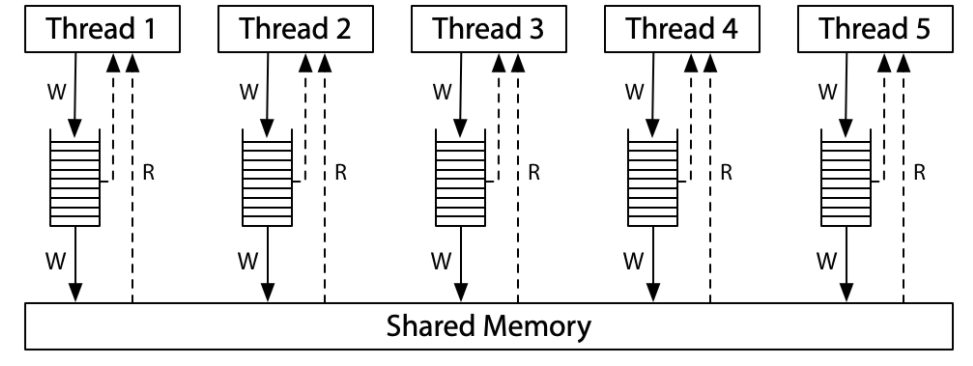
- 所有處理器仍然共用 shared memory
- 每個處理器對 memory 的 write 放到 local write queue 中後,繼續執行新指令,而 queue 中的 write 操作也會更新到 shared memory
- 一個處理器的 memory 讀取順序會先讀 local write queue,但是看不到其他處理器的 local write queue,這樣變成當前處理器會比其他處理器會先看到自己的 write 操作。
- 而 Total Store Order 來自於:所有處理器都保證寫入 (等同於 store 的概念) 到 shared memory 的 total order。
- 當一個 write 操作到達 shared memory 時,任何處理器上的未來 read 操作都將看到它並使用該值,除非它被之後 write 操作覆蓋,其他處理器才會採納 new value。
- write queue 是 first-in-first-out 策略,所以處理器執行的順序就等於 shared memory 存 write 的順序
那麼再來看前面的例子:
1 | Litmus Test: Message Passing |
-
因為 write queue 保證 thread 1 在 y 之前就將 x 寫入 memory 了,而 thread 2 是先讀 y 再讀 x,是不可能再看不到新的x之前就能看到新的 y,說起來饒口就是了。
這些順序就是 Total Store Order 的保證:thread 1 在寫入 y 之前先寫入 x,因此 thread 2 在看到 x 的寫入之前不可能看到 y 的寫入。
那麼 Sequential Consistency 與 Total Store Order 的差別在哪呢?來看個例子:
1 | Litmus Test: Write Queue (also called Store Buffer) |
-
在 sequential consistency 的情況,
x=1或y=1必然先發生,且另外一個 thread 讀取的時候就必定能夠觀察到這賦值,所以r1 = 0andr2 = 0不可能發生 -
但是在 TSO 的情況下,thread 1 和 thread 2 可能會將它們的 write 操作在 queue 中排隊,因為如果還沒進入到 shared memory 之前,其他 thread 就開始讀取的話,這樣兩個 read 操作都會看到 0
-
這種需要用到兩個同步變數常常出現在知名的同步算法中,例如:Dekker’s algorithm or Peterson’s algorithm。
- 為了滿足上面這種演算法並提供更強的 memory order,非 sequential consistency 通常會提供稱為 memory barrier 的指令用來控制順序:
1
2
3
4// Thread 1 // Thread 2
x = 1 y = 1
barrier barrier
r1 = y r2 = x- 透過 memory barrier 的幫助, 保證在關鍵時刻可以強制順序一致的方法,至於 memory barrier 具體細節會依據不同處理器的架構而不同。
再來看個例子:
1 | Litmus Test: Independent Reads of Independent Writes (IRIW) |
- 如果 thread 3 在 y 之前就看到 x 的變化,那麼 thread 4 可以在 x 之前就先看到 y 的變化嗎?
- 對於 sequentially consistent and x86 (or other TSO) 都是不可能看到的,因為對於 shared memory 所有的寫入都有一個 total order,所有處理器都會認同這個 order,因此當 thread 3 確定了 x 先於 y 的 order,thread 4 就不可能能夠相反的看到 y 先於 x 的 order,每個處理器只有在到達 shared memory 前可以先知道自己的寫入而已。
x86-TSO 坎坷之路
這邊主要作者提到 x86-TSO 的發展不順的歷史,例如第一批的 x86 處理器的手冊幾乎沒有提到硬體提供的 memory model 是怎樣操作的,因此常常開發人員被 local write queue 的不期望的行為所困擾,並且當時 intel 架構人員不願意為未來的處理器做出任何保證,其手冊中存在的少量文本幾乎沒有任何保證,使得很難針對它們進行 coding。
在 2007 年 8 月出版的 Intel 64 Architecture Memory Ordering White Paper,終於提出了:" 提供軟體工程師對不同順序的 memory 存取指令可能產生結果的各種情況 “。而 AMD 在 [AMD64 Architecture Programmer’s Manual revision 3.14](https://courses.cs.washington.edu/courses/cse351/12wi/supp-docs/AMD Vol 1.pdf) 中發表了類似的描述。
然而這些描述反而是提出了 TLO (Total Lock Order) + CC (Causal Consistency) 模型,提供一致性比 TSO 還弱:
intel 架構師表示,TLO+CC “像要求的那樣強大,但並不足夠強大。”
並且在 Litmus Test: Independent Reads of Independent Writes (IRIW) 居然會產生這樣的可能,且 memory barrier 不夠厲害,不足以可以達到 sequential consistent 的效果。
此外,x86 TLO+CC 模型也無法達到以下的實驗:
1 | Litmus Test: n6 (Paul Loewenstein) |
- 說實在這個實驗我不是看很懂,為什麼前兩個 model 會是 no,QQ 看來只能再問問公司的大神了
在 2008 年 intel 和 AMD 修訂規範並保證了 IRIW case 的 “不”,並加強了 memory barrier,但仍允許不可預期的行為:
1 | Litmus Test: n5 |
為了解決上面問題,Owens et al. 在早期 SPARCv8 TSO 模型的基礎上提出了 x86-TSO 模型提案。並聲稱:
“To the best of our knowledge, x86-TSO is sound, is strong enough to program above, and is broadly in line with the vendors’ intentions.”
A few months later Intel and AMD released new manuals broadly adopting this model.
所以可以知道 intel 和 AMD 花了不少時間:
how to write a memory model that left room for future processor optimizations while still making useful guarantees for compiler writers and assembly-language programmers. “As strong as required but no stronger” is a difficult balancing act.
說實在我覺得有些英文句子很難翻譯 ==,就這樣吧… 總而言之花了不少時間來達到真正的 TSO model。
ARM/POWER Relaxed Memory Model
前面的 Sequential Consistency 跟 TSO 都是屬於偏強一致性的,那麼就來講講比較弱一致性的 memory model,主要是用在 ARM/POWER 架構上的處理器上。
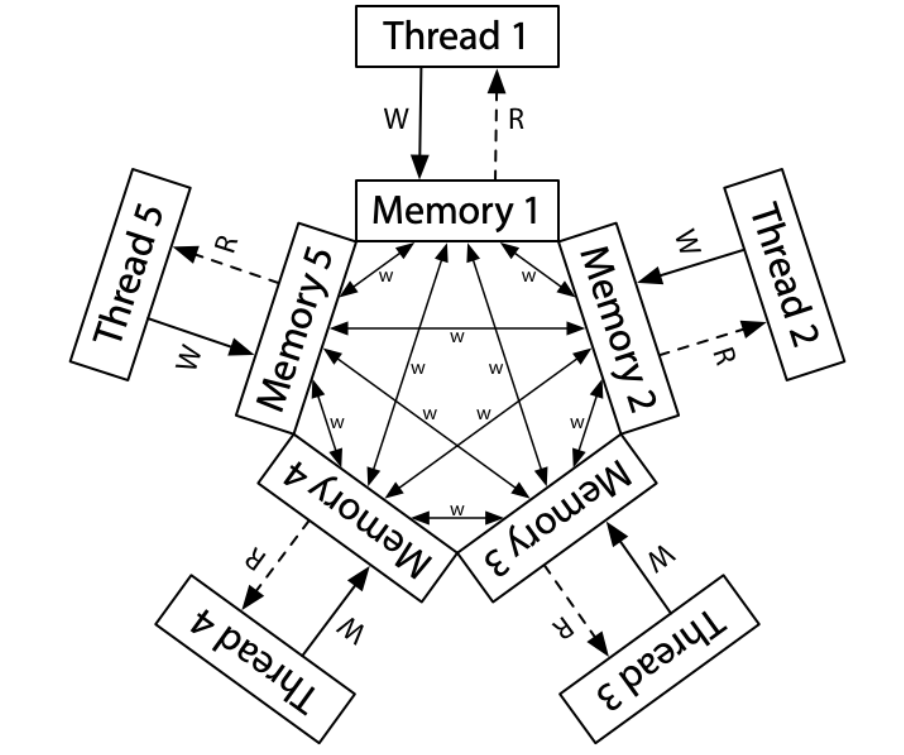
-
每個處理器都只對自己的 complete copy of memory 進行讀取及寫入,而寫入的結果也會傳播到其他處理器的 memory copy 上,由於寫入的傳播不固定所以允許重新排序,因此這邊沒有所謂的 total store order
-
每個處理其也被允許可以 postpone a read until it needs the result,延遲讀取的意思,當前 read 的 code 可以延遲到之後的 write 之後,所以上面的 litmus test 都是有可能發生的
1
2
3
4
5
6
7
8Litmus Test: Message Passing
Can this program see r1 = 1 , r2 = 0 ?
// Thread 1 // Thread 2
x = 1 r1 = y
y = 1 r2 = x
On sequentially consistent hardware: no.
On x86 (or other TSO): no.
On ARM/POWER: yes!- 想像 thread 1 and thread 2 有自己獨立的 memory copy,write 可以以任何順序在 memory 之間傳播,所以 thread 1 的 x 的更新傳播有可能是在 y 的更新傳播之後,並且 thread 2 在這兩個更新傳播進行讀取就會看到
r1 = 1andr2 = 0的結果
- 想像 thread 1 and thread 2 有自己獨立的 memory copy,write 可以以任何順序在 memory 之間傳播,所以 thread 1 的 x 的更新傳播有可能是在 y 的更新傳播之後,並且 thread 2 在這兩個更新傳播進行讀取就會看到
-
再來看一些例子:
1
2
3
4
5
6
7
8Litmus Test: Store Buffering
Can this program see r1 = 0 , r2 = 0 ?
// Thread 1 // Thread 2
x = 1 y = 1
r1 = y r2 = x
On sequentially consistent hardware: no.
On x86 (or other TSO): yes!
On ARM/POWER: yes!這種情況會與 TSO 的行為一致。
1
2
3
4
5
6
7
8
9Litmus Test: Independent Reads of Independent Writes (IRIW)
Can this program see r1 = 1 , r2 = 0 , r3 = 1 , r4 = 0 ?
(Can Threads 3 and 4 see x and y change in different orders?)
// Thread 1 // Thread 2 // Thread 3 // Thread 4
x = 1 y = 1 r1 = x r3 = y
r2 = y r4 = x
On sequentially consistent hardware: no.
On x86 ( or other TSO): no.
On ARM/POWER: yes!這種情況只有 ARM/POWER 才會發生。
1
2
3
4
5
6
7
8
9Litmus Test: Load Buffering
Can this program see r1 = 1 , r2 = 1 ?
(Can each thread 's read happen after the other thread' s write ?)
// Thread 1 // Thread 2
r1 = x r2 = y
y = 1 x = 1
On sequentially consistent hardware: no .
On x86 ( or other TSO): no .
On ARM/ POWER : yes!剛才說過 read 可以延遲後做,所以也會導致這種情況發生。
而 ARM 和 POWER 也有 memory barrier,可以在上面的例子中插入這些 memory barrier,來達到強制順序一致的行為,但是有什麼情況是都不會發生的呢:
1 | Litmus Test: Coherence |
之所以會這樣是因為:threads in the system must agree about a total order for the writes to a single memory location.
也就是說 threads 對於單個變數的 memory location 改變順序要同意一致,所以 thread 3 看到了 r1 = 1, r2 = 2,看到了 x 變化順序是 1 => 2 所以 Thread 4 也必須看到同樣的變化順序才可以,這樣的性質叫做 coherence ,如果沒有這個性質,處理器有可能不同意 memory 儲存的最終結果或是 report a memory location flip-flopping from one value to another and back to the first.
這邊我還是有點難以理解根據傳播的不同,為何不會發生上面的情況,還是就是強制有 coherence 的特性呢?QQ
Weak Ordering and Data-Race-Free Sequential Consistency
在硬體的 memory model 下產生了各種各樣的可能,因此這邊就有人提出所謂的同步模型:
Sarita Adve 和 Mark Hill 在 1990 年的論文 “Weak Ordering – A New Definition” 中提出 “weak ordering” 定義為如下:
Let a synchronization model be a set of constraints on memory accesses that specify how and when synchronization needs to be done.
意思是說,同步模型是對 memory access 的一種約束,這些約束指定了何時以及如何進行同步
其中一種同步模型叫做:data-race-free(DRF)
假設硬體擁有 memory 同步操作,這些同步操作可以將 memory 的 read and write 進行重新排序,有點像是說可用來做重新排序的 memory barrier
來看個例子:

兩個 thread 彼此之間會有 race condition 是對於 x 的 write 操作,thread 2 與 thread 1 的寫入和讀取競爭,而如果 thread 2 是讀取 x 則代表 thread 1 的寫與 thread 2 讀之間只有一個競爭。
為了避免 race condition,加入了同步操作:
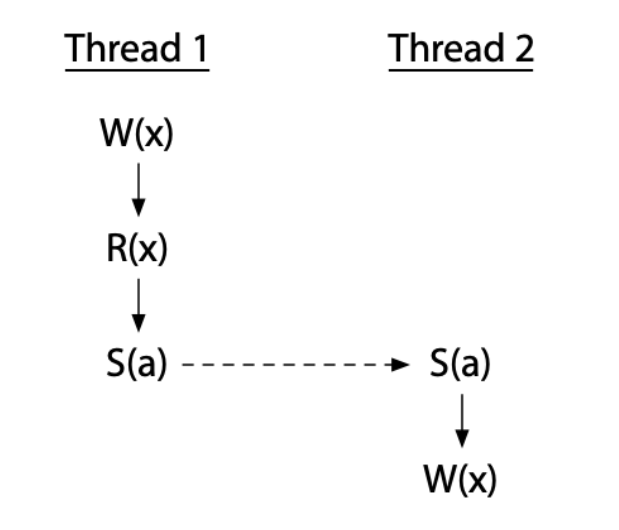
強制 thread 2 W (x) 在 thread 1 R (x) 之後,就不會有 race condition
如果是 thread 2 只是 R (x),則改成這樣:
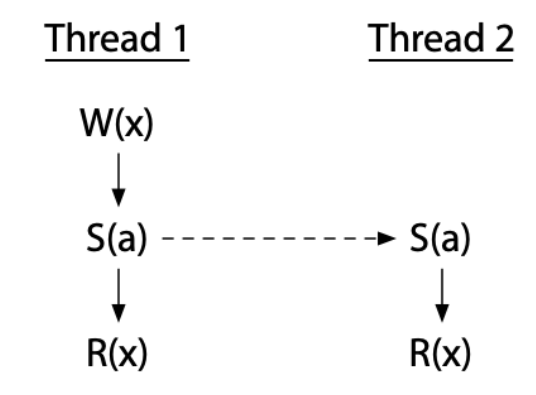
同步操作也可以利用中間的 thread 來達到:
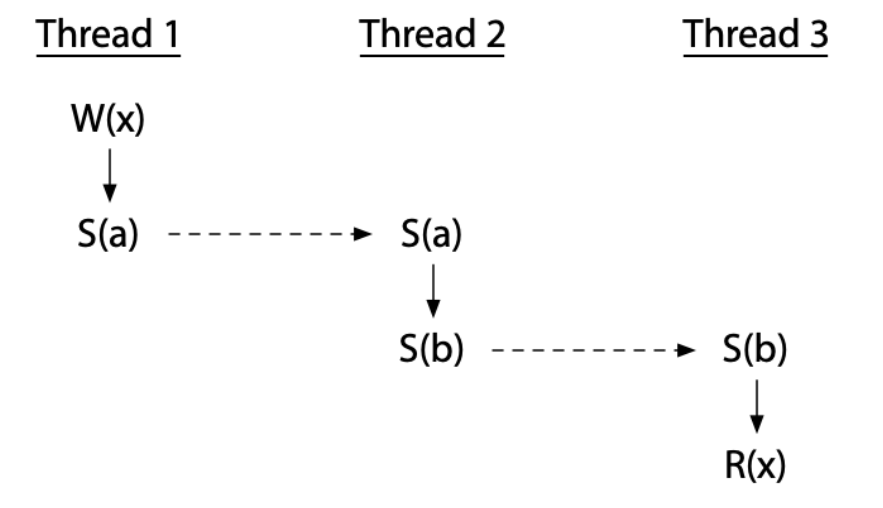
如果誤用同步操作還是會造成 race condition:
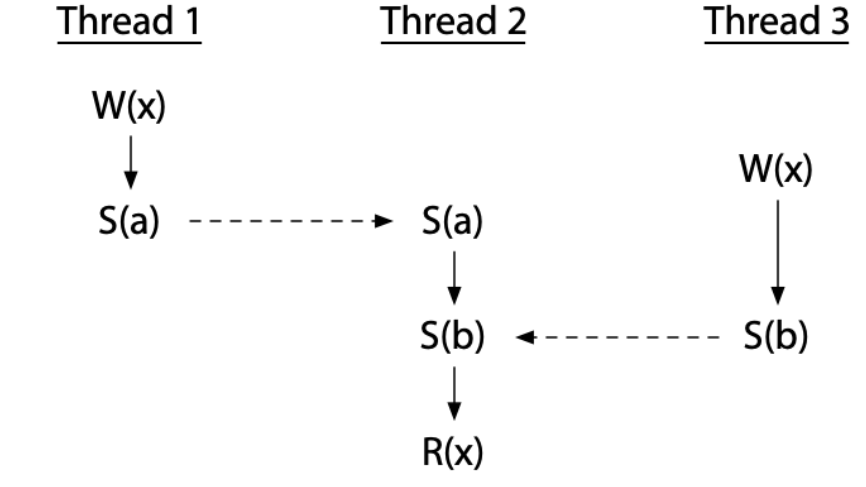
thread 1 與 thread 3 的 W (x) 沒有經過同步,所以不是 data-race-free
這種 weak ordering 的性質可以想成是硬體和軟體之間的協議方式,也就是說我們如果軟體可以解決 race condition,那麼硬體就相當於是跑 sequential consistency 的樣子。
因此之後的硬體會實作這些同步操作來讓我們這些軟體工程師來使用,就是這樣的道理!這種觀點也叫做:DRF-SC(data-race-ree sequential consistency)
作者之所以要提這個觀念,是因為下篇文章就是講現在的程式語言的 memory model 的原理是怎麼做的,其實這就回歸我們前面說的概念那就是 software memory model。只要硬體能夠滿足軟體同步操作的實作,那麼只要軟體工程師的 software memory model 做得好,或者應該說讓編譯器的優化策略照著你想要的走,那麼就不會有 race condition。
總結
這篇文章說實在我覺得有點抽象不是很好理解,我自己也是看了不少篇文章來理解,我也不確定我理解的對不對,對我來說 memory model 就是一種協議的感覺,並且根據硬體跟軟體拆成兩種性質的 memory model,一個是硬體與 memory 寫入 / 存取,一個是編譯器對於 memory 的優化策略之類的,可能會重組我們寫好的程式碼,來提升性能,而程式語言本身也會提供給我們一些同步操作來避免 race condition,這些同步操作會迫使編譯器編譯成機器碼的時候去做相對應的轉換,相對的硬體也必須支援這樣的操作才行。
而 memory model 又區分為強 / 弱一致性,而會讓硬體處理上產生各種不同的運行結果。
以上是我的理解,歡迎指教。