Postgres - 一文看懂 physical replication 及 logical replication 概念
今天這篇文章,是因應公司讀書會整理出來 Postgres 從 physical replication 到 logical replication 的相關概念。從歷史演化來看,並且理解 backup & recovery 概念後,再來理解何謂 physical replication,而 physical replication 本身功能已經發展多年,從 PG 10 開始發展 logical replication 並且到 PG 15 這之間做了不少 logical replication 的加強。
Replication 發展時間軸
Postgres 9.0:streaming replication (asynchronous)
在 9.0 的時候推出 asynchronous streaming replication
PostgreSQL 9.1:pg_basebackup、streaming replication (synchronous)
在 9.1 的時候推出 pg_basebackup 可以拿來做備份或是快速建立 standby,並且支援 synchronous stream replication
PostgreSQL 9.4:replication slot、logical decoding
在 9.4 推出 replication slot 擺脫 archive_command, restore_command 來處理 replica 重啟跟不上 primary 的問題,並且 logical decoding 的支援可以讓我們 listen logical decode event 並且延伸出 logical replication 的應用。
PostgreSQL 9.6:multi synchronous standby
開始支援可以多個 multi synchronous stream replication
PostgreSQL 10:
正式支援 native logical replication
PostgreSQL 11, 12, 13, 14, 15:
幾乎都是對 logical replication 功能的改進,在 14 的時候支援 pgoutput plugin 可以 binary format 在 15 的時候有所謂的 row filter 的功能,可以選擇符合 row filter 的 row 需要 logical replication。
Backup And Recovery
WAL
在一個 transaction 中,每一次 DDL 或是 DML 操作,會將對應操作的紀錄 WAL record 記錄到 WAL buffer,當 transaction commit 後,這些 WAL buffer 會被 flush 到 WAL file,所以可以保證 ACID 的 D 部分,當 restart 後可以拿來做 redo 操作,因應這種特性可以拿來做 backup 以及 recovery。
所衍生出來的 Continuous Archiving 概念:每一個 WAL files 被放在 pg_wal 資料夾裡面,max_wal_size 跟 min_wal_size 可以控制 wal file 裡面保留的量可以多少,舊的會被定期清空。
WAL file 切換:
- WAL file 寫滿 (16MB)
- 執行 pg_switch_xlog () or PG 10 之後改用 pg_switch_wal ()
- 啟動 archive_mode,並且超過 archive_timeout 的值
- 如果 PG 產生 WAL 的量很少,或是產生 WAL 的週期很長,會導致事務完成到成功 archive 備份成功,會有很大時間上的延遲,因次可以設置 archive_timeout 來強制切換到新的 WAL file,這樣舊的 WAL file 就會被觸發 archive。時間差是跟上次切換新 WAL file 去計算的。如果設定太短,會導致強制切換 WAL file,但是提早關閉的 WAL file 大小還是會跟完整的 WAL file 大小一樣,所以會佔用大量的儲存空間
如果想要回放更舊的資料,就必須對 WAL 進行備份,也就是 Archive 的概念,透過以下參數可以控制 archive:
1 | archive_mode = on |
- archive_command 可以放置 bash 指令,例如將 wal 檔案 backup 到其他 disk
- restore_command 可以放置 bash 指令,例如讀取 backup 的 wal 檔案進行 recovery
- %p 參數代表 wal file 的位置
- % f 代表 wal file name
如果 WAL file 準備要被 archived,PG 會在 pg_wal/archive_status 加入 .ready 在副檔名代表該 file 準備好被 archive,而副檔名是 .done 則代表已經成功被 archived
1 | ls pgtest/pg_wal/archive_status/ |
當 PG 執行下一個 checkpoint 的時候會將 .done 的 files 清掉,不會讓 status file 無限生長。
LSN 概念
LSN 是一個 64 bit 的 integer,代表的是 WAL 裡面的 position, 64 bit 可以分為 high 32 bit 跟 low 32 bit
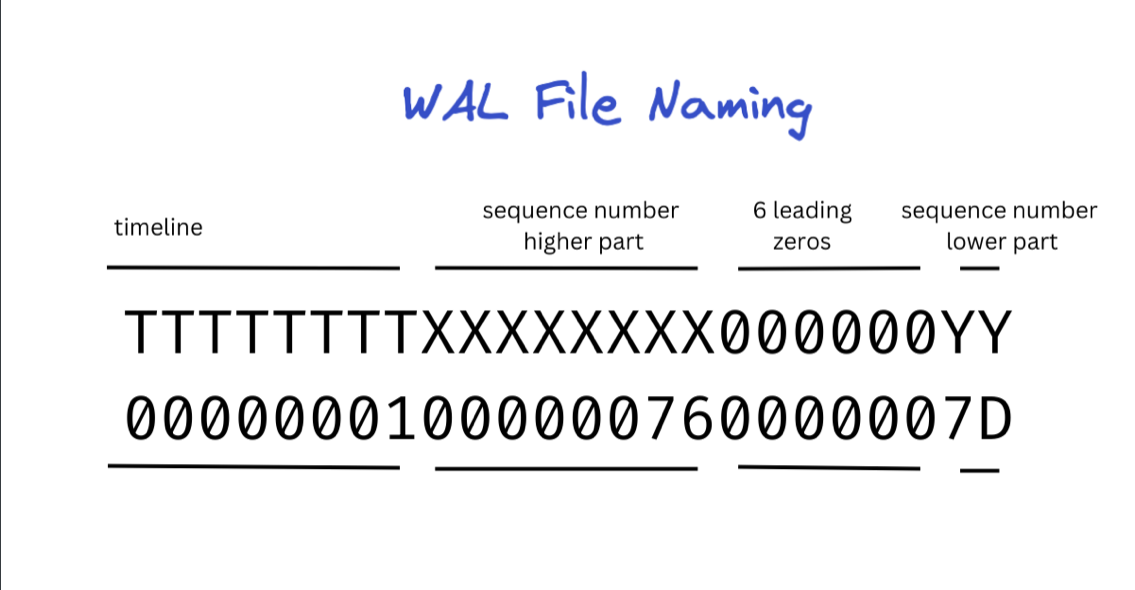
在 PG 內部會用 16 進位表示我們常看到的形式:XXXXXXXX/YYZZZZZZ
X 代表的是 high 32 bit,Y 的部分是 high 8 bit of low 32 bit,Z 則是代表 offset point of file
X 跟 Y 的值被用來表示 wal file name 的後半部分,例如:TTTTTTTTXXXXXXXXYYYYYYYY,T 代表 timeline 部分:
pg_current_wal_insert_lsn ():代表當前要插入的 location
pg_current_wal_lsn ():代表已經被成功寫入到 wal buffer 的 location
pg_current_wal_flush_lsn ():代表已經被成功 flush 到 disk 的 location
pg_current_wal_flush_lsn < pg_current_wal_lsn < pg_current_wal_insert_lsn
1 | postgres=# set synchronous_commit = off; |
1 | postgres=# set synchronous_commit = on; |
1 | postgres=# select pg_walfile_name('76/7D000028'); |
Physical Replication
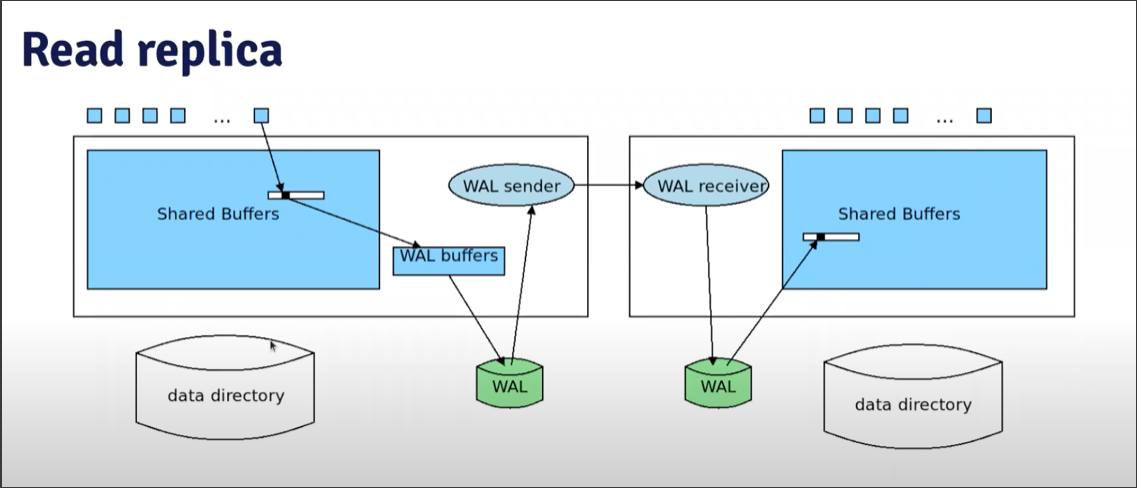
-
Replica 需要先對 Primary 發起 IDENTIFY_SYSTEM 請求,用來確認彼此的關係:
-
在 Postgres 11 (含) 之前要設定 primary_conninfo 在 recovery.conf,在 Postgres 12 (含) 之後要設定 primary_conninfo 在 postgresql.conf,也可以透過 pg_basebackup 的話可以自動產生 recovery.conf (PG11) or postgres.auto.conf (PG12) 並自動填上 primary_conninfo,同時在 PG 12 後也會自動的建立 standby.signal 在 pgdata 上代表這個 Replica Server 是 hot standy。
-
怎麼確認這個 Primary 就是我的真的 Primary 呢?利用的是 IDENTIFY_SYSTEM,這個是透過 Postgres initdb 的指令來的,每一次資料要初始化之後都會分配一個唯一的 database system identifier,Primary 與 Replica 的 database system identifier 必須要相同的,他們才能認識對方,也才能組成一個 Cluster。
所以在跑 pg_basebackup 之前也先將 Replica Server 之前的 pg data 先全部砍掉,其中的原因就是要確保 database system identifier 必須跟 Primary Server 一樣。
-
-
當 Replica 與 Primary 互相確認完身份後,這時候 Replica 就會發送 START_REPLICATION 請求,內容是 Replica Server 想要獲取的 LSN ,Primary 會看是否存在,如果不存在,就會給出錯誤訊息,Physical Replication 就會失敗:
- Replica 因為 shut down 而重啟後會無法連接上 Primary,因為 Primary 已經將之前的 LSN 對應的 WAL 資料刪掉了,導致 Replica 無法追趕這之間的資料落差。
- Primary 有大量的寫入,Replica 還來不及與 Primary Server 同步完資料,Primary 就把 WAL 刪掉了,因為同樣的 Replica 無法追趕這之間的資料落差
要解決以上兩個問題: archive_command 結合 restore_command 或是 replication slot
replication slot 概念
前面提過 archive_command 的執行時機,但是如果還是需要保證資料能夠 real time 的備份:
使用 pg_receivewal,打開 replication connection 並且透過 streaming 的方式持續將 WAL 送到你指定的地方,預設的情況是異步的,切換同步的話,會變成每次 commit 都要等待 pg_receivewal 做完才可以,會降低資料庫的速度
1 | pg_receivewal -h mydbserver -D /usr/local/pgsql/archive |
而 pg_receivewal 的做法就是在 Postgres 上開一個 replication slot,來進行 streaming 的輸出 WAL 的動作。
而 replication slot 是儲存 pg 內部的 data structure 並且 binary format 的存到 pg_repslot 資料夾,replication slot 本身的資料結構會被 wal_sender 來進行更新:
當 replica 透過 update standby status 的時候會傳過來 restart lsn 的資訊,並且更新到 replication slot,pg 就會根據 replication slot 的 restart lsn (pg_replication_slots) 去決定 WAL 要不要保留,因此:
- 確保 Primary 保留足夠的 WAL 供所有副本接收它們
- Primary 只有在事務日誌被 all replica 使用後才能回收
缺點: Primary 的 WAL file 可能會一直累積,建立大量沒有使用的 replication slot 或是 Replica 一直無法追上,會造成 disk 用量增加。
failover
通常 physical replication 需要遇到的 failover 的問題通常都是 primary 壞掉,需要緊急透過 promote 來將 replica 變成 primary,promote 觸發方式有兩種:
-
pg_ctl promote
-
trigger file
trigger_file=‘/pgdata/.postgresql.trigger.2019’`
這時候會觸發 replica 變成 primary 的機制,可以透過檢查 pg_controldata 或是檢查:
1 | postgres=# select pg_is_in_recovery(); |
當 replica 變成 primary 的時候,舊的 primary 有可能這時候突然有新的寫入進來,這會導致舊 primary 如果要變成 replica 重新接上 primary 會遇到 timline 分歧的問題:
1 | FATAL: requested timeline 2 is not a child of this server's history |
這時候就需要透過 pg_rewind 來進行回放到正確的 timeline,但是要回放就需要有之前的 WAL 紀錄,可以透過 restore_command 並接著跑 pg_rewind:
1 | pg_rewind --target-pgdata=data --source-server="port=5433 user=postgres dbname=postgres" |
conflict
primary 有 vacuum 正在執行,此時 replica 剛好遇到 long-running 的查詢,導致 primary 給 replica 的 WAL 會有衝突到,這時候會等待 max_standby_streaming_delay (預設 30s),如果查詢還沒結束,會中斷 replica 的 connection:
1 | FATAL: terminating connection due to conflict with recovery |
這時候要避免這種情況,可以例如 HOT_STANDBY_FEEDBACK,replica 會透過 HOT_STANDBY_FEEDBACK 將當前最小事務 id (Xmin) 定期告知 primary,延遲 primary 做 vacuum 操作
但是也會導致 primary 的 dead tuple 變多,如果 replica 常常有 long-running 事務 以及 primary DML 又很頻繁,會很容易導致 table bloat 的速度變快,建議還是要用 offline 的方式去跑 long-running
Logical Replication
logical decoding concept
- Decode WAL 資料來取得 DML changes,透過接收這種 changes 你可以拿到相關的資料
- 這些 changes 會根據 commit 的順序進行排序,並且可以 streaming 出去
- receiver 可以去收這些 streaming changes 就可以選擇傳給下游的 external consumers,透過這種概念來實作自己的 logical replication。而官方提供的 publish & subscribe 的 logical replication 機制是在 10 推出,因此在 10 之前就有透過這樣的方式來實現 logical replication,例如知名的 pglogical,那比 9.4 更早的版本則是會透過 trigger event 來實現,例如知名的 slony。
- unlogged and temp table 不會被 decode
- DDL 無法被 decode,只會 decode 出空的 transaction change
logical replication slot
-
當 primary 做了任何的 DML changes 就會將對應的 LSN 紀錄在 logical replication slot 上。一個 primary 裡面可以有包含多個 logical replication slot,通常一個 logical replication slot 只會被一個 replica receiver 所接收。
-
透過帶上
replication=database參數,讓 PG 知道該連線是關於 replication connection 的連線。 -
接著你可以對 PG 送
IDENTIFY_SYSTEM命令,PG 會給你當前Xlogpos,也就是當前 WAL 的 flush location,receiver 就可以這個位置開始拿之後的 WAL 資料,而 receiver 的 identifier 如果不符合對應的 replication slot 的 identifier 就無法成功開始 replication 機制。 -
receiver 的實際運作流程會是:
-
setup replication conn
-
create replication slot 這邊要帶上要使用哪個
logical decoding plugin name,而如果已經建立的話,則判斷 pg error code 不等於42710,這邊可參考 PostgreSQL Error Codes例如:
1
SELECT * FROM pg_create_logical_replication_slot('logical_slot', 'test_decoding');
在 primary 的 postgresql.conf 需要設定
max_replication_slots > 0跟wal_level = logical。 -
identify system
-
start replication 這邊要帶上當前的
Xlogpos、replication slot name、還要對應的logical decoding plugin 的相關參數 -
stream receive changes
-
send changes to external consumers
-
logical decode plugin
- The change output format 是由 plugin 來決定的,可以設定 binary or text format
- native plugin 有 test_decoding (測試用),pgoutput (用在 native logical replication)
- wal2json:顧名思義是 decode 成 json 的格式,屬於第三方的套件
- pglogical_output:這個是來自於 pglogical 實現 logical replication 的 decode plugin,實作類似於 pgoutput
- logical decoding interfaces:
- SQL:pull for changes, function calls 例如
SELECT * FROM pg_logical_slot_get_changes('myslot', NULL, NULL);,主要拿來做 testing /debugging - Streaming Replication:changes are pushed
- SQL:pull for changes, function calls 例如
replica identity 概念
透過 ALTER 每一個 TABLE 的 Replica Identity 的值去設定說有什麼資訊要寫入 WAL Log 來去識別是 update /delete 哪一個 row,而 Replica Identity 有以下四種 mode:
- DEFAULT:記錄該舊 row 的 pk 去識別要 update /delete 哪一個舊 row,只有當更新 pk 的值,才能拿到 pk 的 old value,其他欄位的值都是當作 new value 的。預設非 system table 都是採用這種 mode。
- FULL:可以拿到所有 column 的舊值,會更花空間及資源。
- USING INDEX index_name:記錄該舊 row 的 index 去識別 update /delete 哪一個舊 row,因此該 index 必須是 unique 的 且 not null,如果該 index 被刪掉,那行為會變成是 NOTHING Mode。只有當更新 index column 的值才能拿到 index 欄位的 old value,其他欄位的值都是當作 new value 的。
- NOTHING:無法拿到要所有要更新 column 的 old value,預設是 system table 都是採用這種 mode。
而 toast 欄位因為 column 本身的資料過大,postgres 會選擇將其資料存在另外一個 table 上,如果在 Default mode 的情況下,除非是更新對應的欄位,才會將 new value 帶過去,不然 new value 也會是空的,而 old value 一樣不會帶過去。要解決這個問題一樣是透過開啟 full mode 才會帶上 toast column 的 old value 過去。
1 | postgres=# CREATE TABLE t (a int primary key, b int, c int); |
pgoutput
1 | typedef struct OutputPluginCallbacks |
實作的 source code:https://github.com/postgres/postgres/blob/master/src/backend/replication/pgoutput/pgoutput.c
PluginArgs 必須根據你所使用的 plugin 去給,以我們要用的 pgouput 到底該給什麼值,可以先來看 PG 文件:https://www.postgresql.org/docs/current/protocol-logical-replication.html
The logical replication
START_REPLICATIONcommand accepts following parameters:
proto_version
Protocol version. Currently versions
1,2, and3are supported.Version2is supported only for server version 14 and above, and it allows streaming of large in-progress transactions.Version3is supported only for server version 15 and above, and it allows streaming of two-phase commits.publication_names
Comma separated list of publication names for which to subscribe (receive changes). The individual publication names are treated as standard objects names and can be quoted the same as needed.
只有 proto_version 跟 publication_names 是必給的參數,其中 version 2 只能用在 PG 14 以上並可以支援 streaming,而 version 3 只能支援 PG 15 以及 two-phase commits 的 streaming 機制。
1 | static void |
native logical replication
concept
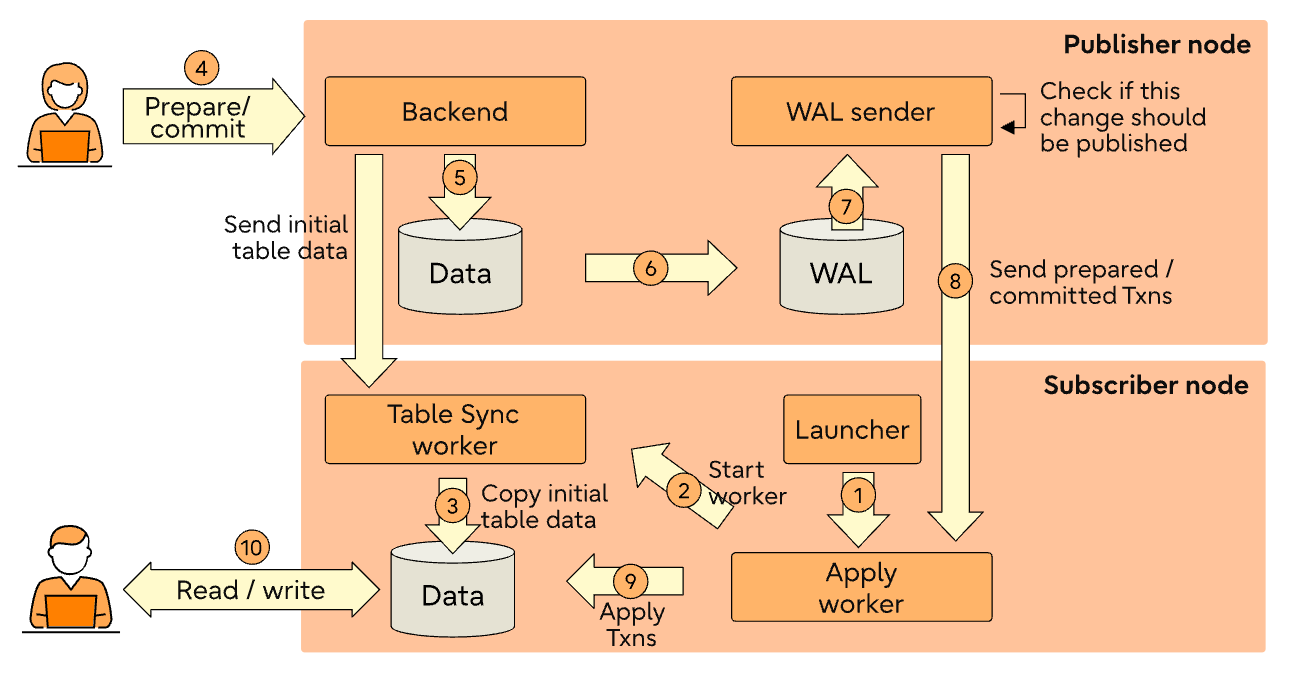
-
publication 可以定義怎樣的 change 可以被 replicated,例如你可以指定 table 或是指定 table 下符合某種條件的 row
-
當建立 publication 可以在 pg_publication 看到對應的 record:
1
2
3
4
5
6
7postgres=# CREATE PUBLICATION pub_alltables FOR ALL TABLES;
CREATE PUBLICATION
postgres=# SELECT * FROM pg_publication;
oid | pubname | pubowner | puballtables | pubinsert | pubupdate | pubdelete | pubtruncate | pubviaroot
-------+---------------+----------+--------------+-----------+-----------+-----------+-------------+------------
16392 | pub_alltables | 10 | t | t | t | t | t | f
(1 row) -
Subscriber 可以選擇要聽哪些 Publication,Subscriber 底下可以有多個 subscription,通常一個 replication slot 對應一個 subscription,為 table 建立 pub & sub 關係,可以設定是否要同步既有的資料。
-
當建立 subscription 可以在 pg_subscription 看到對應的 record:
1
2
3
4
5
6
7
8
9
10postgres=# CREATE SUBSCRIPTION sub_alltables
CONNECTION 'dbname=postgres host=localhost port=5432'
PUBLICATION pub_alltables;
NOTICE: created replication slot "sub_alltables" on publisher
CREATE SUBSCRIPTION
postgres=# SELECT oid, subdbid, subname, subconninfo, subpublications FROM pg_subscription;
oid | subdbid | subname | subconninfo | subpublications
-------+---------+------------------+------------------------------------------+-----------------
16393 | 5 | sub_alltables | dbname=postgres host=localhost port=5432 | {pub_alltables}
(1 row)在 pg_subscription_rel 可以看到所訂閱的 table 名單:
1
2
3
4
5
6
7
8
9postgres=# SELECT srsubid, srerelid::regclass FROM pg_subscription_rel;
srsubid | srrelid
---------+---------
16399 | accounts
16399 | accounts_roles
16399 | roles
16399 | department
16399 | employee
(5 rows) -
在 pg_replication_slots 也能看到 pub & sub 的關係:
1
2
3
4
5
6postgres=# SELECT slot_name, plugin, type, datoid, database, temporary, active,
active_pid, restart_lsn, confrm_flush_lsn FROM pg_replication_slots;
slot_name | plugin | slot_type | datoid | database | temporary | active | active_pid | restart_lsn | confirmed_flush_lsn
---------------+----------+-----------+--------+----------+-----------+--------+------------+-------------+---------------------
sub_alltables | pgoutput | logical | 5 | postgres | f | t | 24473 | 0/1550900 | 0/1550938
(1 row) -
pg_stat_subscription 可以看到對應資訊:
1
2
3
4
5postgres=# SELECT subid, subname, received_lsn FROM pg_stat_subscription;
subid | subname | received_lsn
-------+-----------------+----------------
16399 | sub_alltables | 0/1550938
(1 row) -
replication launcher 是一個 background worker 會去看底下是否有 enabled 的 subscription,如果有的話,就會叫 Apply Worker 做事
-
apply worker
![img-dgm-logical-replication-apply-worker-01]()
apply worker 會去接受 replication message -> decode change,並且對每一個 table 的 replication 開啟對應的 Tablesync worker 去做一開始的同步,至於會開多少個 worker 則是被 max_sync_workers_per_subscription 參數定義,定義同時會有幾個 worker 做同步
如果有開啟同步既有資料的設定,當底下的 table sync worker 都處理完之後,可以在 pg_subscription_rel 看到對應的狀態設定:
1
2
3
4
5
6
7
8
9postgres=# SELECT srsubid, srrelid::regclass, srsubstate, srsublsn FROM pg_subscription_rel;
srsubid | srrelid | srsubstate | srsublsn
---------+----------------+------------+-----------
16399 | accounts | r | 0/156B8D0
16399 | accounts_roles | r | 0/156B8D0
16399 | department | r | 0/156B940
16399 | employee | r | 0/156B940
16399 | roles | r | 0/156B978
(5 rows)srsubstate 代表的值有:
i= 初始化,d= 資料正在複製中,s= 已同步,r= 準備好開始複製 -
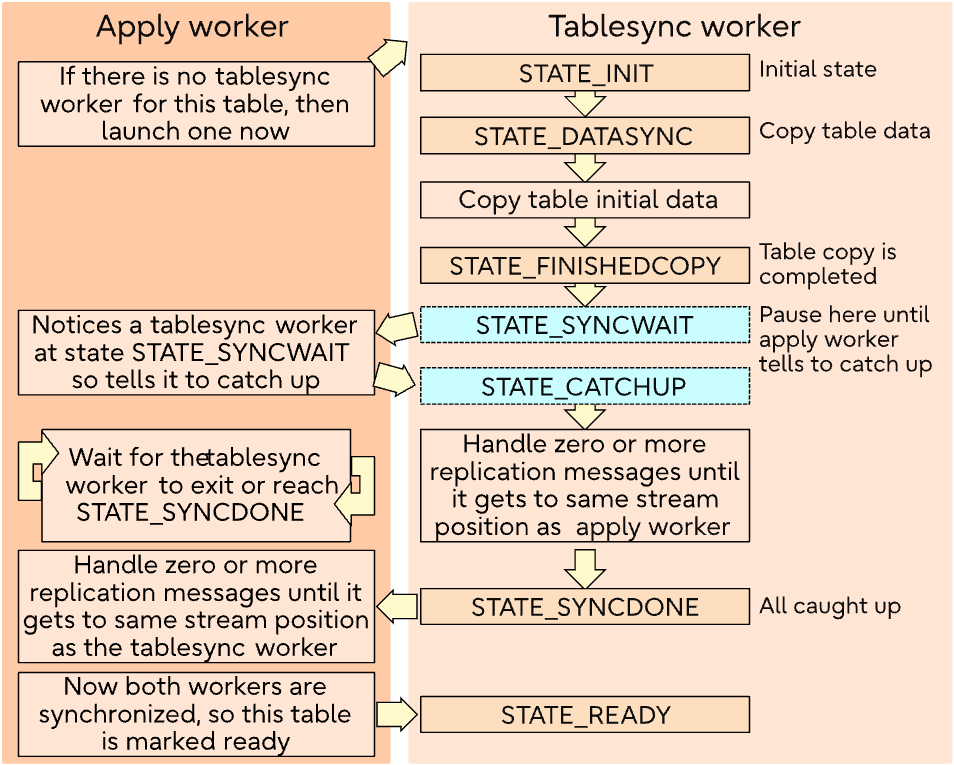
table sync worker
![img-dgm-logical-replication-tablesync-worker-01]()
1
2
3
4
5
6postgres: logical replication worker for subscription 16571 A
postgres: walsender postgres ::1(40932) START_REPLICATION
postgres: logical replication worker for subscription 16571 sync 16403 B
postgres: walsender postgres ::1(40934) COPY
postgres: logical replication worker for subscription 16571 sync 16385 B
postgres: walsender postgres ::1(40936) COPY這些 table sync 所定義的 replication slot 會自動產生:pg_
sync Example:pg_16571_sync_16403_6992073143355919431
-
當建立 subscription 可以設定 copy_data = true (預設),則會開始進行 table copy,如果 copy_data = false,會讓 table sync worker 跳過所有複製處理,並且直接設定狀態為 STATE_READY,並且 exit。
-
當 table sync worker 到了 STATE_SYNCWAIT 時,apply worker 會設定 table sync worker 為 STATE_CATCHUP,並且 loop 等待 table synce worker 變成 STATE_SYNCDONE
-
當 table sync worker 在 STATE_CATCHUP 需要跟上 apply worker 的 stream position,這邊有可能 table sync worker 會比 apply worker 還前面,一但 consume 到指定位置後就會設定為 STATE_SYNCDONE
-
apply worker 需要跟上 table sync worker 的 stream position,當兩邊位置都一致的時候,就會設定 tabel sync worker 為 STATE_READY,並且把 table sync worker 停掉
-
如果 table sync worker 同步過程中發生錯誤,例如資料 conflict,會紀錄錯誤並且退出,apply worker 會定期看有沒有還沒有達到 STATE_READY 的 table sync:
_
1
2
3
4
5
6
7
8
9postgres=# SELECT * FROM pg_subscription_rel;
srsubid | srrelid | srsubstate | srsublsn
---------+---------+------------+------------
16571 | 16385 | d |
16571 | 16403 | d |
16571 | 16412 | r | 0/11A31128
16571 | 16421 | r | 0/11A2F350
16571 | 16394 | r | 0/11A2F510
(5 rows)apply worker 會重新啟動新的 table sync worker 但如果 table sync worker 又遇到錯誤,會不斷循環這樣的流程直到:
- conflict 問題解決
- subscription 刪除
-
-
STATE_DATASYNC ~ STATE_FINISHEDCOPY 的 copy 操作是跑在一個 transaction 內的,如果跑到 STATE_FINISHEDCOPY 的時候,tabel sync worker 掛掉,下一次在重啟會跳過 copy 的步驟
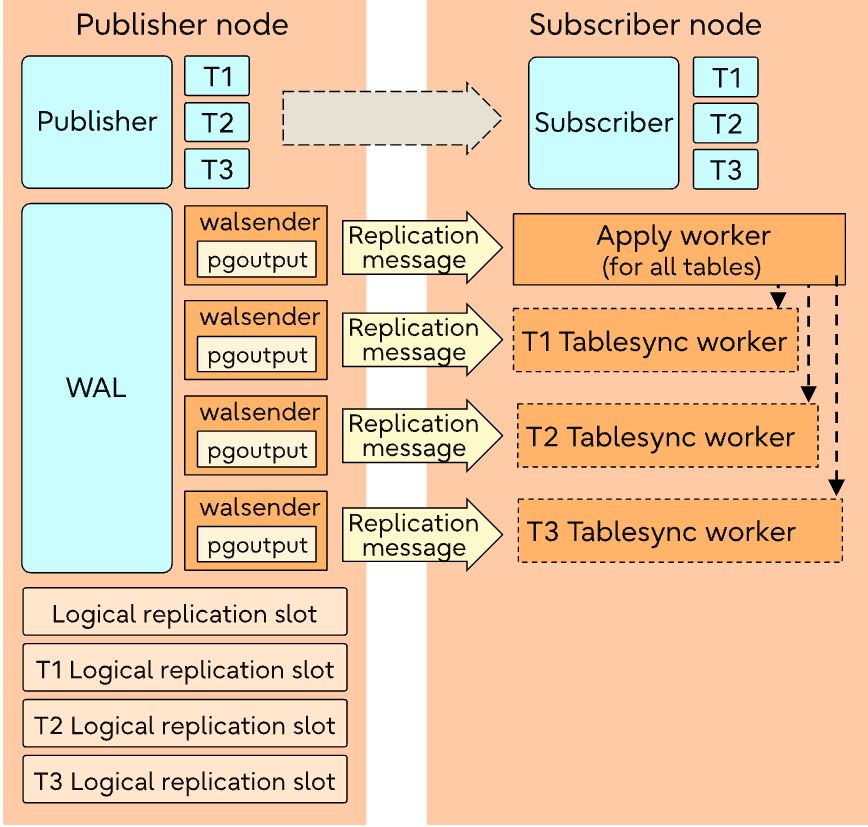
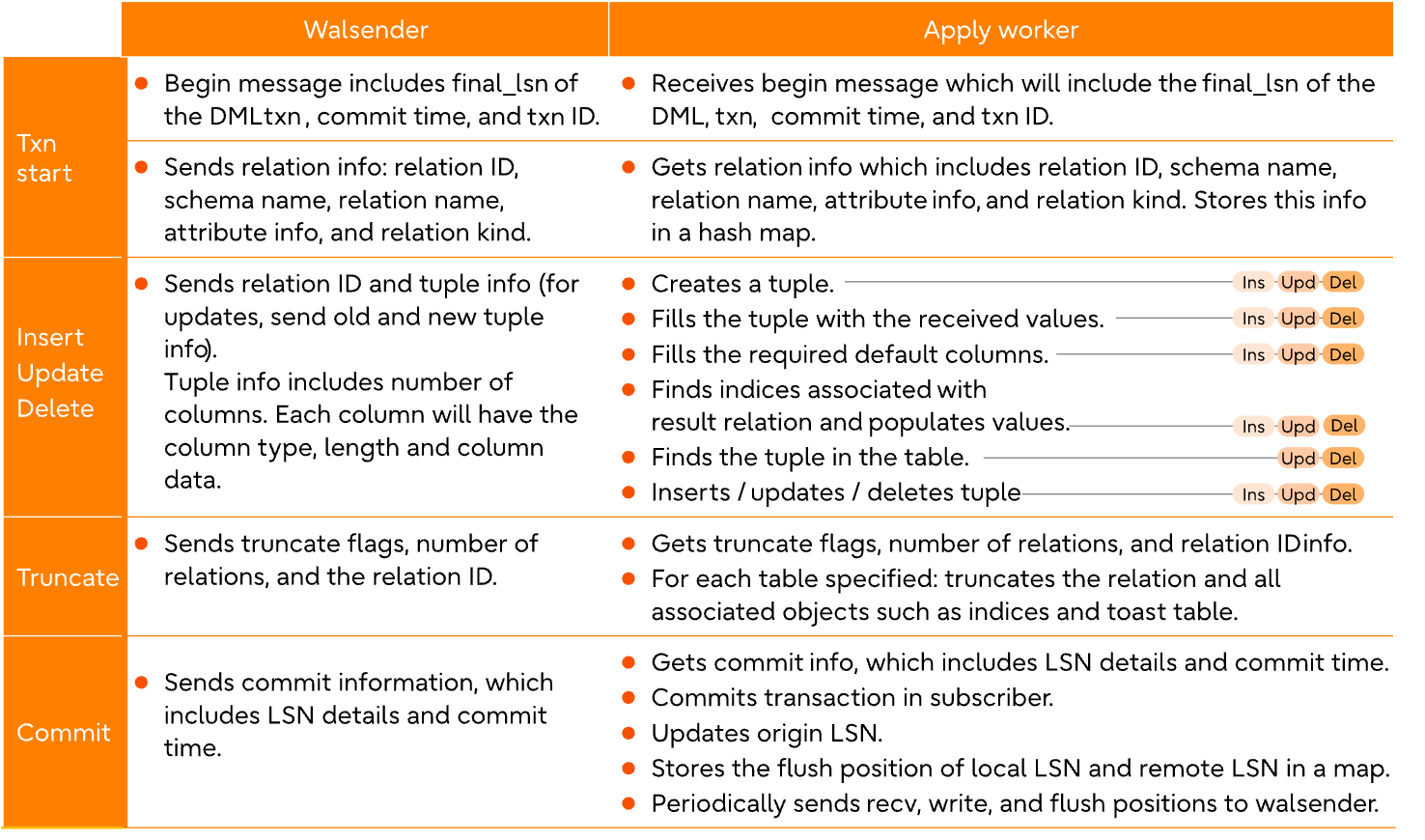
wal sender
wal sender 會讀 WAL 資料並且加入額外資訊,並且這些 change 會被 queued 在 reorderbufferqueue,根據 commit 的順序會去進行重排,如果 reorderbufferqueue 的容量超過 logical_decoding_work_mem,會去找當前最大的 transaction 驅逐到 disk,但如果有開 streaming 的機制的話,這個最大的 transaction 會先被送到 subscriber,但是只有當這個 transaction 被 committed 才會被 subscriber apply 上去。
當 transaction 一但被 committed 的話,walsender 會做以下的檢查:
- 檢查這個 table 是否需要被 replicate (根據 ALL TABLES or TABLE list or TABLES IN SCHEMA 設定)
- 檢查這個 operation 是否需要被 published,例如 publish option 可以設定要 replicated 哪種 DML 操作 (insert/update/delete/truncate)
- 檢查這個 operation 是否需要看 publish_via_partition_root 選項,預設會將 root 的 change 自動 publish 到底下的 partitioned table
- 檢查符合哪些 row filter 的 row 才能被 publish
- 檢查哪些 column 才能被 publish
conflict handling
1 | 2023-02-22 11:55:51.479 IST [21204] ERROR: duplicate key value violates unique constraint "employee_pkey" |
可以在 subscription 設定 skip LSN 的操作來跳過 conflict 的那段 transaction。或是用 disable_on_error 來設定當有錯誤的時候 subscription 會被關閉。
1 | postgres=# ALTER SUBSCRIPTION sub_alltables SKIP (lsn = '0/1562C10'); |
synchronous_commit
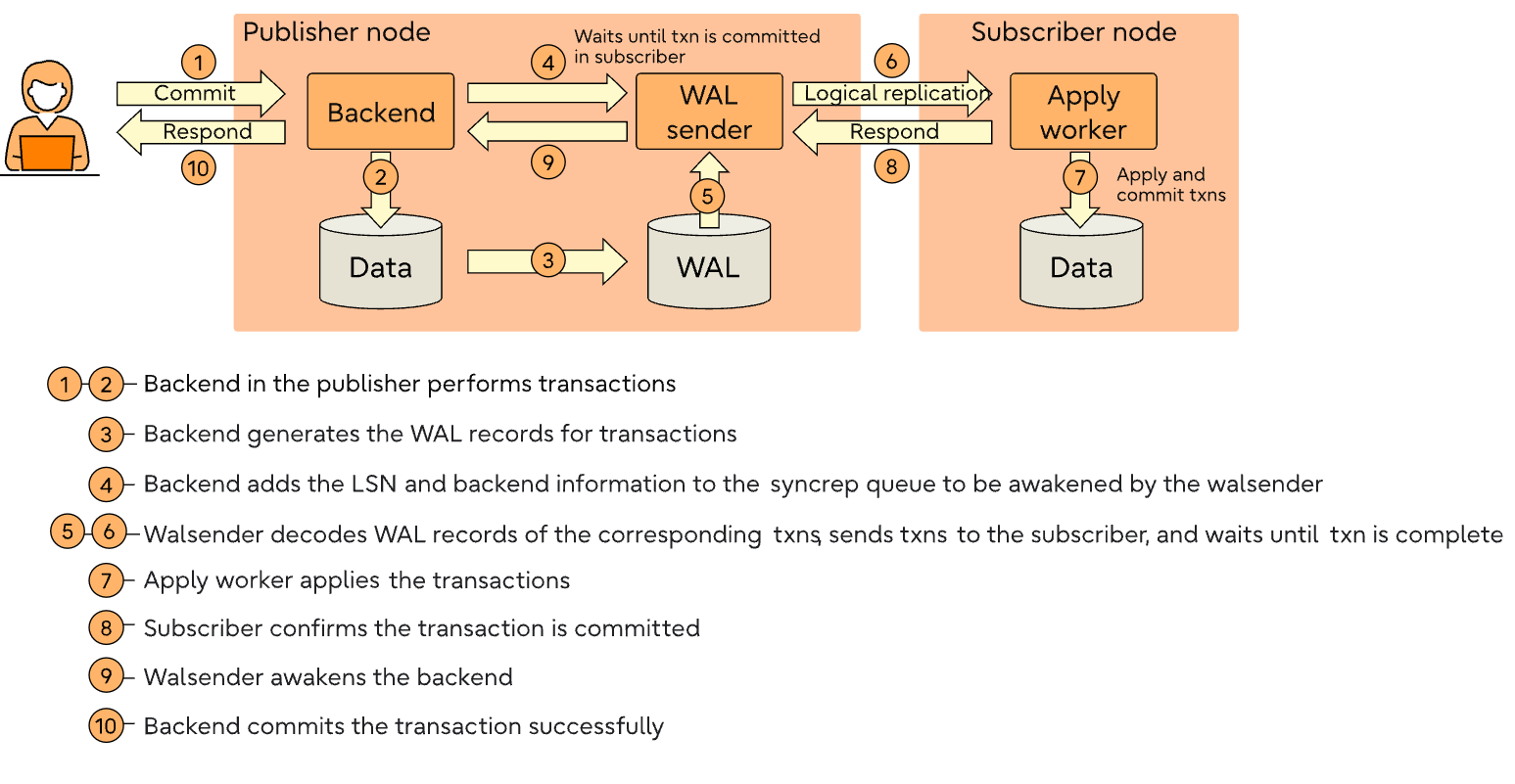
Subscriber
1 | postgres=# CREATE SUBSCRIPTION sync |
Publisher
1 | postgres=# ALTER SYSTEM SET synchronous_standby_names TO 'sync'; |
Row filter
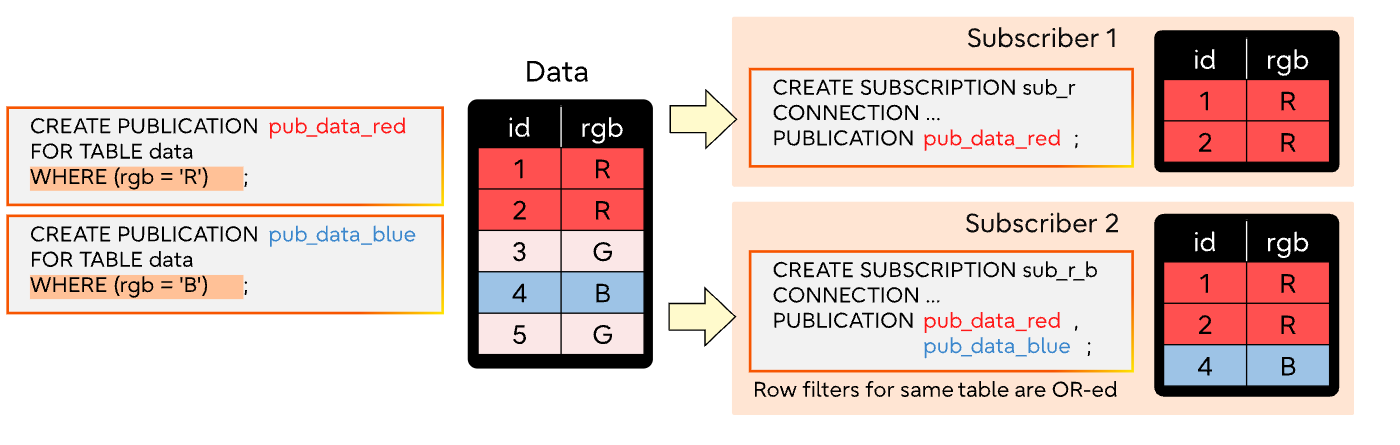
1 | postgres=# CREATE PUBLICATION active_departments FOR TABLE departments WHERE (active IS TRUE); |
insert, update, delete 對於 row filter 判斷行為:
- insert:檢查 new row 是否滿足 row filter 條件
- Delete:檢查 delete row 是否滿足 row filter 條件
- update:
- 如果 old row 或是 new row 都沒有符合 row filter 則 skip
- 如果 old row 不符合,但是 new row 符合,則 update
- 如果 old row 符合,但是 new row 不符合,則 delete old row
- 如果 old row 跟 new row 都符合,則 update
column lists
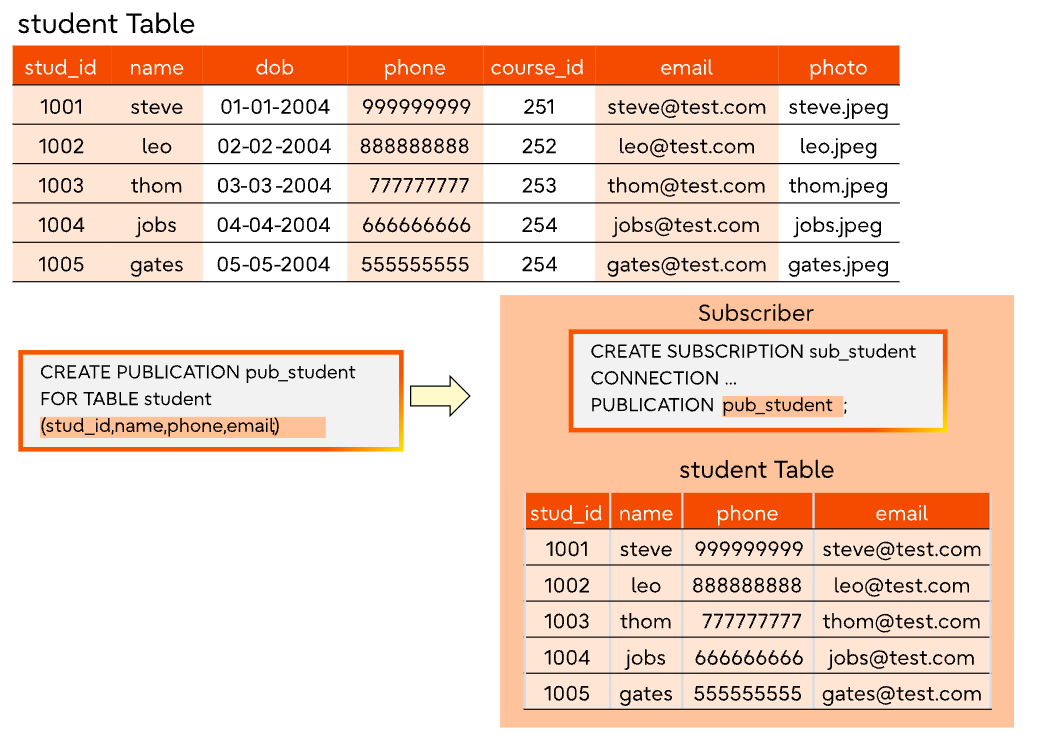
1 | postgres=# CREATE PUBLICATION users_filtered FOR TABLE users (user_id, firstname); |
row filter and column list 優點
- 減低 network traffic 對於 large table
- 只給 subscriber 需要的 data
- security issue
replicate tables in schema
1 | postgres=# CREATE PUBLICATION sales_publication FOR TABLES IN SCHEMA marketing, sales; |
- 當 subscription 有多個 publications,如果有一個 publication 是 replicate ALL TABLES,則這個 publication 優先級會最高,所有的 table 都會被 publish 給這個 subscription
- 當有新 table 是在 create publication 之後建立的話,必須手動跑 ALTER SUBSCRIPTION … REFRESH PUBLICATION,觸發 copy data and 同步的操作
Streaming of Large Transactions for Logical Decoding
- 因為當 transaction commit 後,walsender 會在 WAL 加入額外資料來支援 logical decoding plugin,而這些資料都會存在 memory 上,如果超過 memory 會將多餘資料存在 disk 上,這個 memory 量由 logical_decoding_work_mem 控制。
- 而當如果有大型的 transaction,例如 batch insert 之類的操作,會因為 memory 不夠而導致速度變慢,因此在 PG 14 在 pgoutput 實作支援 streaming 的操作。
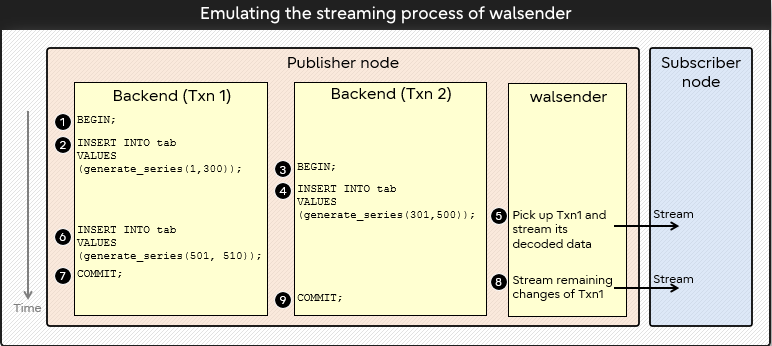
-
在 2 和 3 之間,還沒有 streaming 處理
1
2
3
4
5postgres=# SELECT stream_txns, stream_count, stream_bytes FROM pg_stat_replication_slots;
-[ RECORD 1 ]+------
stream_txns | 0
stream_count | 0
stream_bytes | 0 -
在 5 和 6 之間,streaming Txn1 第一部分的 change
1
2
3
4
5postgres=# SELECT stream_txns, stream_count, stream_bytes FROM pg_stat_replication_slots;
-[ RECORD 1 ]+------
stream_txns | 1
stream_count | 1
stream_bytes | 39600 -
在 6 和 7 之間,在 Txn1 再加入 insert
1
2
3
4
5postgres=# SELECT stream_txns, stream_count, stream_bytes FROM pg_stat_replication_slots;
-[ RECORD 1 ]+------
stream_txns | 1
stream_count | 1 個
stream_bytes | 39600 -
在 8 和 9 之間,新的 insert 也會被 streaming 出去
1
2
3
4
5postgres=# SELECT stream_txns, stream_count, stream_bytes FROM pg_stat_replication_slots;
-[ RECORD 1 ]+------
stream_txns | 1
stream_count | 2
stream_bytes | 40920 -
在 9 之後,Txn2 的 change 沒有被 streaming 出去
1
2
3
4
5postgres=# SELECT stream_txns, stream_count, stream_bytes FROM pg_stat_replication_slots;
-[ RECORD 1 ]+------
stream_txns | 1
stream_count | 2
stream_bytes | 40920

常見問題:
-
row filter 的限制,需要搭配 replica identity 的 mode,例如如果你 where condition 的 column 是無法拿到 old value,那 row filter 就會失效
31.3.2. Expression Restrictions
The
WHEREclause allows only simple expressions. It cannot contain user-defined functions, operators, types, and collations, system column references or non-immutable built-in functions.If a publication publishes
UPDATEorDELETEoperations, the row filterWHEREclause must contain only columns that are covered by the replica identity (seeREPLICA IDENTITY). If a publication publishes onlyINSERToperations, the row filterWHEREclause can use any column. -
streaming 機制中如果 pub 端有 rollback 的話,會透過 stream_abort 通知 sub 來忽略之前收到的 streaming change:
-
logical replication 中如果 copy data 階段或是後續的 apply worker 遇到 fk 會怎麼處理:
實際上是被 session_replication_role 所控制,且 sub 端會預設將 role 設定為 replica,代表不會觸發 trigger,因此不會進行 fk 的檢查:
session_replication_role(enum)Controls firing of replication-related triggers and rules for the current session. Possible values are
origin(the default),replicaandlocal. Setting this parameter results in discarding any previously cached query plans. Only superusers and users with the appropriateSETprivilege can change this setting.The intended use of this setting is that logical replication systems set it to
replicawhen they are applying replicated changes. The effect of that will be that triggers and rules (that have not been altered from their default configuration) will not fire on the replica. See theALTER TABLEclausesENABLE TRIGGERandENABLE RULEfor more information.PostgreSQL treats the settings
originandlocalthe same internally. Third-party replication systems may use these two values for their internal purposes, for example usinglocalto designate a session whose changes should not be replicated.Since foreign keys are implemented as triggers, setting this parameter to
replicaalso disables all foreign key checks, which can leave data in an inconsistent state if improperly used.但如果想要啟動 trigger 機制除了設定 session_replication_role 不為 replica 之外,也可以透過
ALTER TABLE ... ENABLE TRIGGER去設定哪些 TRIGGER 要開啟還是關閉:1
DISABLE`/`ENABLE [ REPLICA | ALWAYS ] TRIGGER
These forms configure the firing of trigger(s) belonging to the table. A disabled trigger is still known to the system, but is not executed when its triggering event occurs. For a deferred trigger, the enable status is checked when the event occurs, not when the trigger function is actually executed. One can disable or enable a single trigger specified by name, or all triggers on the table, or only user triggers (this option excludes internally generated constraint triggers such as those that are used to implement foreign key constraints or deferrable uniqueness and exclusion constraints). Disabling or enabling internally generated constraint triggers requires superuser privileges; it should be done with caution since of course the integrity of the constraint cannot be guaranteed if the triggers are not executed.
The trigger firing mechanism is also affected by the configuration variable session_replication_role. Simply enabled triggers (the default) will fire when the replication role is “origin” (the default) or “local”. Triggers configured as
ENABLE REPLICAwill only fire if the session is in “replica” mode, and triggers configured asENABLE ALWAYSwill fire regardless of the current replication role.The effect of this mechanism is that in the default configuration, triggers do not fire on replicas. This is useful because if a trigger is used on the origin to propagate data between tables, then the replication system will also replicate the propagated data, and the trigger should not fire a second time on the replica, because that would lead to duplication. However, if a trigger is used for another purpose such as creating external alerts, then it might be appropriate to set it to
ENABLE ALWAYSso that it is also fired on replicas.This command acquires a
SHARE ROW EXCLUSIVElock.之所以要預設在 sub 端不開啟 trigger,怕 pub 端的 trigger 行為會造成 data replicate 給下游,並且下游也有相同的 trigger 的話,會被再次觸發導致重複的資料。
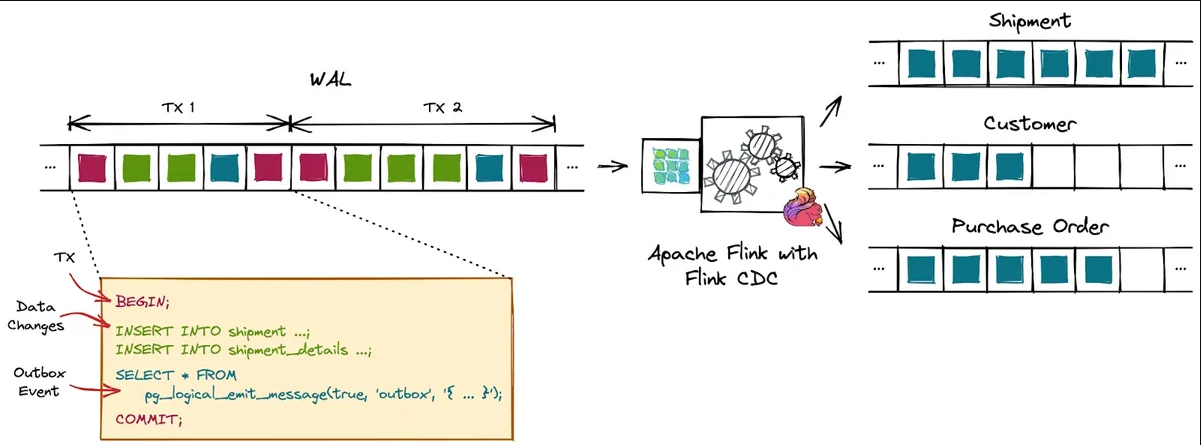
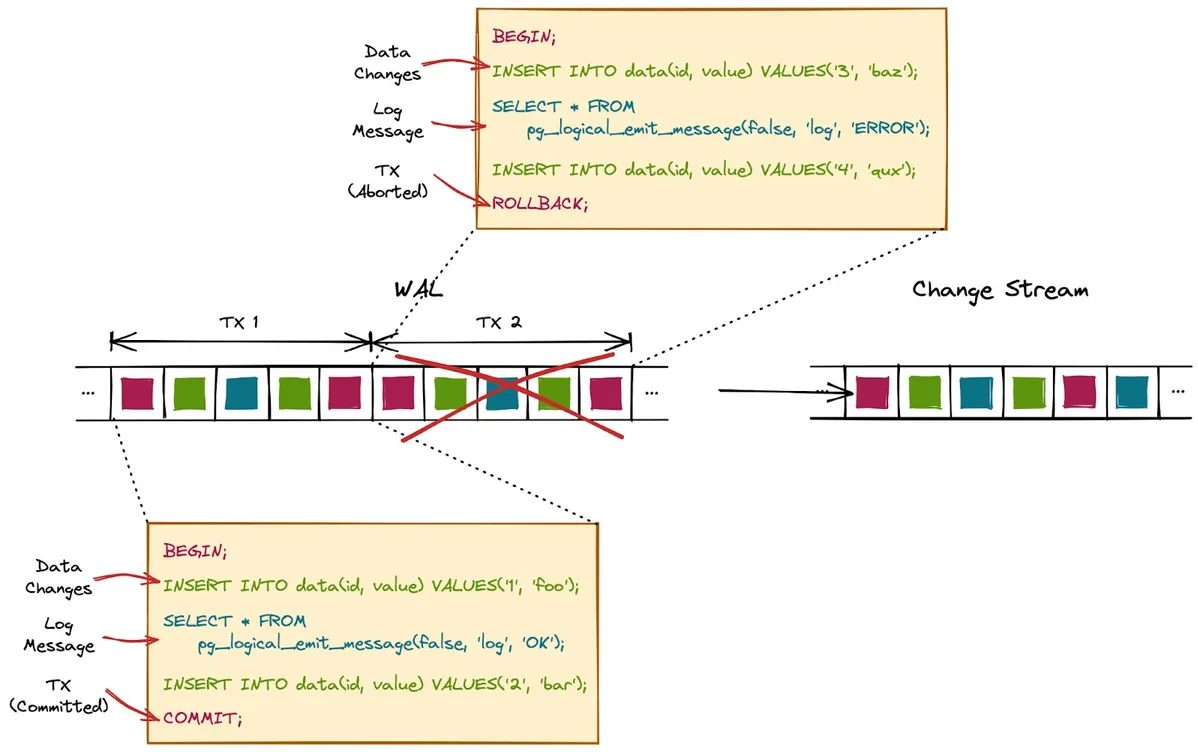
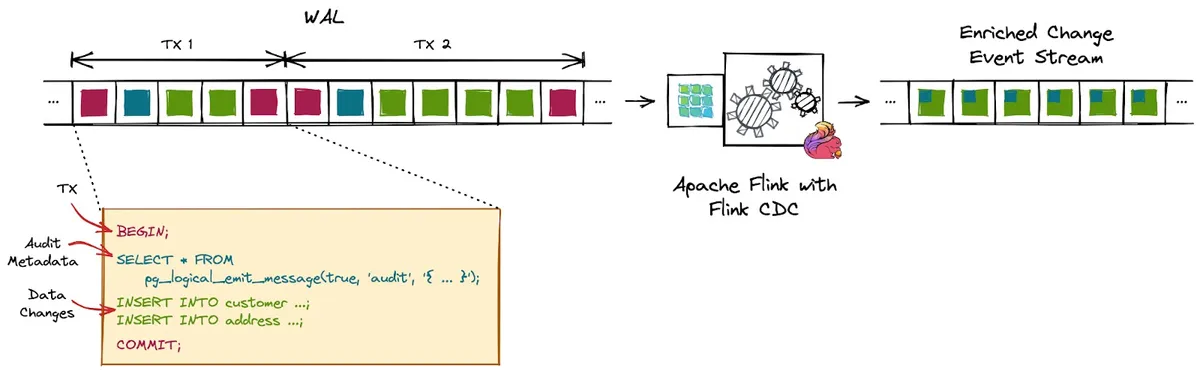
pg_logical_emit_message
transactional: 設定該 message 是否會跟著 transaction 一起 commit 或是 rollback,如果不是則會寫入 WALprefix: 設定該 message 的 identifier,用來識別是屬於哪種 messagecontent: message 的實際內容,可以自定義
1 | postgres=# select * from pg_logical_emit_message(true, 'context', 'Hello World!'); |
應用場景:
-
message event
![img]()
-
Logging
![img]()
-
audit log
![img]()
Ref
-
Postgres WAL Files and Sequence Numbers
https://www.crunchydata.com/blog/postgres-wal-files-and-sequuence-numbers
-
PGConf NYC 2021 - Evolution Of PostgreSQL Replication and High Availability… by Stacy Scoggins
-
PostgreSQL WAL Archiving and Point-In-Time-Recovery
https://www.postgresql.org/docs/current/continuous-archiving.html
https://www.highgo.ca/2020/10/01/postgresql-wal-archiving-and-point-in-time-recovery/
-
The PostgreSQL Timeline Concept
https://www.highgo.ca/2021/11/01/the-postgresql-timeline-concept/
-
Webinar: A Review of PostgreSQL Replication Approaches
-
Streaming Replication Protocol
https://www.postgresql.org/docs/current/protocol-replication.html
-
Setting up failover and recovery on a streaming replication setup
https://www.postgresql.fastware.com/postgresql-insider-str-rep-ope
-
Setting Up PostgreSQL Failover and Failback, the Right Way!
https://www.postgresql.org/docs/current/warm-standby-failover.html
https://www.highgo.ca/2023/04/10/setting-up-postgresql-failover-and-failback-the-right-way/
-
PostgreSQL Replication Conflicts: Avoiding Pitfalls - Hamid Akhtar - Percona Community Live 2022
-
Logical Decoding
https://www.postgresql.org/docs/current/logicaldecoding-explanation.html
-
Inside logical replication in PostgreSQL: How it works
https://www.postgresql.org/docs/current/logical-replication.html
https://www.postgresql.fastware.com/blog/inside-logical-replication-in-postgresql
-
Postgresql logical replication and foreign key constraints
https://www.deepbluecap.com/postgresql-logical-replication-and-foreign-key-constraints/
-
How to gain insight into the pg_stat_replication_slots view by examining logical replication
-
The Wonders of Postgres Logical Decoding Messages
總結
整理 replication 的原因,也是因為我一直在準備 Postrges upgrade 的研究,因此看了很多資料去了解從 physical replication ~ logical replication,有些資料其實 PG 官網講得滿模糊的,也是參考了很多不少外國大神寫的文章,經過我的理解去做整個統整。
如有錯再請告知了~