AlloyDB for PostgreSQL under the hood - 筆記

在今年 2022 Google I/O 上, Google 宣佈了新的 AlloyDB For Postgres 新產品,AlloyDB 是與 Postgres 完全相容的 database,是拿 Postgres 的 Source Code 加以改良性能,使得可以應付 enterprise-grade transactional and analytical workloads。
該篇文章的筆記是來自於閱讀 AlloyDB intelligent, database-aware storage 與 AlloyDB Columnar engine 兩篇文章的。
根據 Google 給出的測試結果,AlloyDB 在 transcation workloads 下比原本的 Postgres 快四倍以上,並且對於 analytical queryies 更是快一百倍以上。
Disaggregation of compute and storage
AlloyDB 之所以可以快那麼多,其主要核心是因為它將 compute and storage 兩邊元件分開處理,才能極致的優化 compute 與 storage,在 storage 實作了 intelligent storage service,使得可以減少 I/O bottlenecks,而且在 storage layer 也拆解 compute 與 storage 的元件,也就是 write log 的處理與實際儲存這兩邊可以分開擴展。
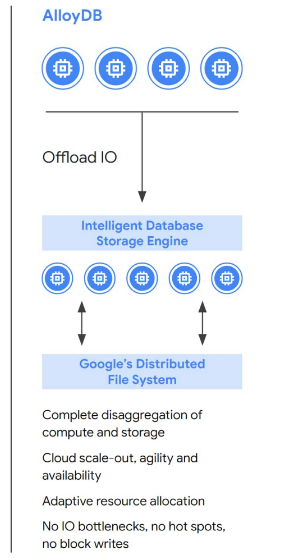
透過這樣解耦 compute and storage layer 帶來的好處有:
- dynamically adapt to changing workloads
- adds failure tolerance
- increases availability
- enables cost-efficient read pools that scale read throughput horizontally
- multiple layers of caching throughout the stack, which are automatically tiered based on workload patterns
The trouble with monolithic design
原生的 Postgres 屬於單體架構,計算與儲存的資源共存在一台機器中,如果需要提升計算性能與儲存容量,只能換到更強的機器,或是添加更多 disk 容量,隨著需求越來越高,不能在單台機器中負荷後,就需要採用多台 replica 來應付 read 的需求。
由於以上的缺點,導致:
- failover times are longer and less predictable
- read replicas have their own, lagging, and expensive copy of the database, making it more difficult to scale read capacity and manage replica lag.
因此,AlloyDB 可以直接添加 read replica 來負擔 primary instance 的 loading,但卻不需要添加一整個 database copy,因為 AlloyDB 底層的 storage 是另外的元件,所以建立 read replica 不用建立自己的 storage,所以可以快速新增成本低的 read replica。
AlloyDB design overview
AlloyDb Storage 由三個部分組成:
- A low-latency, regional log storage service for very fast write-ahead log (WAL) writing,
- A log processing service (LPS) that processes these WAL records and produces “materialized” database blocks
- Failure-tolerant, sharded, regional block storage that ensures durability even in case of zonal storage failures.
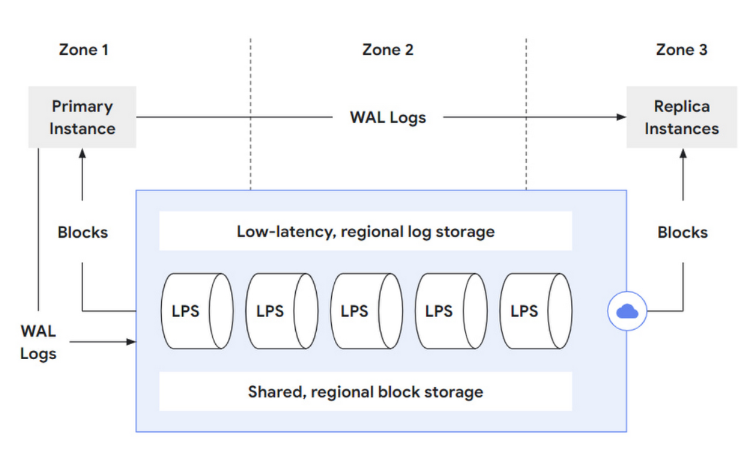
當 Primary Instance 執行 INSERT/DELETE/UPDATE 操作的時候,會需要將這些操作記錄到 low-latency regional log store 也就是 WAL Logs 的紀錄,接著 LPS 會採用非同步的機制去拿出這些 WAL Logs 進行 replay 將資料 flush 到 Shard, regional block storage。每一個 log record 只會在每一個 zone 執行一次,而同時這些 WAL Logs 也會被送往 Replica instances,來讓 replica 的 buffer cache 之類的資料可以保持最新。
帶來好處有:
- Full compute/storage disaggregation:LPS 本身可以根據 workload 來進行 horizontal scale,來避免 hot spot 的問題發生,而 LPS 本身只是負責 compute 並寫資料到 storage layer 因此可以靈活的 scale 而不需要複製任何資料。
- Storage-layer replication:在所有的 zone,同步的去 replica 所有 block 資料,當有 zone 掛掉是可以復原回來的
- Efficient IO paths /no full-page writes:對於更新操作,compute layer 將 WAL Log 紀錄傳遞給 storage layer,storage layer 會持續不斷的 replay,這樣的設計不需要有 checkpoint 並且也不需要將完整的 page block 傳到 storage layer 可以解決 torn pages problem
- Low-latency WAL writing
- Fast creation of read replica instances:因為 storage service 可以 serve 任何一個 zone 裡面的任何一個 block,也就是說當建立 read replica 可以自由選擇 attach 到哪個 storage service,不需要有自己 private 的 storage copy,而且可以根據需求,來從 storage service 增量去加載數據,比如說當還不需要 query processing 之前就先不需要 stream a complete copy 到 read replica。
- Fast restart recoveryStorage-layer backups:因為 log processing service 會在背後持續的 replay 所以 restart recovery 的時間就會大幅縮短,因為 lag 會降到很低。
- Storage-layer backups:storage service 專門處理 backup 的,而不會佔用 compute layer 的 resources。
Torn Pages Problem
這邊解釋一下何謂 Torn Pages Problem,因為 Postgres 使用 8KB 的 page block size,但 Linux file system 通常都是用 4KB 的 page block size,那麼在 Postgres 分別寫入兩個 4KB 的時候如果這時候斷電或是故障,那麼 Postgres 重啟後要怎麼 recovery 呢?
我們知道 Postgres 有所謂的 WAL Log 可以透過 Redo 的方式 replay 遺失的數據回來,但有個前提是,他也需要去讀當前的 page block 來決定如何 apply WAL Log 上面的紀錄來進行 replay,但如果當前 page block 就是因為某種原因故障了,那就無法完美的 recovery 回來,因應這種情況,Postgres 提出了 Full-Page Writes 的方式,也就是說 Postgres 會在每一個 checkpoint 後的每個 page block 的第一次更改將一整個頁面記錄在 WAL Log 上。因此當發生這樣的故障時,Postgres 不需要去讀損壞的 Page 而是根據 WAL Log 去復原一整個 Page block 的紀錄。
而這樣的方式所帶來的缺點就是增加 WAL Log 的大小,而 Full-Page Writes 只發生在 checkpoint 後的第一次寫入,所以想降低 Full-Pages Writes 的成本方式是透過增加 checkpoint interval parameters。
這樣的機制是由 Postgres 的 full_page_writes 參數控制的,預設是開啟,如果關掉的話就會有遺失數據的風險存在。
以下為 Postgres 官網的敘述:
When this parameter is on, the PostgreSQL server writes the entire content of each disk page to WAL during the first modification of that page after a checkpoint. This is needed because a page write that is in process during an operating system crash might be only partially completed, leading to an on-disk page that contains a mix of old and new data. The row-level change data normally stored in WAL will not be enough to completely restore such a page during post-crash recovery. Storing the full page image guarantees that the page can be correctly restored, but at the price of increasing the amount of data that must be written to WAL. (Because WAL replay always starts from a checkpoint, it is sufficient to do this during the first change of each page after a checkpoint. Therefore, one way to reduce the cost of full-page writes is to increase the checkpoint interval parameters.)
Turning this parameter off speeds normal operation, but might lead to either unrecoverable data corruption, or silent data corruption, after a system failure. The risks are similar to turning off
fsync, though smaller, and it should be turned off only based on the same circumstances recommended for that parameter.Turning off this parameter does not affect use of WAL archiving for point-in-time recovery (PITR) (see Section 26.3).
This parameter can only be set in the
postgresql.conffile or on the server command line. The default ison.
另外可以解決 Torn Pages Problem 可以透過 OS 的 file system 是否有防止這樣問題發生的保護,例如 ZFS 的 file system 就可能可以解決這樣的問題。
這是因為 ZFS 的特性是有 copy-on-write 的功能:核心就是當檔案有變更時,不是直接覆蓋舊有的資料,而是將使用中的區塊複製出來,而這些變更是在這複製的區塊上。所以當資料變更時,舊有的資料依然能夠維持,方便作為復原之用。這樣的特性可以解決 Torn Pages Problem。
想看更詳細 ZFS 與 Btrfs 的細節可以參考這篇文章:https://farseerfc.me/btrfs-vs-zfs-difference-in-implementing-snapshots.html#id34
Life of a write operation
回過頭來看 AlloyDB 整個 write operation 流程:
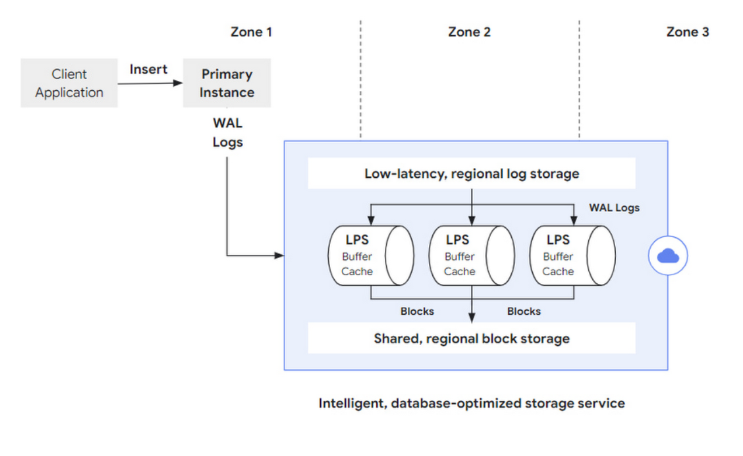
- Primary instance 的 compute layer 收到 Insert 指令並進行處理
- 並將該筆 commit 記錄到 WAL Logs 並存到 low-latency, regional log storage
- 再來 WAL Logs 會被 LPS 非同步的存取並 replay 將資料儲存在 shard, regional block storage,儲存成功後刪掉 WAL logs。
Life of a read operation
讀取的操作可以送往 primary instance 或是 read replica,而與原生 Postgres 一樣一開始會需要做相同 query parse and rewrite, query plan 等手續。如果所需要的資料都存在 buffer cache,則就不需要跟 storage layer 拿資料。
即使 buffer cache miss,那麼 AlloyDB 這邊還有多做 Ultra fast cache 來擴充 buffer cache 的容量,用來加速系統。
但如果 ultra fast cache 也 miss,那麼送到 storage layer 的時候,會指定想查詢的 page block 及 LSN,因為指定 LSN 的關係確保 database 在 query processing 可以看到一致的狀態。
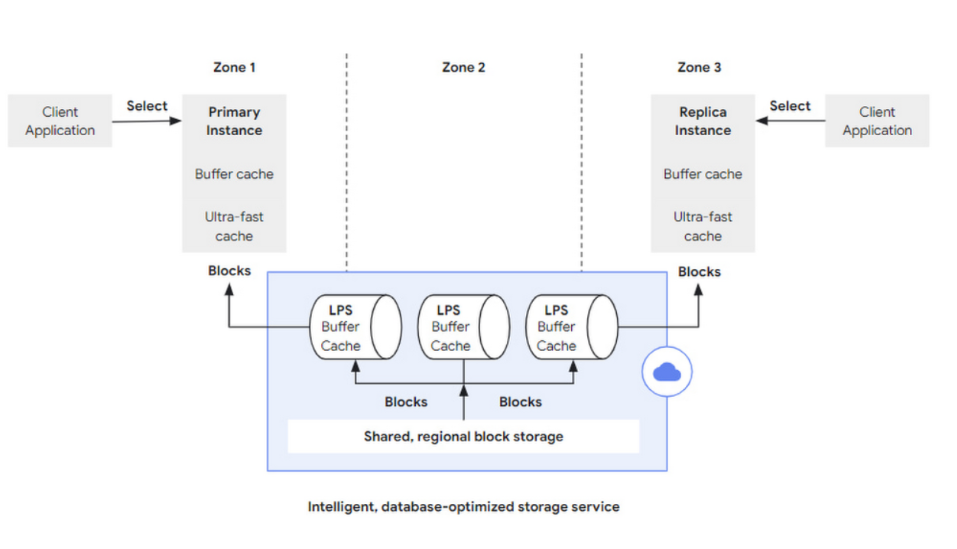
而在 Storage layer 要負責 page block 的請求,每個 LPS 也會有自己的 buffer cache,如果有 hit 到那麼就不需要任何 I/O 操作去讀取 storage,此外 LPS 會紀錄哪些尚未處理的 log 紀錄,如果是存取這種沒 cache 到的紀錄,就會實際到 storage 進行查詢。
而 LPS 本身會紀錄哪些 WAL logs 尚未進行 replay,如果這時候有這種 query 的請求,那麼就必須等 LPS 將 replay 做完才可以,因此 LPS 的性能及 scale 就很重要。
Storage layer elasticity
LPS 本身既要負責 WAL Log Replay 的工作也要 serve 多個 read replica 或是 primary instance 的讀取請求,因此為了解決這個問題 LPS 是可以水平擴展的,且底層的 storage 也可以被水平劃分成多個 shard,每個 shard 會被分配到一個 LPS,但每個 LPS 可以處理多 shard。
而 shard 與 LPS 的對應是動態的,允許我們動態新增 LPS 的資源與數量來快速重新分配 shard,這樣做可以避免 hot spot 的問題。
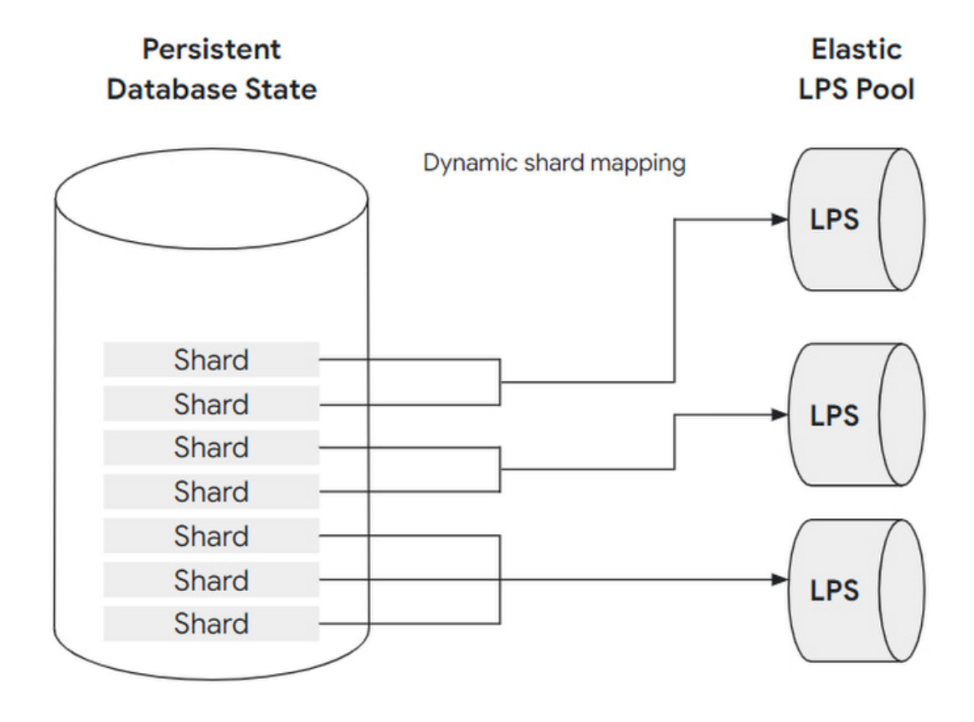
storage layer 可以動態的觀察到目前 loading 量來決定每個 LPS 要被分到多少 shard 來減輕 LPS 的 loading,如果 loading 變少也會動態的減少 LPS 的數量,減少其資源佔用,達到 load balance 的效果。
Storage layer replication and recovery
AlloyDB 的目標是即使有某部分的 zone 故障了仍然可以提高資料持久性可用性,因此每個 AlloyDB 可以分佈在三個 zone 上,每個 zone 上都會有一個完整的 database copy,透過 LPS 不斷 replay WAL log 來達到低延遲的一致性。
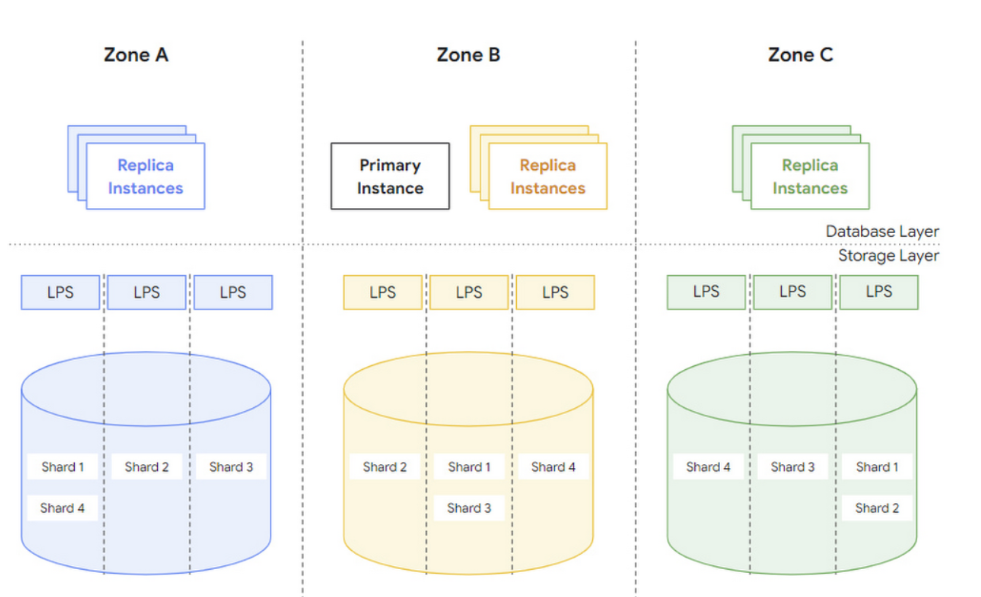
- 每個 zone 的 read 操作不需要跨越 zone,減少成本
- 當讀取的時候會指定唯一的目標版本的 LSN。
- 如果整個 zone 不可用,storage layer 可以透過同一個 region 的新 zone 來替換故障的 zone,並且確保每個 zone 上的資料都是最新的。
- Alloy DB 還集成了手動及自動的備份操作。
What AlloyDB’s intelligent storage can do for you
所以根據前半段的 storage 介紹,我們可以知道 AlloyDB 透過分離 compute 及 storage 的方式去極致的優化 storage 的 layer,使用了 LPS 來作為彈性的水平 scale,加上可以不斷自動的改變 scale 策略,偵測目前的 loading 量,提供容錯能力及可用性,並達到 load balance 的效果。
此外因為 compute layer 不需要將資源給 storage layer,有著於提升查詢的速度,結合這些優點,AlloyDB 的性能及可用性大幅提升。
PostgreSQL and hybrid workload patterns
通常我們用 Postgres 都是拿來做 OLTP 的查詢,但是在 AlloyDB 則是在 Postgres 這邊大幅的加強 OLAP 的查詢性能,測試下來是比標準的 Postgres 快 100 倍,原因就在於 AlloyDB 裡面使用了機器學習來自動學習要使用 Columnar engine 還是用 Row engine 來進行查詢,這種混合式的查詢就是 AlloyDB 是提升 OLTP 與 OLAP 性能的關鍵。
AlloyDB columnar engine
Google 在開發 columnar engine 有許多經驗,像是 BigQuery 就是採用 columnar engine 來提升 OLAP 的性能,因此 AlloyDB 同樣運用類似的技術來嵌入原生 Postrges 的 row engine,因此達到混合式 engine 的方式。
在 AlloyDB 的 columnar engine,會去學習每一次的查詢,並且將這些有效的資訊 encode 存在 metadata,這些 metadata 的資料可以拿來用在 where filter 用 high selective 的 condition 的時候,columnar engine 會將這些直存在 metadata,用來加速 equal or range 的查詢。
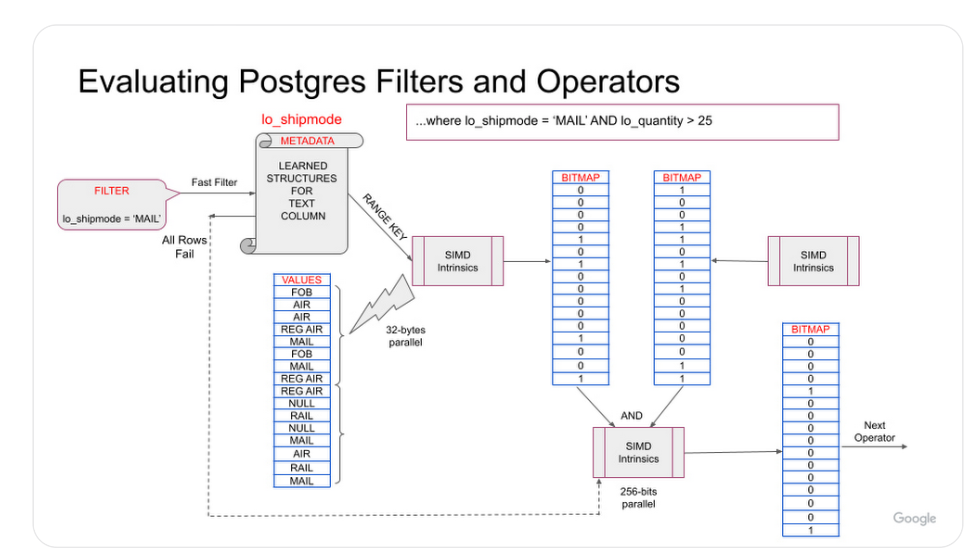
例如來看這個例子,對於 where lo_shipmode = 'MAIL' 的條件,columnar engine 首先會去檢查 column 的 metadata 是否有對應的 MAIL 值,如果出現了就會利用 SIMD 指令進行 search,來提升查詢的效率。
或者如果沒有出現 'MAIL',columnar engine 會省掉搜尋大量的成本,例外也可以利用 Io_quantity` 的最小 / 最大 metadata 來跳過縮減 search 的 range
Query plan execution
對於 query plan,AlloyDB 會根據查詢的內容來決定是否要用 row /columnar engine,來看例子:
1 | select sum(lo_revenue) as revenue |
假設此查詢有高度選擇性
1 | Aggregate (cost=1006.43..1006.44 rows=1 width=8) (actual time=8.219..8.220 rows=1 loops=3) |
- Custom Scan 是代表 columnar scan 的方式,filter 19959121 以及 Aggregated 21216 筆。
- Seq Scan 是原生 Postgres 的 row scan 的方式,當 query planner 決定要採用 hybid 的方式才會使用,在這個 plan 上沒有使用到
- Append 是合併 Columnar scan 和 Row store Sequential Scan 的結果。
根據測試結果下來,比原生 Postgres 快了 117 倍。
總結
分析了 AlloyDB 的架構,性能好的原因主要是就兩種,storage 及 columnar engine 的極致優化。希望有機會可以試用到~