Designing Data-Intensive Applications 書本 - Replication 筆記 (3)
今天來談談 replication 最後的主題就是 Leaderless Replication。前面所說的都會有所謂的 Leader 去接收 Client 的 Write 的需求在同步給 Follower。 Leaderless Replication 盛行於 Amazon 的 Dynamo System,之後 Riak, Cassandra and Voldemort 這些 open source 也採用 leaderless replication,這些類型的資料庫被叫做 Dynamo-style。
Leaderless Replication 每個 Node 都是獨立的,也可以進行讀寫,這樣的架構在乎的倒也不是資料一致性,而是集群的可用性。
Writing to the Database When a Node Is Down
在 Leaderless Replication 下,就不太需要處理之前提到的 failover 情況,請看圖:
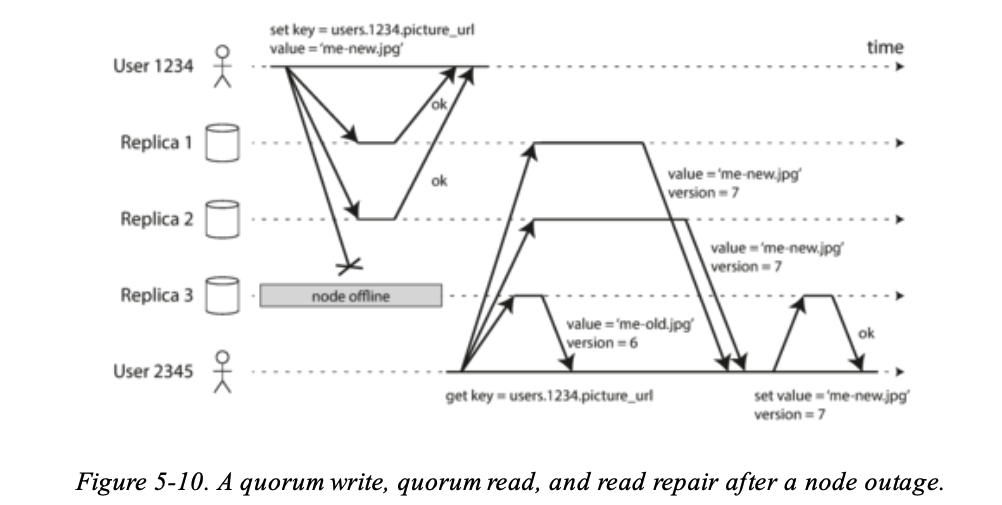
- User 1234 會同時將這些 write 送到三個 replica,如果有一個 replica 掛了,其他兩個 replica 仍然可以收到。
這樣的設計最大的缺點當然是如果壞掉的 replica 回復正常後,User 讀取資料如果是從這個 replica 讀取,就會讀取到舊的資料。為了解決這個問題,User 讀取資料的時候會設計同時多個 replica 讀取資料,User 相對的也會拿到多筆資料 by different nodes,其中一種做法是透過 version numbers 去區分哪一筆資料才是最新的,藉此選出最正確的資料。
Read repair and anti-entropy
在 LeaderLess 架構下要如何保證壞掉的 node 回覆之後可以 catch up on the writes that it missed?
有以下兩種機制:
Read repair
當 client 發出多個 read 給多個 node 的時候,透過 version number 的方式去找出哪些是新的資料,而這時沒跟上新資料的 replica 就會把這些新資料寫回去 replica,來保證讀這次的資料也會間接的更新舊 replica 的資料。
Anti-entropy process
另外一種方式是有些 database 會有所謂的 background process 會持續性的看這個 replica 與其他 replica 的資料是否有缺失或是沒跟上,然後來 copy 新資料到這個 replica 上。但是 copy writes 並不會有順序之分,相較於 leader-based replication 也會有較高的 delay。
不是所有的資料庫都會支援以上兩種方式,但這兩種方式很大差異在於,第一種方式只有在讀的時候才會趁機做更新資料的操作,相對而言如果有一些資料很少會被讀到就很不會被更新到。第二種方式則會持續性做更新的動作。
Quorums for reading and writing
在以上圖的來做例子,如何訂下規則是真正的寫入成功?說白可以從多數決的角度去看,如果我有 n 個 replicas,每一個 write 都必須被 w nodes 接受並寫入成功,而 User 讀取資料必須要讀取 r nodes 來確保能夠分辨出新舊資料。
以圖的情況來看, n = 3, w= 2, r =2 ,只要 w + r > n,可以假設讀取的時候都一定可以讀取到最新的資料,因為至少會有一個 r node 可以保證是拿到最新的資料。遵守 r and w 的規則就稱為 quorum,可以想成 r and w 是為了讓寫入與讀取的有效最小值。
通常在這樣架構的 database,n, w 的值是可以被客製化的,常見的做法是將 n 設為奇數,通常是 3 或 5,這樣可以 set w = r = (n + 1) / 2 (四捨五入)。
如果 w = n and r = 1,這樣的做法可以讓 read 非常的快,但是如果有一個 node fail,所有的 write 都會失敗無法執行。
來看看在符合 w + r > n 的條件下,能讓系統容許多少不可用的節點:
-
如果 w < n 並且有一個 node unavailable 仍然可以執行 write。
-
如果 r < n 並且有一個 node unavailable 仍然可以執行 read。
-
如果 n = 3, w = 2, r = 2,系統可以忍受一個 unavailable node。
-
如果 n = 5, w= 3 , r = 3,系統可以忍受兩個 unavailable node。
![figure2]()
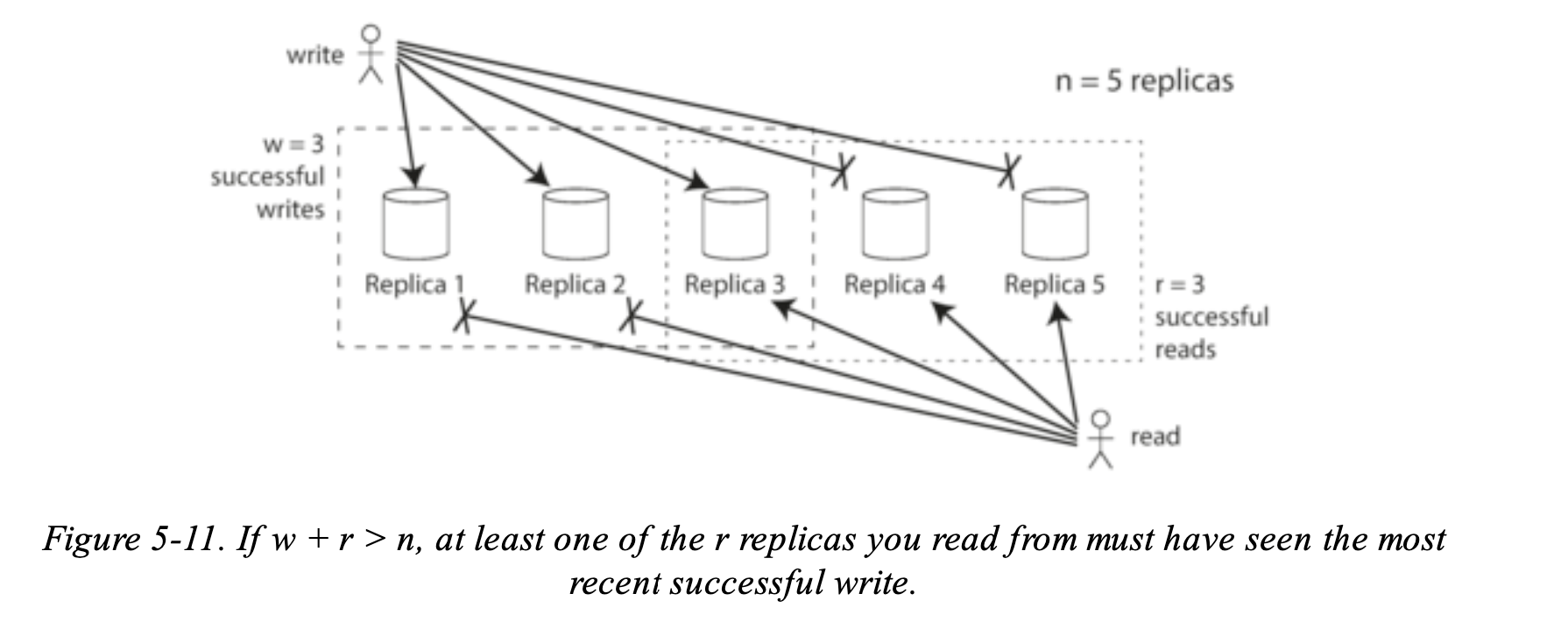
就算可以設定這些參數, read and writes 在送的時候也是要同時送到 all n replicas,w and r 的重點是在於必須要等多少 nodes 而足夠判斷新資料或是寫入成功。
Limitations of Quorum Consistency
前面所說的公式: w + r > n,是因為必須假設每一次 read 的時候,所讀取到 node 會跟 write 的 node 會 overlap,就如同上面那張圖。
因此 Quorum 的概念不是純粹的多數決,這個概念只在於 the sets of nodes used by the read and write operations overlap in at least one node。
Quorum 有一些 edge case 需要考慮:
- 如果使用 sloppy quorum,後面會在提到這個概念,也就是指說 w writes 寫入到不同的 node,而 read 的時候沒有剛好沒有 overlap write node,就會讀取不到新資料
- 如果 two write concurrently 發生,很難決定哪一個 write 是先發生的,最安全的做法是 merge the concurrent writes。如果用 timestamp 會有 clock skew 要考慮,後面會再說。
- 如果 write and read concurrently 發生,有些 write 會成功在某些 replica,這樣 read 也很難判斷讀取到的資料是新的還是舊的。
- 如果 write 成功,但是有些 replica 失敗了,而整體成功的數量小於 w replicas,這個 write 要算是失敗,但是成功的 replica 資料並不會 rollback,也就是說之後的 read 可能會讀到不預期的新資料。
Dynamo-style databases are generally optimized for use cases that can tolerate eventual consistency. The parameters w and r allow you to adjust the probability of stale values being read, but it’s wise to not take them as absolute guarantees。
LeaderLess 的架構下還是會遇到前面所說的 Replication Lag 的問題,並且無法採用 reading your writes, monotonic reads, or consistent prefix reads 來解決,而通常要 Stronger guarantees generally require transactions or consensus。這個後面的章節會在細談。
Monitoring staleness
談談監控這件事,在 leader-based replication 情況下,database 會 exposes metrices 來讓我們發現 replication lag,This is possible because writes are applied to the leader and to followers in the same order, and each node has a position in the replication log (the number of writes it has applied locally). By subtracting a follower’s current position from the leader’s current position, you can measure the amount of replication lag。
在 leaderless replication 架構下,因為沒有 fixed order write,所以要知道 replication lag 會有點困難,而前面提到如果修復 replication lag 是透過 read repair 的話,那就沒有所謂的 replication lag 的 threshold 的概念。
Sloppy Quorums and Hinted Handoff
前面說了 quorum 不少的優點,但是 quorum 無法保證 User 能夠連線到每一個 node,總會有一些 network problem 發生,這樣的話所謂的 w + r > n 的公式就會失效了,有可能 User 能夠 reach 到的 node 數量會小於 w or r。這時候有一些解決方案可以用:
- 如果無法 reach 到 w or r 是不是就乾脆 return error 呢?
- 或者就是接受只能寫入到某些 node,而不用寫到所有活著的 node
第二種方式就稱作 sloppy quorums,意思就是說 write and read 仍舊需要 w and r node 去保證,但是重點是我可以寫入到非 n 裡面的 node 上,作者這邊譬喻為:** 想像你被鎖在你家外面,你能敲你鄰居的門,然後坐在他的沙發上看電視。** 一旦 network 的問題排除後,這些暫時存放的 write 結果就會更新到回復正常的 node,這個動作稱為 hinted handoff。
這樣的優點就是可以增加 write availability,只要有達到 w nodes,但是相反的儘管 w + r > n,還是無法保證 read 最新的 data,因為 w 的 node 會在獨立於 n node 之外。Sloopy quorum 的設定在 Dynamo 是屬於 optional 的,在 Riak 只是 enable by default,而 Cassandra and Voldemort 只是 disable by default。
Multi-datacenter operation
leaderless replication 也很適合用在 multi-datacenter,可以直接看原文比較快:
Cassandra and Voldemort implement their multi-datacenter support within the normal leaderless model: the number of replicas n includes nodes in all datacenters, and in the configuration you can specify how many of the n replicas you want to have in each datacenter. Each write from a client is sent to all replicas, regardless of datacenter, but the client usually only waits for acknowledgment from a quorum of nodes within its local datacenter so that it is unaffected by delays and interruptions on the cross-datacenter link. The higher-latency writes to other datacenters are often configured to happen asynchronously, although there is some flexibility in the configuration。
Riak keeps all communication between clients and database nodes local to one datacenter, so n describes the number of replicas within one datacenter. Cross-datacenter replication between database clusters happens asynchronously in the background, in a style that is similar to multi-leader replication。
Detecting Concurrent Writes
在 Leaderless replication 下有什麼方式可以 Detect Concurrent Write 呢?來個例子:
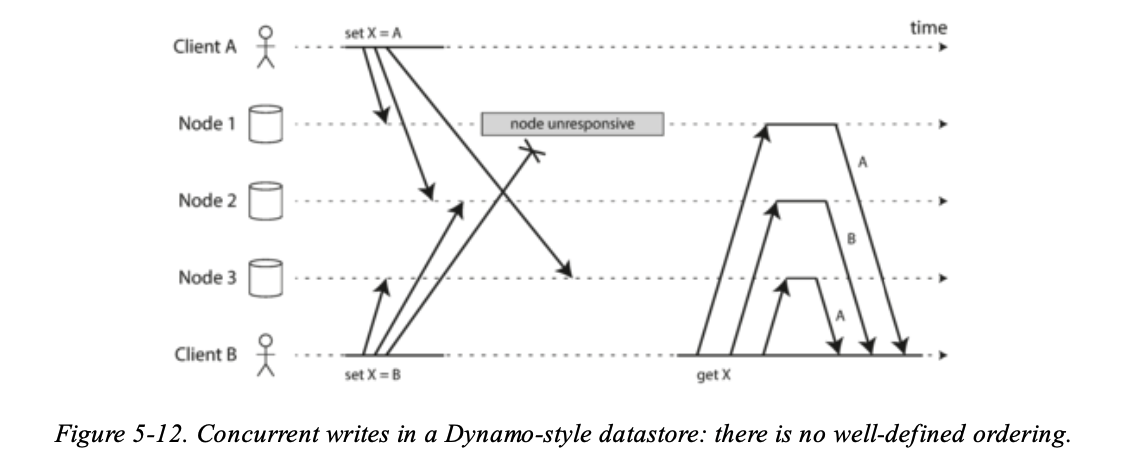
- Node 1 receives the write from A, but never receives the write from B due to a transient outage。
- Node 2 first receives the write from A, then the write from B。
- Node 3 first receives the write from B, then the write from A。
如果每一個 node 都只是採用 overwrite 的話,資料就會變得不一致。目前許多 database 都還沒辦法自動化的處理好這件事情,很多時候需要 application developer 去處理這件事情,那就需要對 database internal 對於 conflict handling 有深入的了解才行。
以下會介紹一些 solution:
Last write wins (discarding concurrent writes)
第一個方法就是最後寫就是老大!這個方法只保留最新的資料並覆寫和捨棄舊的資料,那要怎麼定義最近?可以用 version number or timestamp 來輔助,目前這也是 Cassandra 唯一支持的 conflict resolution。
LWW 的缺點在於如果有許多 concurrent write with the same key,只有一個會成功 write,其他都會被捨棄掉,此外 LWW 就可能會誤判把很接近的 write 去掉,比如說:Timestamps for ordering events。
還有一種情況是要顧慮到 cache,cache 也會因此遺失相對應的資料,如果無法接受掉資料,那麼 LWW 不適合採用。
The only safe way of using a database with LWW is to ensure that a key is only written once and thereafter treated as immutable, thus avoiding any concurrent updates to the same key. For example, a recommended way of using Cassandra is to use a UUID as the key, thus giving each write operation a unique key。
The “happens-before” relationship and concurrency
從上面那張圖可以知道,這兩個 write 不是 concurrent 的,但是要怎麼決定優先順序?
Capturing the happens-before relationship
來看一個購物車的例子:
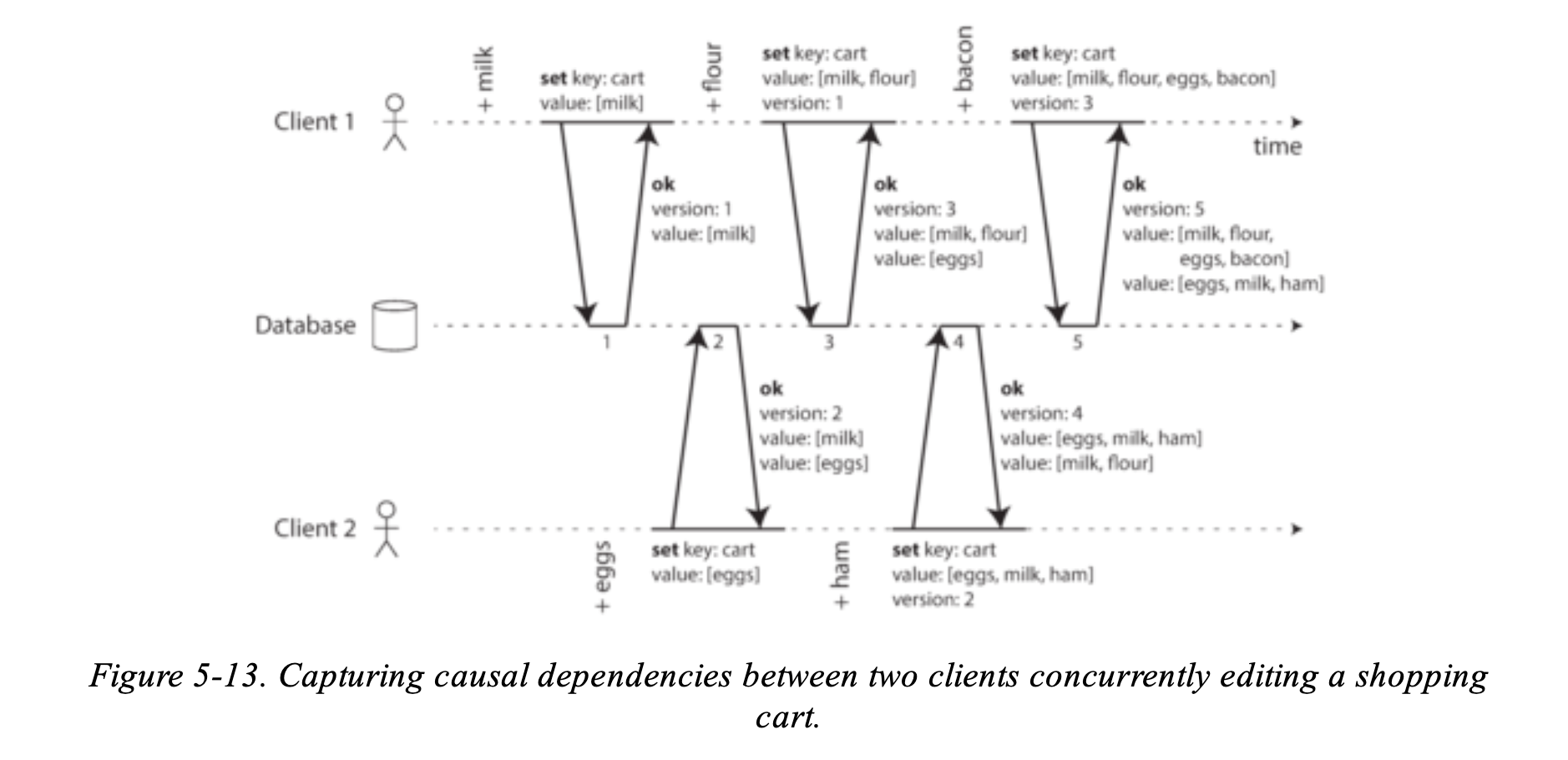
- Client 1 adds to the cart. This is the first write to that key, so the server successfully stores it and assigns it version 1. The server also echoes the value back to the client, along with the version number.
- Client 2 adds to the cart, not knowing that client 1 concurrently added (client 2 thought that its were the only item in the cart). The server assigns version 2 to this write, and stores and as two separate values. It then returns both values to the client, along with the version number of 2.
- Client 1, oblivious to client 2’s write, wants to add to the cart, so it thinks the current cart contents should be . It sends this value to the server, along with the version number 1 that the server gave client 1 previously. The server can tell from the version number that the write of supersedes the prior value of but that it is concurrent with . Thus, the server assigns version 3 to, overwrites the version 1 value , but keeps the version 2 value and returns both remaining values to the client.
- Meanwhile, client 2 wants to add to the cart, unaware that client 1 just added . Client 2 received the two values and from the server in the last response, so the client now merges those values and adds to form a new value, . It sends that value to the server, along with the previous version number 2. The server detects that version 2 overwrites but is concurrent with, so the two remaining values are with version 3, and with version 4.
- Finally, client 1 wants to add . It previously received [milk, flour] and [eggs] from the server at version 3, so it merges those, adds bacon, and sends the final value [milk, flour, eggs, bacon] to the server, along with version number 3. This overwrites [milk, flour] (note that [eggs] already overwritten in the last step) but is concurrent with [eggs, milk, gam], so the server keeps those two concurrent values
資料流可以視覺化成下圖:
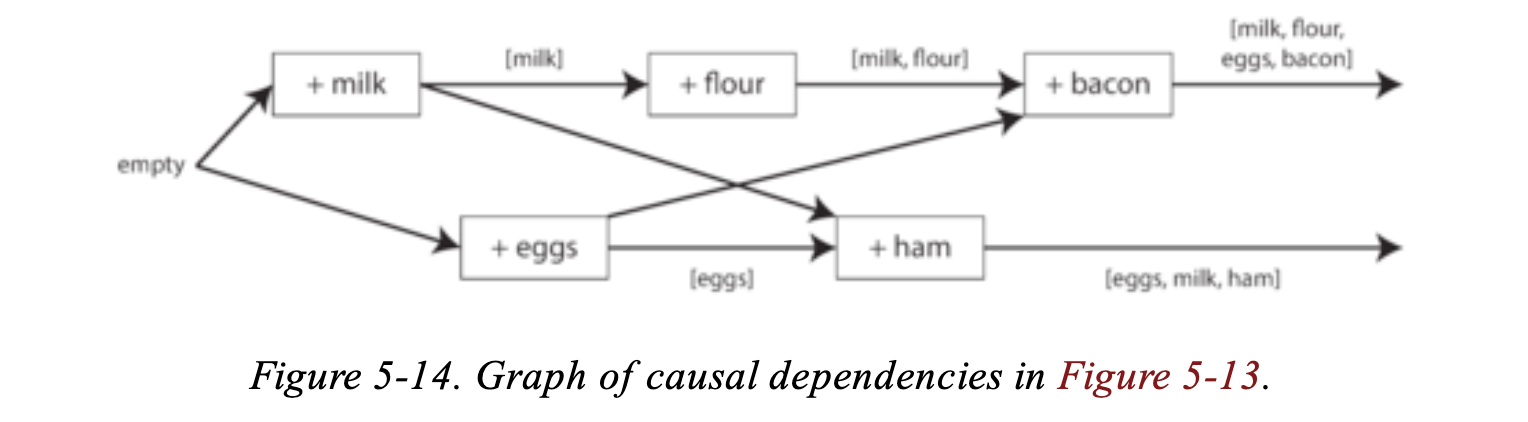
其演算法步驟拆成以下幾步:
- The server maintains a version number for every key, increments the version number every time that key is written, and stores the new version number along with the value written.
- When a client reads a key, the server returns all values that have not been overwritten, as well as the latest version number. A client must read a key before writing.
- When a client writes a key, it must include the version number from the prior read, and it must merge together all values that it received in the prior read. (The response from a write request can be like a read, returning all current values, which allows us to chain several writes like in the shopping cart example.)
- When the server receives a write with a particular version number, it can overwrite all values with that version number or below (since it knows that they have been merged into the new value), but it must keep all values with a higher version number (because those values are concurrent with the incoming write).
Merging concurrently written values
前面這個 merge 的做法,如果改成 User 可以 remove 的話,這樣 union of siblings 的做法就不一定適用了:if you merge two sibling carts and an item has been removed in only one of them, then the removed item will reappear in the union of the siblings。
為了解決這個問題,an item cannot simply be deleted from the database when it is removed; instead, the system must leave a marker with an appropriate version number to indicate that the item has been removed when merging siblings. Such a deletion marker is known as a tombstone。
As merging siblings in application code is complex and error-prone, there are some efforts to design data structures that can perform this merging automatically。以 Riak 的 datatype 有支援這樣的操作,叫做 CRDTs that can automatically merge siblings in sensible ways, including preserving deletions。
Version vectors
前面的圖的情境是指 single replica 的情況,但如果是 multiple replicas 呢?需要在每一個 replica 上使用 version number 作為 key,and also keeps track of the version numbers it has seen from each of the other replicas. This information indicates which values to overwrite and which values to keep as siblings。
這種一群 version numbers 的做法又叫做 version vector,A few variants of this idea are in use, but the most interesting is probably the dotted version vector, which is used in Riak 2.0。
version vectors are sent from the database replicas to clients when values are read, and need to be sent back to the database when a value is subsequently written. (Riak encodes the version vector as a string that it calls causal context.) The version vector allows the database to distinguish between overwrites and concurrent writes.
Also, like in the single-replica example, the application may need to merge siblings. The version vector structure ensures that it is safe to read from one replica and subsequently write back to another replica. Doing so may result in siblings being created, but no data is lost as long as siblings are merged correctly.
總結
結束了 replica 的筆記,但其實有很多書上提供的 reference 可以去看看。這邊做個結論:
為什麼需要做 replication?是因為要: High availability,Disconnected operation,Latency,Scalability。
而 replication 又分為:Single-leader replication,Multi-leader replication,Leaderless replication,再來 replication 資料更新又可以分為同步與非同步的方式。
而 replication 要考慮的問題,其實就是資料一致性,可以用以下的方法去解決 replication lag:
- Read-after-write consistency
- Monotonic reads
- Consistent prefix reads
而 concurrent write 必須要去解決其 conflict,你可以使用盡可能避免 concurrent write 的方式而真的遇到了可以嘗試用 merge 的方式來解決。