Designing Data-Intensive Applications 書本 - Storage and Retrieval 筆記 (1)

今天要來介紹的是 Designing Data-Intensive Applications Chapter 03 的筆記,主題是:Storage and Retrieval,這篇文章涵蓋的內容是圍繞著 index structure 的設計,最後介紹到 B-Tree 與 LSM-Tree 兩者的優缺點及應用場景。
Data Structures That Power Your Database
先來從設計一個最簡單的 database 開始:
1 |
|
這樣就簡單的實現一個以 key-value 的資料庫。
來試試看:
1 | $ db_set 123456 '{"name":"London","attractions":["Big Ben","London |
這樣的儲存方式採用的是透過一個 text file 並且每一行存一筆 key,value 資料,每次新增資料都只會採用 append 的方式,此外也不會 overwrite 相同的 value。
從這個簡單的資料庫我們可以看出以下幾點:
- 新增簡單且寫入的動作因為是 append 的操作非常有效率
- 在實務上還需要考慮 concurrency control, reclaiming disk space, handling error
- 在讀取上的效率卻非常的不好,原因在於當 record 量一多,如果想要讀取到最新的 key value,必須 scan all file line 來找出,時間複雜度為 O (N)
所以在這樣的架構上,我們往往還需要設計一個 structure:index。
index 可以想成是 data 的額外 structure,在現今的資料庫,通常都可以讓我們加入 index structure 來加速我們的 query 的速度,但是由於必須額外維護這個 index structure,因此會影響 write 的速度,因為通常每增加一筆資料,就必須 update index structure。
在後面會介紹,不同的 index structure 所帶來的好處壞處及使用的場景。
Hash Indexes
以 key value 的格式儲存的架構,最常使用的方式莫過於是 hash table。
那如果我們的 index structure 用 Hash table 來實現有沒有搞頭?
以前面說的例子,如果我們將每一個 key 與 file 內的 value 的 byte offset 存在 hash table 上,並且將這個 hash table 存在 memory 上,如下圖所示:
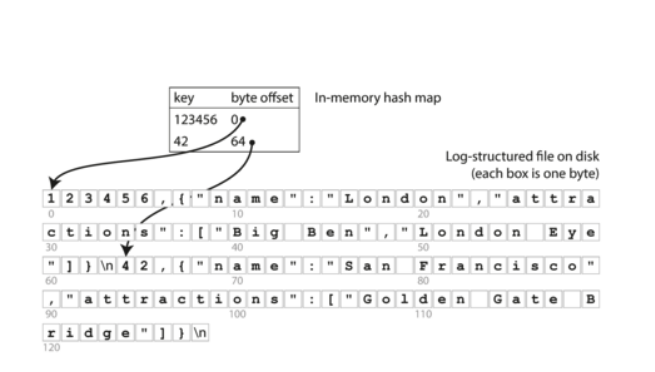
讀取的時候:只需要先讀 hash table 存不存在 key,有的話就可以直接讀 file 的 offset 直接拿到相對應的 value。
寫入的時候:除了要寫入 append 到 file,也需要 update hash table 相對應的 key value。
這樣的做法,有名的 database:Bitcask,查了一下 GitHub 應該是這個:https://github.com/basho/bitcask
來分析一下,這樣的 index structure 改善了什麼:
- 讀取跟寫入的速度都非常的快,在讀取方面通常只需要 one disk io 就可以結束。
- 對於有少量的 keys,且需要常常會更新 key 的 value 的需求非常適合
怎麼避免 disk space running out?
由於每次增加 value 都是採用 append 的方式,並且 file 會有多個 duplicate key 舊的紀錄是不需要保留的,所以好的做法是儲存的時候就是存成好幾個小的 file,並且每隔一段時間會將每個小的 file 進行 compaction,意思就是將 duplicate keys 捨棄掉,保留每一個 key 最新的 value,如下圖:
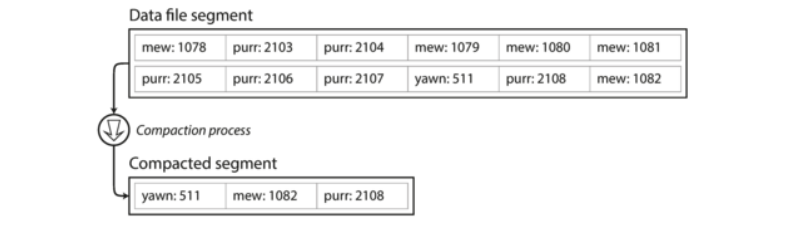
當有很多小的 file segment 的時候,我們在進行 merge several segments together 並且也做 compaction 的動作,如下圖:

分析如下:
- 當 background 執行 merge 過程,可以透過用舊的 file segment 來持續服務 read & write 的需求。而當 merge 結束後會產生一個新的 file segment,這時候就可以 switch 新的 read & write 到新的 segment,舊的 segment 就可以刪除掉了,透過這些步驟就可以節省 disk space。
- 每一個 segment 有其各自維護的 hash table,所以 read 的操作會變成先從 recent segment’s hash map 開始讀取,直到 hash map 檢查完畢。
- merge preocess 會讓 segments 維持較小的數量 l,來確保 read 的操作,不用讀取太多的 hash map。
實際設計上還需要考量到的 issue
-
File format
在前面的設計是用類似 csv 的格式,這樣的方式並不好,最快速且簡單的方式應該要使用 binary format。
-
Deleting records
如果需要刪除 record,需要加入一個 deletion record 來代表之後進行 merge process 要忽略這些 deletion record。
-
Crash recovery
如果 database crush or restarted,加上 hash map 這些資料都是存在 memory,這些資料會不見,有兩種做法:
- database 開始前先將所有 segment 讀取到 hash map 上,但是這樣會花費不少時間
- Bitcask 的作法是會將所有的 segment 的 hash map 的 snapshot 存在 disk 上,這樣重新存回 memory 可以更快速。
-
Partially written records
當 write 操作進行到一半的時候,database crush 會造成 partially written records,Bitcask 的作法是在寫入操作的時候會加上 checksum 的機制,這樣 corrupted data 的部分可以被偵測到且忽略掉。
-
Concurrency control
因為 write 是 append 操作,會是一個 sequential order 的行為,最好的 concurrency control 會是每個時間只能有 one writer thread,但是 read 的話可以 multiple threads
Hash Table Index Structure 的缺點
- hash table 因為是存在 memory,如果有大量的 keys 就不好說了
- range queries 速度慢,比如說我要掃描 keys 從
kitty00000 to kitty 99999,必須對每一個 key 進行個別的 hash map 的讀取,效率並不好。
SSTables and LSM-Trees
那麼如果我們的 key, value 是按照 key 排序來排的話呢?有沒有搞頭~?
我們稱之為 Sorted String Table (SSTables),並將 Hash index structure 搭配使用:
-
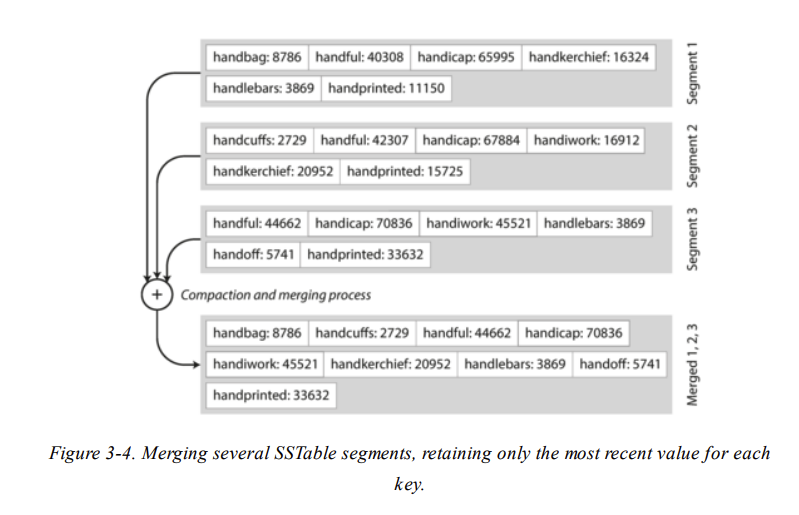
在 merge multiple segments 的時候採用 mergesort 的方式來合併,如下圖:
![figure4]()
根據每一個 sorted segment merge 出一個同樣 sorted 的 segment
-
要怎麼找出 particular key in the file?尤其是這個 key 不在 memory hash table 上
由於我們的 file 已經經過 sorted 了,所以可以根據這個 key 的臨近 key 的 values 去判斷在哪一個 segment file,這樣就能大幅提升找到某個 key 的速度。因為這樣的設計,整個 Hash table 的 key 可以呈現 sparse 的狀態,例如 Hash table 都會記錄每一個 segment 的 key,我們可以假設每個 segment 的 size 不大,這樣當我們要找某一個特定的 key 所處的 segment 都可以快速從 Hash table 快速定位到。
Constructing and maintaining SSTables
說起來簡單,但是實際上 write 的時候要怎麼保持 sorted 的呢?我們可以採用 B-Tree structure 來實現。常聽到的 balanced tree 常見的有:AVL、紅黑樹、B 樹
這篇文章有詳細的解釋這些 tree 結構的差別:https://z1nhouse.github.io/post/5lQAWUQWk/
在寫入的時候可以改成這樣設計:
- 在 memory 維護一個 in-memory balanced tree data structure,稱為 memtable
- 當 memtable size 超過某 threshold 時,將 memtable 資料寫入 disk
- 由於 memtable 採用 balanced tree,因此 write 到 disk 都是已經 sorted 過的
讀取的時候:
- 一樣先從 memtable 開始讀取,當讀取不到則再去 disk 讀取。
Background task:
- 背景一樣會固定執行 merging and compaction 多個 segment
這樣設計的缺點:
-
如果 write to disk 這段,crushed 掉了,會導致 memtable 有資料,disk 沒資料
這邊可以透過 append 的操作寫入 log file 紀錄操作,用來 restarted 回復操作用
當 memtable 的資料成功寫入 disk,則對應 log 紀錄就可以 discard 掉了
Making an LSM-tree out of SSTables
前面所說的 SSTables 的方式,衍伸出之後的 LST-tree,這個名詞來自於 《The Log-Structured Merge-Tree (LSM-Tree) 》論文首次提出,但真正得到廣法應用是在 2006 年 Google Bigtable 論文,論文中提到 Bigtable 使用的資料結構就是 LSM-Tree。其設計原理就是用到 SSTables + memtable 的方式。
LSM-Tree 被應用到知名的 Bigtable、Cassandra、HBase、RocksDB、LevelDB 等等資料庫的底層引擎。
Performance optimizations
這邊整理一下他的應用場景及優缺點:
- 寫入速度非常快,因為對硬碟的寫入操作是採用 Append Only,對於硬碟而言順序寫入會比隨機寫入還要快很多
- 犧牲讀取性能,因為當在 memtable 找不到的時候,雖然可以透過 sorted 的結構找出鄰近 key 所處在的 segment file,但是在 file 尋找的時候還是需要一個一個 scan 找出相對應的 value
- 可以加入 bloom filter 來改善讀取的性能,bloom filter 用在告訴我們這個 segment file 有沒有對應的 key,但是 bloom filter 有機率性的會誤判。
- 因為資料是 sorted 過了,所以對於 range query 的速度有一定程度的提升
這邊提一下也有不同的策略來實施 SSTables 的 compacted and merged
- LevelDB and RocksDB 採用 leveled compaction
- HBase and Cassandra 採用 sizetiered and leveled compaction
B-Trees
接著來介紹採用 B-Tree 的架構下的 index structure,以下為 B-Tree index structure 的特點:
-
B-tree keep ke-value pairs sorted by key
-
提供有效率 key-value lookups and range query
-
B-tree 通常會把 database 內的資料分成 fixed-size blocks or pages,常見的資料庫會採用 4KB in size
-
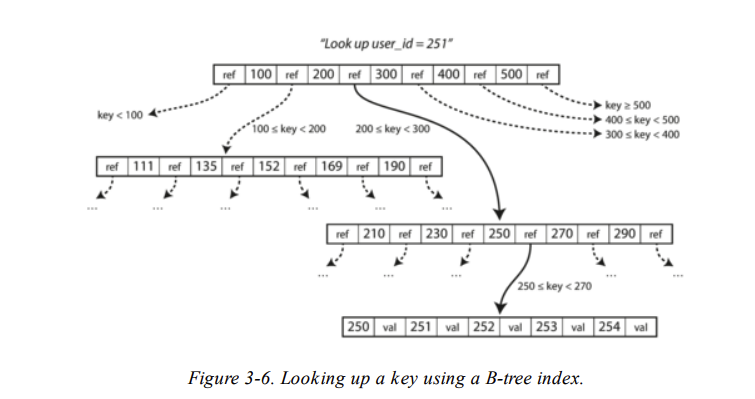
Each page can be identified using an address or location, which allows one page to refer to another—similar to a pointer, but on disk instead of in memory. We can use these page references to construct a tree of pages
如下圖:
![figure5]()
-
如果想要加入新的 key,需要找出對應的 page,如果該 page 沒有足夠的空間,則該 page 會分裂成兩個 page,如下圖:
![figure6]()
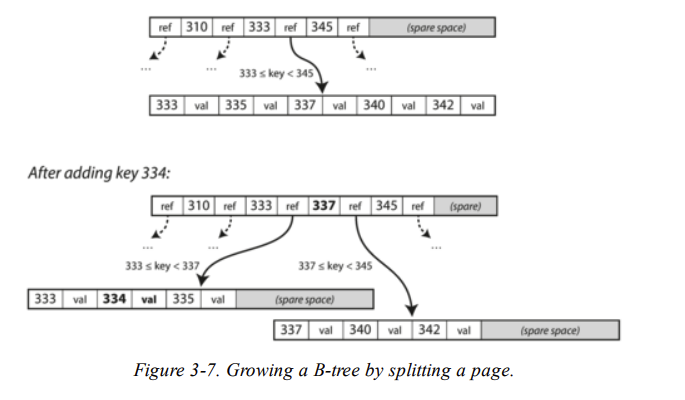
Making B-trees reliable
為什麼現今很多關連式資料庫是採用 B-tree 的結構?有以下特點:
-
沒有 duplicate key 的問題,採用 overwrite data 的方式,所以不需要改變 page 的 location,因此不同於前面的 LSM-tree 是採用 append 的方式 write
-
當 split a page 的時候需要額外花 cost 將原本 parent page 上的 data 分到另外兩個 pages 上,但是這時候如果 database crash 的話會造成嚴重的後果,因此這時候會多引入 Write-Ahead Logging 結構 通常也稱為 redo log,這個 log file 是採用 append 操作,在現在的資料庫在寫入的操作並不會真的把資料先寫入 disk 才回傳成功,而是先將寫入的操作透過快速的 io append 操作記錄起來,就回傳成功,真正寫入到 disk 這塊,是 backgrond task,而當 database crash 的話,也是透過 redo log 來將 b-tree 上的資料回到正確的狀態。
可以參考 Postgres 文檔 對 WAL 的講解:https://www.postgresql.org/docs/13/wal-intro.html
B-tree optimizations
這本書有提到改善 B-tree 結構的一些方式:
-
用 copy-on-write scheme 來取代 WAL,這個概念衍生出 MVCC 的理論!
可以參考這個文章:http://wiki.dreamrunner.org/public_html/C-C++/Library-Notes/LMDB.html
-
將 key 進行壓縮,也就是在 page 上可以存放更多 key,減少分裂的機率
-
將 page leaf 按照 sequential order 在 disk 上,但是當 B-tree 越來越大時很難 maintain 這個 order,而 LSM-tree 反而比較容易這樣的效果
-
將每個 leaf pages 與其 sibling pages 透過 pointer 連接再一起,這樣 scan 的時候就不用跳回 parent page 再跳到 sinling page 了
Comparing B-Trees and LSM-Trees
這兩種結構各自應對場景有所不同,一般來說,B-Tree 擅長 read heavy 的需求,LST-Treee 擅長 write heavy 的需求。
那我們來細看一下優缺點:
-
B-Tree 基本都會需要兩次 IO,一個是寫 write-head log,一個是寫 tree page 本身的 data,當然還需要面對 page split 的情況,寫入還常常會用到 random write 的方式,有時還需要 write an entire page,儘管 page 上面的資料只是做了一些小資料的更動。
-
LSM-Tree 寫入這段不是用 page 的架構,再來寫入是透過 sequential write 的方式,速度會更快
-
LSM-Tree 採用壓縮的方式可以比 B-Tree 更有效,B-Tree 設計的方式還需要處理 disk space fragmentation 的問題,因為當 page split 的時候,要寫一個新的 page,舊的 page 可能會剩下一點空間無法利用到。
-
在讀取方面,由於 B-tree 不會有 multiple key 的問題,像 LSM-Tree 可能會有許多 duplicate key 在不同 segment,所以在實施 concurrent control 的時候,B-tree 相對於 LST-Tree 更有效率,也因此為什麼關連式資料庫都是採用 B-Tree 居多,可以實施豐富的 transaction 級別。
-
這邊提到了寫入放大跟讀取放大的問題,我查了一下發現這篇文章有做 LSM-Tree 與 B-Tree 的比較:
https://tikv.org/deep-dive/key-value-engine/b-tree-vs-lsm/
總的來說,B-Tree 的讀放大比 LSM-Tree 小,而 LSM-Tree 樹的寫放大比 B-Tree 小。
總結
今天介紹了從最簡單的 database 設計到,加入 Hash Index 結構,最後演變成 SSTable,而產生最後的 LSM-Tree,以及現在關連式資料庫常用的 B-Tree 兩者之間的差別。
事實上,個人覺得 LSM-Tree 就是在 memory 採用 B-Tree 概念 + Disk 用 SSTable 的概念做成的,B-Tree 則是在 Disk 用 B-Tree 的結構做成的,此外這邊也提到 WAL 的作法來避免 database crash 的問題,很重要的概念。
非常豐富的內容~