Postgres - zero-downtime migration 該注意的細節

強者我同事,最近在公司分享 zero-downtime migration 的細節,避免以後我們上了 migration 使得 Production Postgres 被 lock 住,這樣會讓我們的整個服務,會無法使用。
聽完我覺得這些細節寫成筆記記錄下來比較好,避免自己犯了相同的錯誤。因為公司用的資料庫是 Postgres,所以文章內的例子都是用 Postgres 來示範的~
何謂 zero-downtime migration
migration 的重要性
先從 migration 這個名詞開始解釋,通常每一個專案下面有用到資料庫,都會有所謂的 migration 檔案,這個 migration 檔案通常是 .sql 檔案,也就是說我們必須紀錄下每一次對資料庫操作的 SQL 指令,一開始專案可能會是單純 CREATE TABLE,之後隨著專案需求的改變,我們可能會新增 column,每一次的指令操作都必須做成 migration 檔案來記錄,之所以需要這樣做是因為如果沒有這些紀錄,我們手動修改了資料庫,就必須同步通知其他開發者,這樣很不方便的,相對的,如果有檔案我們就能做版本控制,我們也可以透過 migration 進行 rollback SQL 指令的操作,另外有這些紀錄我們才能更好的做 code review,而當資料庫出事的話也更好追蹤是哪個 migration 的指令導致的問題。
zero-downtime migration 的重要性
要知道每個 migration 操作通常都會包著 transaction 來執行,才能確保操作能夠成功或是能夠被 rollback 回去,但是在生產環境下進行 migration 的時候,同時可能有很多 transaction 正在運行,如果 migration transacation 是一個 long-running queries,或是很多時候 migration 指令會是要更改 table 的欄位,那麼是會造成這個 migration 需要用到 exclusive lock,會導致其他 transaction 需要等待這個 migration 釋放 lock 才可以繼續下去,這樣就無法做到 zero-downtime migration。我們希望做 migration 必須能夠盡可能不佔用過多資源,讓生產環境正常的 transaction 可以持續運作,避免 migration 用到 lock 的行為。
需要避免的 migration 的指令
這邊會列出一些不應該放在 migration 的指令,或是盡量在非 peek 的時段操作,盡可能達到 zero-downtime migration。
將需要長時間運行的 query 分成幾個 batch 去執行
比如說,你有一個 migration 指令是要修正資料,所以你可以會需要 UPDATE 好幾筆資料,如果資料量很大,建議可以分成好幾個 batch 去跑,而不要全部一次擠在一個 migration 指令上。因為要知道當你 UPDATE 每一筆資料的時候都會需要跟 Database 拿 Lock,那會導致另外一個要 UPDATE 同一筆 record 的 transacation 被迫等待 migration 釋放 Lock 才可以繼續,所以拆成好幾個 batch 去跑是會有好處的,盡可能的讓 migration 擁有 Lock 的時間越短越好。
比如說,來看個例子:
現在我先 CREATE 一個 users table:
1 | CREATE TABLE users (id serial not null primary key, name varchar(10) not null); |
並且 insert 兩筆資料:
1 | INSERT INTO users (name) VALUES('kenny'); |
然後我現在會需要用兩個 psql session 去連接 Postgres 去展示當有一個是 migration 指令以及另一個是生產環境正常的 transaction,這兩個 transaction 同時都要更新相同的 record。
在開始以前,我們必須先知道這兩個 transaction 所用的 process id (pid),這樣等一下我們可以透過查詢 pg_locks 跟 pg_stat_activity 這兩個 table 去看出現在是不是產生前面所說等待 lock 的行為,也就是其中有一個 transaction 要等待另外一個釋放 Lock。
-
migration 指令的 process id
1
2
3
4
5migration-demo=# select pg_backend_pid();
pg_backend_pid
----------------
5494
(1 row) -
其他正常 transaction 的 process id
1
2
3
4
5migration-demo=# select pg_backend_pid();
pg_backend_pid
----------------
6221
(1 row)
透過查詢 select pg_backend_pid() 可以知道當前的 connection 所使用的 pid 為多少。
接著來做個實驗:我的 migration 指令是要更改 id = 1 的 record:
1 | migration-demo=# BEGIN; |
ok,我們的 transaction 先不要 COMMIT,故意讓這個 migration 指令長時間擁有 exclusive lock。
接著再用另外一個 transaction 去 UPDATE 相同的 record:
1 | migration-demo=# UPDATE users SET name = 'Kenny' WHERE id = 1; |
這時候會發現:這個 transaction 被 block 住了,無法成功的 UPDATE 就一直卡著,等待 migration transaction 釋放 lock 才可以繼續下去,這邊用多個空行代表它真的被卡住了。
這時候我們查詢 pg_locks table:
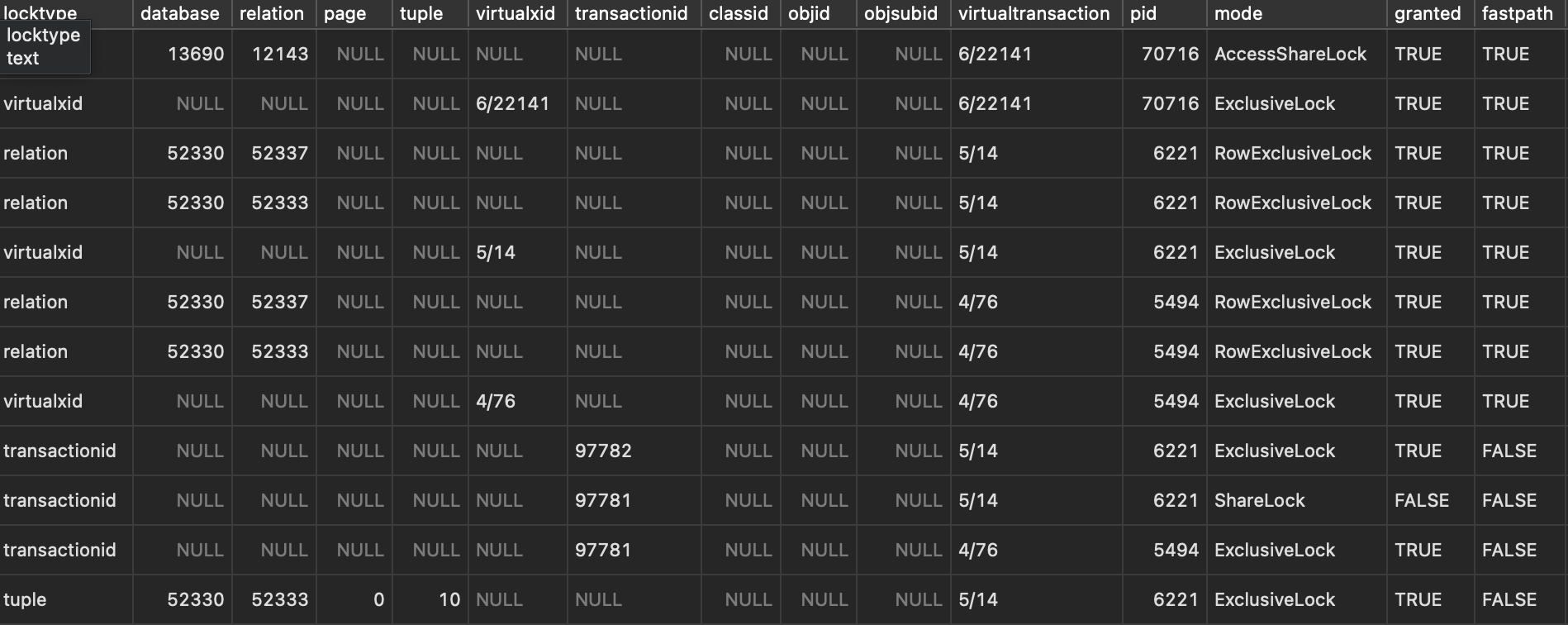
我們主要看的是 locktype,pid,mode,granted 這些欄位,在下面當 locktype = transactionid and pid = 5494 or 6221 and granted = TRUE or FALSE。
前面可以知道 migration transaction pid = 5494 它拿了 Exclusive Lock,而 正常 transaction pid = 6221 它拿了 ShareLock,並且它的 granted 是 FALSE 這個欄位代表它無法獲取 Lock:
Postgres 官方解釋:True if lock is held, false if lock is awaited
OK,所以可以知道 ShareLock 與 Exclusive Lock 彼此是有 Conflict,所以才會導致有等待的行為出現,來看看官方文件的說法:https://www.postgresql.org/docs/12/explicit-locking.html
其中有個最重要的表格可以參考:
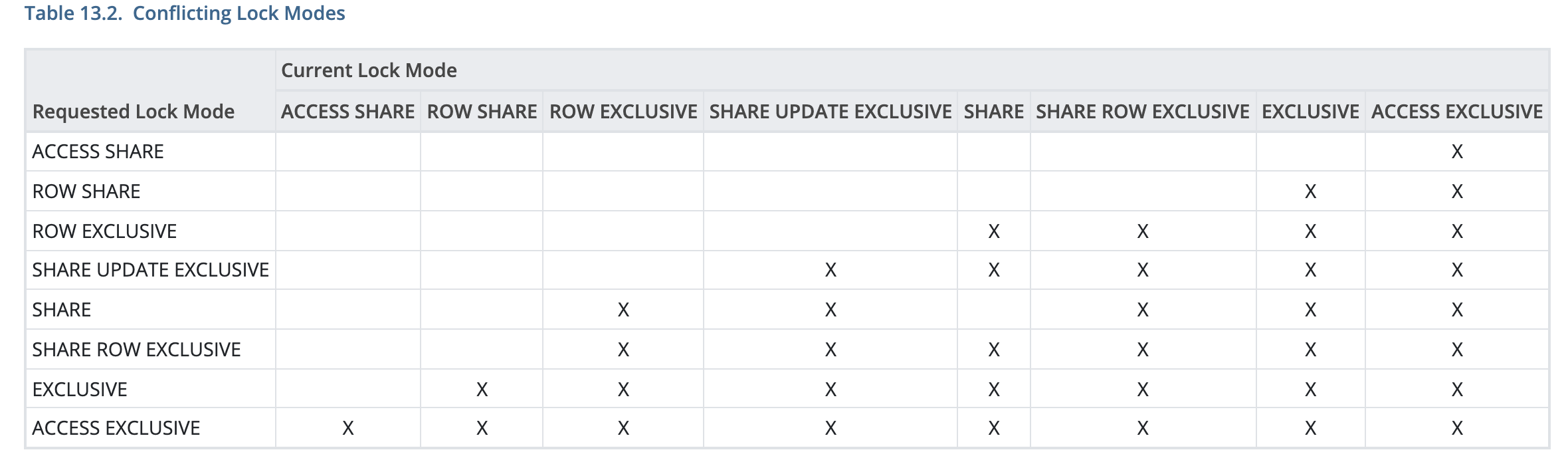
打 X 代表有 Conflict。這邊附上官方解釋 ShareLock 與 Exclusive Lock 定義:
Share:Conflicts with the
ROW EXCLUSIVE,SHARE UPDATE EXCLUSIVE,SHARE ROW EXCLUSIVE,EXCLUSIVE, andACCESS EXCLUSIVElock modes. This mode protects a table against concurrent data changes. Acquired byCREATE INDEX(withoutCONCURRENTLY).EXCLUSIVE:Conflicts with the
ROW SHARE,ROW EXCLUSIVE,SHARE UPDATE EXCLUSIVE,SHARE,SHARE ROW EXCLUSIVE,EXCLUSIVE, andACCESS EXCLUSIVElock modes. This mode allows only concurrentACCESS SHARElocks, i.e., only reads from the table can proceed in parallel with a transaction holding this lock mode. Acquired byREFRESH MATERIALIZED VIEW CONCURRENTLY.
這兩種 LOCK 都是屬於 Table-Level Locks。
接著我們再來看 pg_stat_activity table 會顯示什麼,因為這個 table 本身欄位很多,這邊我只選擇我們只需要關注的:
1 | select pid, wait_event_type, wait_event, state, query from pg_stat_activity; |
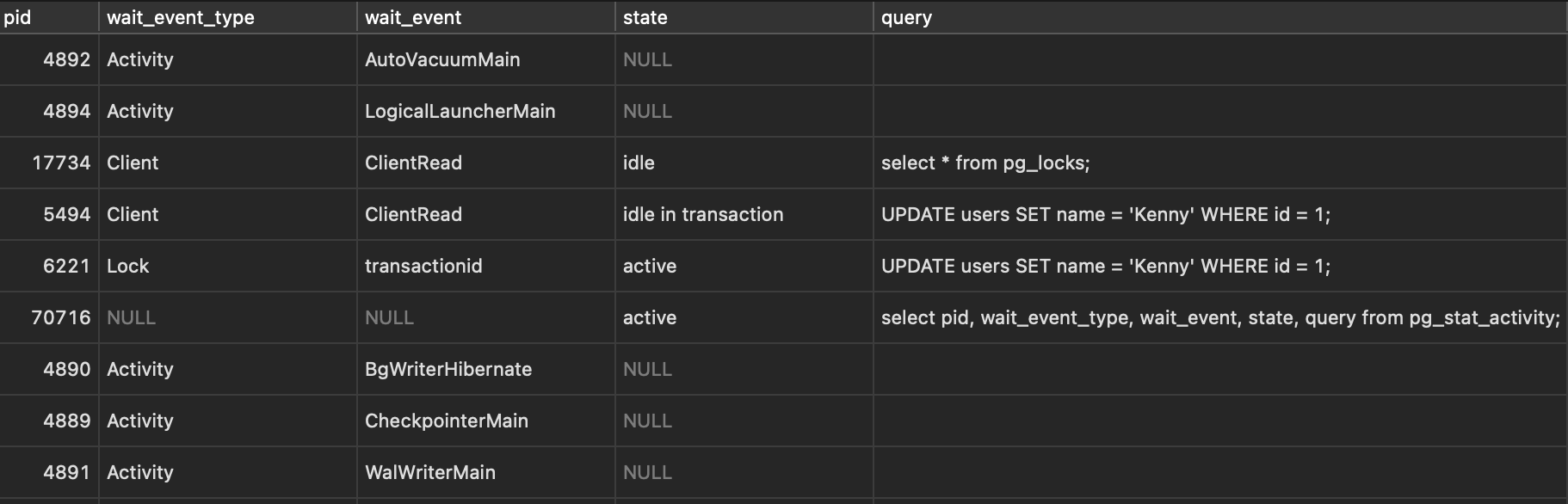
看看中間兩筆 record,兩個 pid 符合我們要找的,並且重點是看一下 wait_event_type 一個是 Lock 一個沒有值,代表這個 6221 這個 process 正在等待獲取 Lock。
注意一下: wait_event 跟 wait_event type 欄位 是在 Postgres 9.6 之後才開始引入。
所以我們知道只要我們查看這兩個表就可以知道現在有哪些 query 被 block,無法獲取 lock 等行為,所以如果 migration 指令現在立刻 COMMIT,就可以看到其他 transaction 可以繼續下去而不會被阻擋。
1 | migration-demo=# BEGIN; |
1 | migration-demo=# UPDATE users SET name = 'Kenny' WHERE id = 1; |
這時候再去查 pg_locks and pg_stat_activity 就會發現狀態改成成功獲取 lock 並且沒有等待的狀況發生。
Update rows 使用相同順序
如果今天有兩個 transaction 分別需要執行以下的動作:
1 | # transaction 1 |
這樣的狀況會導致如果 transaction 1 locks row 1 的時候 transaction 2 locks row 2,兩邊會互相等待對方的 lock,導致 deadlock 產生,所以更新的時候最好採用相同的順序。
來看看示範:
1 | migration-demo=# BEGIN; |
1 | migration-demo=# BEGIN; |
這邊的話你會看兩邊的 transaction 都被 block 住,而根據 Postgres 的參數: deadlock_timeout
看一下官方解釋:https://www.postgresql.org/docs/12/runtime-config-locks.html
deadlock_timeout(integer):This is the amount of time to wait on a lock before checking to see if there is a deadlock condition. The check for deadlock is relatively expensive, so the server doesn’t run it every time it waits for a lock. We optimistically assume that deadlocks are not common in production applications and just wait on the lock for a while before checking for a deadlock. Increasing this value reduces the amount of time wasted in needless deadlock checks, but slows down reporting of real deadlock errors. If this value is specified without units, it is taken as milliseconds. The default is one second (
1s), which is probably about the smallest value you would want in practice. On a heavily loaded server you might want to raise it. Ideally the setting should exceed your typical transaction time, so as to improve the odds that a lock will be released before the waiter decides to check for deadlock. Only superusers can change this setting.When log_lock_waits is set, this parameter also determines the amount of time to wait before a log message is issued about the lock wait. If you are trying to investigate locking delays you might want to set a shorter than normal
deadlock_timeout.
我們可以知道:當兩個事務發生 deadlock,Postgres 不會立即解決問題,而是等待 deadlock_timeout 再觸發死鎖檢測算法解決問題。為什麼 PostgreSQL 在介入並修復問題之前要等待一段時間?原因是死鎖檢測非常昂貴,因此不立即觸發它。此處的默認值是 1 秒,該值足夠高,可以避免無意義的死鎖檢測嘗試,但仍然足夠短,可以有用且及時地解決問題。
所以你會在其他一個 transaction 看到這樣的錯誤:
1 | migration-demo=# UPDATE users SET name = 'kenny' WHERE id = 1; |
也代表 COMMIT 之後這個 transaction 會被 ROLLBACK。
新增 Column 要注意的細節
migration 最常做的通常會是新增 Column 的指令,反而前面的更新資料會比較少看見,事實上也不太建議在 Migration 去做,因為更新資料會是比較即時而且建議由有經驗的 engineer 去操作比較好,不適合每個專案的去用 migration 去做這件事情,依我之見,也許是放測試資料在測試環境才會需要用到。
在 Postgres 操作新增欄位要特別注意,是因為會有版本的差異,我們來看個例子:
1 | # 新增欄位,並且該欄位可為 NULL |
Postgres 11 版本以前:
-
在新增欄位的時候如果是可以 NULL 的話,這個 migration 本身是安全的,為什麼呢?它不需要 rewrite 整個 table 的每一筆現有 record 的 is_suspend 的值。
-
新增欄位如果是 NOT NULL,首先如果沒有放 DEFAULT 的話,這個 migration 本身就會失敗,因為會出現以下的錯誤:
1
ERROR: column "is_suspend" of relation "users" contains null values
這個很合理,這個錯誤無關版本的差別,因為你現有的資料本身就沒有這個欄位,一但你新增這個欄位,你又沒有給 DEFAULT 值又限制說是 NOT NULL,那這個 migration 一定會失敗。
-
新增欄位是 NOT NULL 又給 DEFAULT 值,在 11 版本以前這樣會 rewrite 整個 table,去幫每一筆 record 加上 DEFAULT 值的欄位,如果你的資料有上百萬 record 那麼這整個 table 就會被 lock 住,其他正常的 transaction 就會被迫阻擋住,而你的 migration 指令也會運行很久。
所以常常小系統上這種 migration 沒事,不是因為你的做法是對的,而是你的資料量根本不大,你 migration 會跑很快,讓你永遠無法察覺出這樣的錯誤。
看一下 Postgres 9.6 官方解釋:
When a column is added with
ADD COLUMN, all existing rows in the table are initialized with the column’s default value (NULL if noDEFAULTclause is specified). If there is noDEFAULTclause, this is merely a metadata change and does not require any immediate update of the table’s data; the added NULL values are supplied on readout, instead.Adding a column with a
DEFAULTclause or changing the type of an existing column will require the entire table and its indexes to be rewritten. As an exception when changing the type of an existing column, if theUSINGclause does not change the column contents and the old type is either binary coercible to the new type or an unconstrained domain over the new type, a table rewrite is not needed; but any indexes on the affected columns must still be rebuilt. Adding or removing a systemoidcolumn also requires rewriting the entire table. Table and/or index rebuilds may take a significant amount of time for a large table; and will temporarily require as much as double the disk space.
Postgres 11 開始:
- NOT NULL DEFAULT VALUE 不會 rewrite 整個 table
看一下 Postgres 11 官方解釋:
When a column is added with
ADD COLUMNand a non-volatileDEFAULTis specified, the default is evaluated at the time of the statement and the result stored in the table’s metadata. That value will be used for the column for all existing rows. If noDEFAULTis specified, NULL is used. In neither case is a rewrite of the table required.Adding a column with a volatile
DEFAULTor changing the type of an existing column will require the entire table and its indexes to be rewritten. As an exception, when changing the type of an existing column, if theUSINGclause does not change the column contents and the old type is either binary coercible to the new type or an unconstrained domain over the new type, a table rewrite is not needed; but any indexes on the affected columns must still be rebuilt. Adding or removing a systemoidcolumn also requires rewriting the entire table. Table and/or index rebuilds may take a significant amount of time for a large table; and will temporarily require as much as double the disk space.
所以要看自己專案是用哪種 Postgres 版本去決定新增欄位的方式,通常還是會建議,將這些 Migration 也許分成幾步去做,例如:
ALTER TABLE users ADD COLUMN is_suspend BOOLEAN;UPDATE users SET is_suspend = FALSE;ALTER TABLE users ADD COLUMN is_suspend BOOLEAN NOT NULL;
如果第二步驟有很多資料要更新,也可以前面所說的方式,batch 上去 migration,盡可能地降低 migration 的時間。當然如果版本有支援就可以直接上 DEFAULT VALUE 了!
Reference Foreign Key 要注意的細節
除了新增 column,還很常見的是會需要 CREATE TABLE,而 CREATE TABLE 就可能會用到 REFERENCE 的 CONSTRAINT 來參考 Foreign Key,這樣的指令會阻擋被參考的 table update 操作,也就是同時如果有好幾個 transaction 要更改被參考的 table 的 record 就會被 block 住,我們來看個例子:
-
UPDATE one record (pid = 93054)
1
2
3
4
5migration-demo=# BEGIN;
BEGIN
migration-demo=# UPDATE users SET name = 'kenny' WHERE id = 1;
UPDATE 1
migration-demo=#這邊我故意這個 transaction 不 commit,讓這個 transaction 擁有 lock 很久。
-
CREATE addresses Table (pid = 93136)
1
2
3migration-demo=# BEGIN;
BEGIN
migration-demo=# CREATE TABLE addresses (id serial, user_id integer NOT NULL REFERENCES users(id) ON DELETE CASCADE ON UPDATE CASCADE, address TEXT NOT NULL);
1 | 這邊有空行就代表這個 CREATE TABLE 指令無法成功,被阻擋住了。 |
這樣的話,原本建立 index 的操作就不會阻擋寫入操作,CONCURRENTLY 主要會做兩件事情:
- 需要對該 table 掃描兩次
- 在掃描其中都必須等待現有 transaction 完成操作
因為這樣的原因,CREATE INDEX CONCURRENTLY 會花費較多的時間及 CPU。如果在掃描表時出現問題,例如死鎖或唯一索引中的唯一性違規,該 CREATE INDEX 命令將失敗,但會留下 “無效” 索引 (INVALID INDEX)。
看看 Postgres 官方怎麼說:https://www.postgresql.org/docs/12/sql-createindex.html
Building Indexes Concurrently:
Creating an index can interfere with regular operation of a database. Normally PostgreSQL locks the table to be indexed against writes and performs the entire index build with a single scan of the table. Other transactions can still read the table, but if they try to insert, update, or delete rows in the table they will block until the index build is finished. This could have a severe effect if the system is a live production database. Very large tables can take many hours to be indexed, and even for smaller tables, an index build can lock out writers for periods that are unacceptably long for a production system.
PostgreSQL supports building indexes without locking out writes. This method is invoked by specifying the
CONCURRENTLYoption ofCREATE INDEX. When this option is used, PostgreSQL must perform two scans of the table, and in addition it must wait for all existing transactions that could potentially modify or use the index to terminate. Thus this method requires more total work than a standard index build and takes significantly longer to complete. However, since it allows normal operations to continue while the index is built, this method is useful for adding new indexes in a production environment. Of course, the extra CPU and I/O load imposed by the index creation might slow other operations.
如何檢測無效索引?
可以運行以下指令:
1 | SELECT * FROM pg_class, pg_index WHERE pg_index.indisvalid = false AND pg_index.indexrelid = pg_class.oid; |
可參考:
- https://www.postgresql.org/docs/12/catalog-pg-index.html
- https://www.postgresql.org/docs/12/catalog-pg-class.html
如何重建無效索引?
- 使用 REINDEX CONCURRENTLY 命令
- DROP INDEX AND CREAYE INDEX CONCURRENTLY
差別在於第一種方式:Postgres 必須對需要重建的每個索引執行兩次表掃描,並等待可能使用該索引的所有現有事務的終止。此方法需要比第二種需要花費更多 cost,所以需要更長的時間才能完成,因為需要等待可能修改索引的未完成事務。
Migration 失敗了,怎麼砍掉?
不管怎樣當 migration 卡住了,我們最終目標是要趕快找出來,並且將其 transaction kill 掉,那要怎麼找出來呢?
這邊有找到別人分享的好用 query:http://big-elephants.com/2013-09/exploring-query-locks-in-postgres/
1 | SELECT |
這樣我們馬上就可以找到被阻擋的 pid 以及誰阻擋的 pid 以及 query 為何,快速找出元兇:

找出來 pid 後,要怎麼 kill 呢?有兩種方式:https://www.postgresql.org/docs/12/functions-admin.html
-
pg_cancel_backend(pid int)
這會取消當前的 query,但是不會 kill 這個 process,所以不會終止 connection,並發出 SIGINT。
-
pg_terminate_backend(pid int)
這是會整個砍掉 process,並發出 SIGTERM。
所以當要終止 migration 的話,應該要整個砍掉,使用 pg_terminate_backend,避免佔用 connection。
總結
今天介紹了 migration 常見的錯誤以及如何去避免,所以當你發現 migration 上線後,整個 Postgres 的 connection 爆了,也許就該使用那個 query 查查看,是不是因為 migration 的原因造成的。
我整理得好累…QQ