資料分析系列 - 探討決策樹 (1)
/cover.png "confer")
新的系列新的痛苦,因為這學期碩士課程中,我選修了一堂資料探勘的課,所以又要熟悉資料分析的一些理論及如何去用 Python 去實踐。
何謂決策樹
顧名思義,可以把它想成是樹狀圖的概念,正因為類似於樹圖,這個分析的過程很直覺也很簡單,也常常被用在分類的預測。它也是機器學習中監督式學習的一種,簡單來說就是在預設的分類下將一個物件透過條件一步一步地做決策將其分類到對應的分類裡面,而這個過程就是決策樹產生的過程。
看個例子
以我課堂上的例子去做舉例的話:
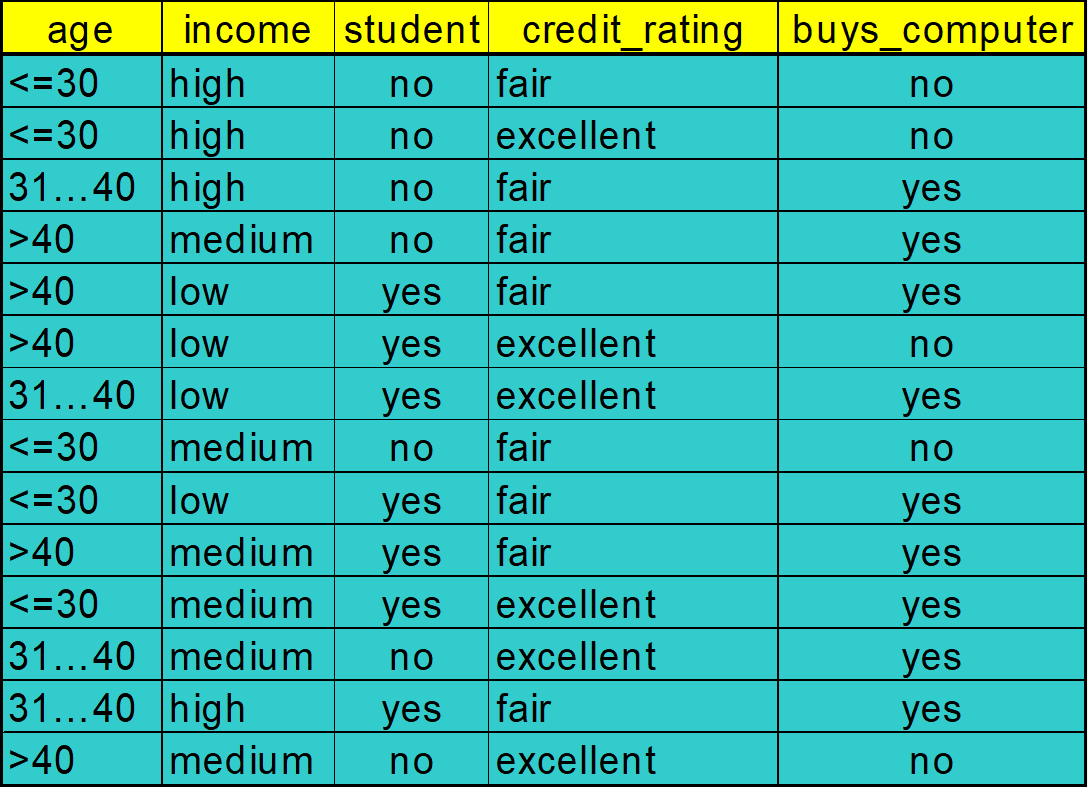
這是我們的資料集,現在我想要透過這個資料集來進行分類,分類的目標是甚麼呢,我想要決定出怎樣的人是有 ** 買電腦 (buys_computer)** 的。
那假設我選擇的分類條件如下:
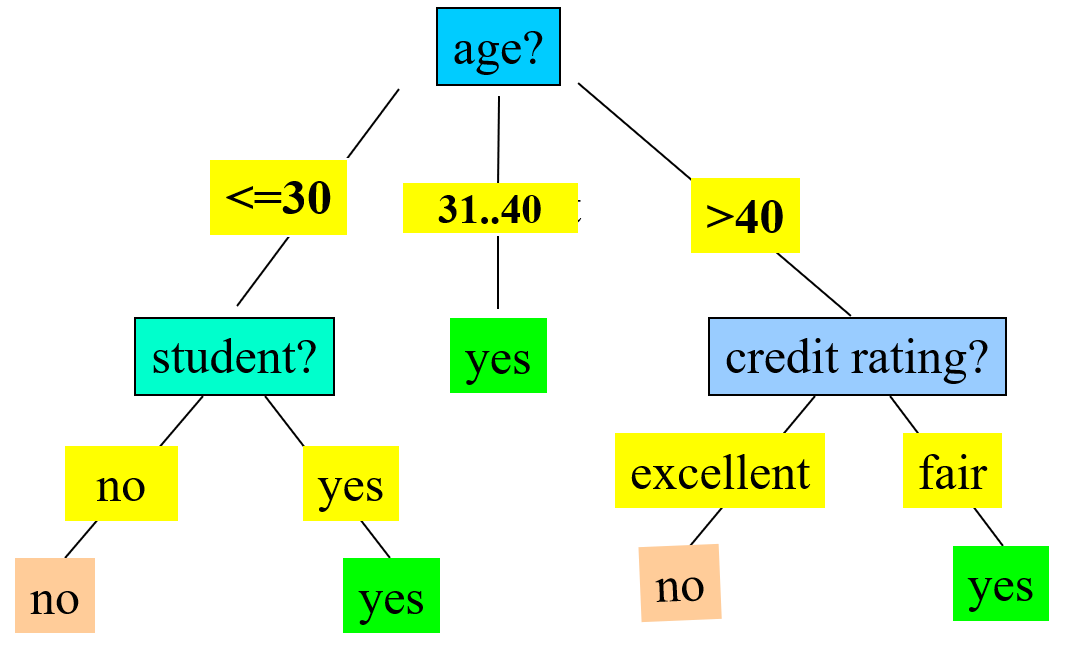
這是根據我選的分類條件而產生的其中一個決策樹的樣子。簡單來說決策樹就很像是一直 if then else then 的過程。可以看到根節點選擇 age,而根據資料集 age 有 **<=30、31…40、>40 這三個區間,而且 31…40** 這個區間就是符合我們的目標有買電腦的人,因此節點到這邊就可以停了。而其他兩個節點,因為還無法決定出哪些人有買電腦,哪些人沒買電腦,因此要根據其它的分類的條件繼續往下分。就會產生上面這種的決策樹的圖。
這時候問題就來了…,我要怎麼知道我要選哪些分類條件當節點啊?一個一個試太麻煩了吧,而且如果節點的條件沒選好,可想而知決策樹的樹狀會越來越長,導致要很後面才能決定出結果。而且根據我們的資料集在看以上的樹狀圖,可以知道並不是所有的分類條件都會用到。
所以這時候就要介紹決策樹的演算法,能夠自動地幫我們選擇最好的節點當作分類的條件。
決策樹演算法
首先可以知道決策樹的演算法的基底,可以說是一種貪婪演算法,然後是 top-down recursive divide-and-conquer 的方式去實現的。
也就是:
- 選擇所有的分類其中一個最好的分類,當作跟節點去分整個資料集
- 資料集會依據條件被拆成好幾個子資料集
- 每個子資料集再去選擇當下更好的分類,當作當下的節點去分子資料集
- 以上的動作遞迴去做,就會產生最理想的決策樹出來了。
要注意的是:停止分類的情形是當所有的資料都屬於某一種分類下,無法再將當前的資料進行其他的分類,那麼就代表說可以停止分類這個動作了。
以這個例子來看:
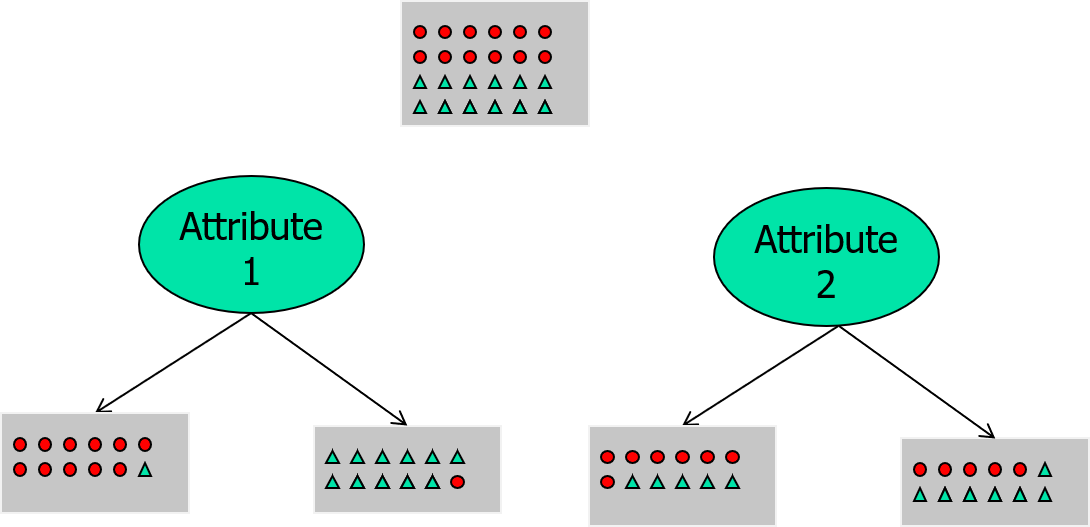
一個資料集,我們可以選擇這兩種屬性其中一種來進行分類,哪一種比較好呢?其中最重要的就是這個節點選下去之後,最好能夠把資料分類得一清二楚。因此我們可以知道 Attribute1 是比較好的,因為這個屬性可以將我們的資料集分類的比較 pure。
那用以上的這種想法,可以去計算以下兩種東西:
- Information Gain (資訊獲利)
- Gini Index (吉尼指數)
來一一介紹兩種的方式。
Information Gain
那事實上如何去計算 Information Gain 的實作演算法有 ID3、C4.5、C5.0… 等等。其中後者兩個是 ID3 的改進版本。基本上它們的原理就是去算出哪個分類屬性有較高的 Information Gain 就先選擇哪個分類屬性下去分,而這個計算需要先算出 entropy。
什麼是 entropy:
就是用來度量資訊量的東西,也就是假設有一個資料集很純淨,就像是沒辦法用甚麼其他屬性下去分類,以及有一個資料集較雜亂,可以用很多屬性下去分類,那我們可以說純淨的資料集,假設資料都一致,那 entropy = 0,反之雜亂的資料集如果各有一半不同,那 entropy = 1。
因此如果決策樹採用 Information Gain 的方式,要先算出每個節點分類的 entropy,在選擇節點較小的 entropy,因為越小的 entropy 代表 Information Gain 越高,因此就要選這個節點進行分類,才會將資料集分類到越來越 pure 的狀態。
entropy 的公式如下:
$$
Entropy = -p * \lg§ - q * \lg(q)
$$
p:成功的機率(或 true 的機率)
q:失敗的機率 (或 false 的機率)
直接來看例子:
以上面學生的資料集來看,決策樹的最終目標是要分類出有買電腦的人跟沒買電腦的人。
也就是 p = buys_computer (YES) 的機率 q = buys_computer (NO) 的機率
好,接下來用 python 的程式來做講解:
-
定義 entropy 的函式算法
1
2
3
4
5
6import numpy as np
def entropy(i, j):
if i == 0 or j == 0:
return 0
p = i / (i + j)
return - p*np.log2(p) - (1 - p)*np.log2((1 - p))這邊使用 numpy 的套件來幫助計算,特別注意當 i 或 j=0,則 entropy=0,為什麼呢?
因為這邊 i、j 的意思各自代表有買電腦的人數、沒買電腦的人數,只要任何一個為 0,那麼就代表目前這個 entropy 是很 pure 的,也就是說已經沒有分類的意義了,代表說這個分類屬性一分類下去有無買電腦的區分就很明顯。
-
計算當前資料集的 entropy
目前的資料集因為還沒分類,必須知道當前資料集它的 entropy,也就是雜亂程度:
1
2
3ori_entropy = entropy(9, 5)
ori_entropy
# 0.9402859586706309 -
分類屬性選擇 age
計算如果一開始的分類選擇 age,那麼選擇之後,我們的資料集的 entropy 會呈現怎樣呢?
這邊特別注意 age 有三種條件,分別是 <=30、31…40、>40,因此需要個別計算在 age 這三個不同區間下有無買電腦的 entropy,並進行加總,最後在用當前資料集的 entropy 去相減,就能算出選擇 age 這個屬性之後所產生的 information gain。
1
2
3
4
5
6age_entropy = 5/14 * entropy(2, 3) + 4/14 * entropy(4, 0) + 5/14 * entropy(3, 2)
print(f'age_entropy: {age_entropy}')
age_gain = ori_entropy - age_entropy
print(f'age_gain: {age_gain}')
# age_entropy: 0.6935361388961918
# age_gain: 0.2467498197744391 -
分類屬性選擇 income
這邊就按照 age 的類似步驟,就不多加講解
1
2
3
4
5
6
7income_entropy = 4/14 * entropy(2, 2) + 6/14 * entropy(4, 2) + 4/14 * entropy(3, 1)
income_entropy
print(f'income_entropy: {income_entropy}')
income_gain = ori_entropy - income_entropy
print(f'income_gain: {income_gain}')
# income_entropy: 0.9110633930116763
# income_gain: 0.029222565658954647 -
分類屬性選 student
這邊就按照 age 的類似步驟,就不多加講解
1
2
3
4
5
6
7
8student_entropy = 7/14 * entropy(6, 1) + 7/14 * entropy(3, 4)
student_entropy
print(f'student_entropy: {student_entropy}')
student_gain = ori_entropy - student_entropy
student_gain
print(f'student_entropy: {student_entropy}')
# student_entropy: 0.7884504573082896
# student_gain: 0.15183550136234136 -
分類屬性選 credit_rating
這邊就按照 age 的類似步驟,就不多加講解
1
2
3
4
5
6
7
8credit_rating_entropy = 6/14 * entropy(3, 3) + 8/14 * entropy(6, 2)
credit_rating_entropy
print(f'credit_rating_entropy: {credit_rating_entropy}')
credit_rating_gain = ori_entropy - credit_rating_entropy
credit_rating_gain
print(f'credit_rating_entropy: {credit_rating_entropy}')
# credit_rating_entropy: 0.8921589282623617
# credit_rating_gain: 0.04812703040826927 -
最後我們排序就可以知道:
1
2print(age_gain > student_gain > credit_rating_gain > income_gain)
# Trueage_gain 是最高的,也就是一開始的分類屬性應該從 age 開始!
之後的算法依此類推,用過濾之後的資料集繼續進行以上的步驟,直到可以把資料集完全分開的情況產生。基本上就會像上面那張決策樹的圖一樣,是最理想的情況。
Gini Index
GINI Index 的實作演算法是 CART tree。CART 是 Classification And Regression Tree 的縮寫,因此兼具分類與迴歸兩種功能。
要注意的是 Gini Index 與 Information Gain 兩者有一個最大的差別:INFORMATION GAIN 一次可產生多個不同節點,而 Gini Index 一次僅能產生兩個,即 True 或 False 的 Binary 的二元分類樹。
公式如下:
$$
Gini Index = 1 - pp - qq
$$
p:成功的機率(或 true 的機率)
q:失敗的機率 (或 false 的機率)
直接用上面的例子來計算:
-
定義 gini 的函式
1
2
3
4
5def gini(i, j):
p = 0
if i != 0 or j != 0:
p = i / (i + j)
return 1 - p*p - (1-p)*(1-p)特別注意如果 i、j 都 = 0 的話,那就代表 p=0,避免程式錯誤因此這邊作條件的檢查。
-
選擇 income 屬性
總共可以分為三種 subset
- {low, medium}、{high}
- {low, high}、{medium}
- {medium, high}、{low}
1
2
3
4
5
6
7
8
9gini_income_1 = 10/14 * gini(7, 3) + 4/14 * gini(2, 2)
gini_income_2 = 8/14 * gini(5, 3) + 6/14 * gini(4, 2)
gini_income_3 = 10/14 * gini(6, 4) + 4/14 * gini(3, 1)
print('gini_income_1:', gini_income_1)
print('gini_income_2:', gini_income_2)
print('gini_income_3:', gini_income_3)
# gini_income_1: 0.44285714285714284
# gini_income_2: 0.4583333333333333
# gini_income_3: 0.45從以上三種計算選出最小的 gini,才是最好的分割結果,後面其他屬性計算以此類推,所以後面就不多加講解了
-
選擇 age 屬性
總共可以分為三種 subset
- {youth, middle}、{senior}
- {youth, senior}、{middle}
- {middle, senior}、{youth}
1
2
3
4
5
6
7
8
9gini_age_1 = 9/14 * gini(6, 3) + 5/14 * gini(3, 2)
gini_age_2 = 10/14 * gini(5, 5) + 4/14 * gini(4, 0)
gini_age_3 = 9/14 * gini(7, 2) + 5/14 * gini(2, 3)
print('gini_age_1:', gini_age_1)
print('gini_age_2:', gini_age_2)
print('gini_age_3:', gini_age_3)
# gini_age_1: 0.45714285714285713
# gini_age_2: 0.35714285714285715
# gini_age_3: 0.3936507936507937 -
選擇 student 屬性
總共可以分為一種 subset
- {no}, {yes}
1
2
3gini_student_1 = 7/14 * gini(3, 4) + 7/14 * gini(6, 1)
print('gini_student_1:', gini_student_1)
# gini_student_1: 0.3673469387755103 -
選擇 credit_rating 屬性
總共可以分為一種 subset
- {fair}, {excellent}
1
2
3gini_credit_1 = 8/14 * gini(6, 2) + 6/14 * gini(3, 3)
print('gini_credit_1:', gini_credit_1)
# gini_credit_1: 0.42857142857142855 -
從以上屬性中算出來的 gini,選出最小的
1
2print(gini_age_2 < gini_student_1 < gini_credit_1 < gini_income_1)
# true因此,可以知道選 age 這個分類屬性所獲得的 gini index 最小,因此第一個應該要選擇的條件就是 age。 當 age 這個作為條件的母節點依序去往剩下的資料集遞迴以上的步驟,就可以出來理想中最好的決策樹的圖。
總結
這篇主要講解決策樹的主要兩種思路 ----- Information Gain、Gini Index,兩者演算法皆有其適用的地方及優劣之處,之後有機會再補充該注意的知識點… 累爆~~~
以上的程式碼我寫成 jupyter notebook 的檔案,方便觀看,可提供下載:程式碼
最後最後!請聽我一言!
如果你還沒有註冊 Like Coin,你可以在文章最下方看到 Like 的按鈕,點下去後即可申請帳號,透過申請帳號後可以幫我的文章按下 Like,而 Like 最多可以點五次,而你不用付出任何一塊錢,就能給我寫這篇文章的最大的回饋!