Designing Data-Intensive Applications 書本 - Reliable,Scalable and Maintainable Applications 筆記

今天來介紹最近公司讀書會要一起共讀的書本:Designing Data-Intensive Applications,一樣,會把每一章所做的筆記寫成 blog 出來。今天的重點主要是介紹何謂 Reliable,Scalable and Maintainable,這三個元素應該是設計每個系統都需要考量到的三件事情,一起來看看吧。
由於現在的科技日新月異,CPU Power 不足的問題,通常很少會是現在系統遇到的瓶頸,取而代之應該是大量的資料所帶來的問題,因為通常系統都會有以下的特點:
- 需要將資料存在 database,並且供系統可存取
- 需要將常用到的 hotdata,所謂 hotdata 指的是常常會被系統所使用的,也有可能是這些資料需要花費大量的時間去做計算或是存取,所以通常這類型的 hotdata,我們會需要存在 cache 上,來加速讀取的速度。
- 讓 user 可以透過 keyword 來搜尋或是 filter 資料。
- 需要讓多個 process 進行傳遞 message,也許是 concurrent 運行,或是需要用到 stream processing 的技巧,也有可有處在 microservice 的架構內,需要大量的傳輸資料的情境。
- 需要定期的處理大量累積的資料,使用 batch processing 的方式來處理,通常可能會是 cronjob 的形式。
那麼,我們這些 developer 現在市面上又有很多 storage engine 可以讓我們選擇存放資料,但是每一個 storage engine 的運用場景又不同,各自建立 index 或是 cache 也會有所不同,所以在設計系統的時候,我們需要有能力去比較這些 tool 的差別,選擇最符合我們系統的需求。
Thinking About Data Systems
如果現在系統需要 message queue,那麼市面上的工具,可以使用 redis,rabbitmq,kafka,每一個工具所帶來的 message queue 的效果皆不一樣,加上在設計系統的時候有時也會同時用到很多 tool 來滿足多方面的 data processing and storage needs
比如說,來看個例子,如果系統上需要 application caching layer,以及一個 full-text search server,透過這兩個 server 來與我們的主資料庫進行分離要怎麼設計整個架構圖:
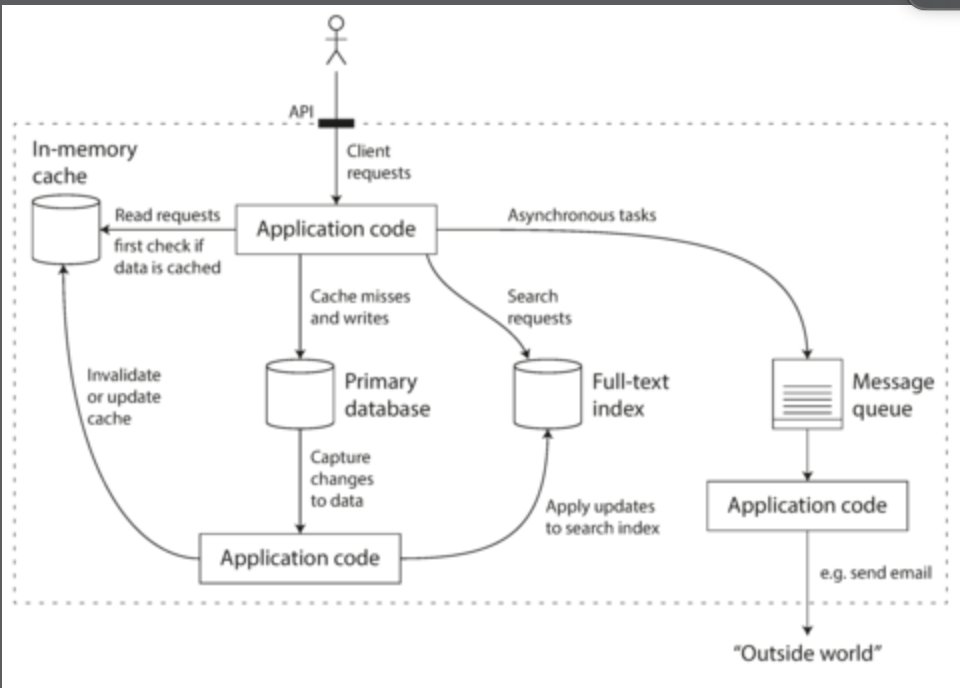
這個架構設計個人認為是很常見的設計,application code 要負責 cache 與 primary database 資料同步的問題,如果是需要全文搜尋的功能,則通常會開一個 elasticsearch server 來做,而且通常也會加入 message queue 來處理 loading 比較重或者非同步的 task,也適合成為一個解耦合的角色,與核心的商業邏輯做分開。
從這個架構圖也可以看出來,我們除了要設計 Application layer,更需要設計因為 data 所帶來的整個 system 架構設計,所以也要當個 data system desinger。
Questions
那麼,如果要設計以上的架構,我們需要有能力 answer 以下的問題:
- How do you ensure that the data remains correct and complete, even when things go wrong internally?
- How do you provide consistently good performance to clients, even when parts of your system are degraded?
- How do you scale to handle an increase in load?
- What does a good API for the service look like?
而要回答以上的問題,要知道很多 factors 會影響設計整個系統的方向:
- including the skills and experience of the people involved
- legacy system dependencies
- the timescale for delivery
- your organization’s tolerance of different kinds of risk
- regulatory constraints
根據不同的因素影響,就會影響我們設計出來的系統走向。
那麼,在想出這些 factor 的答案前的前置知識在於,我們必須要先了解何謂 Reliability,Scalability,Maintainability。
Reliability
The system should continue to work correctly (performing the correct function at the desired level of performance) even in the face of adversity (hardware or software faults, and even human error)
根據這句話整理了以下四個特點:
- The application performs the function that the user expected.
- It can tolerate the user making mistakes or using the software in unexpected ways.
- Its performance is good enough for the required use case, under the expected load and data volume.
- The system prevents any unauthorized access and abuse.
那麼重點在於即使系統遇到了一些 faults,整個系統也應該能夠持續運作,也就是說我們必須設計一些容錯的操作,當然不是每個錯誤都是可以被容錯的,我們要著重於哪些 faults 是可以避免的。
這邊提一下 fault 與 failure 的差別:
- A fault is usually defined as one component of the system deviating from its spec
- a failure is when the system as a whole stops providing the required service to the user.
如果要測試 fault 發生時系統有正確的容錯處理,可以使用 netflix 開源的 Chaos Monkey 來測試,常常 fault 處理不好,很有可能我們的錯誤處理設計不當所導致的。
那麼接著來介紹硬體與軟體個自會遇到的 faults 類型。
Hardware Faults
- Hard disks crash
- RAM becomes faulty
- the power grid has a blackout,
- someone unplugs the wrong network cable
那麼這邊介紹一下硬體發生的錯誤,會使用一個公式:MTTF
產品故障前平均時間:指一個系統工作直到發生失效的期望時間,這表示此系統僅能失效一次且不可修復,對於不可修復的系統而言,MTTF 為系統可靠度中極為重要的指標。
根據研究指出 Hard disks are reported as having a mean time to failure (MTTF) of about 10 to 50 years,那麼根據這個公式可以知道,on a storage cluster with 10,000 disks, we should expect on average one disk to die per day。
而硬體的容錯方案,通常就是加入多個備用硬體,當有出現問題的時候,可以隨時做更換,保持 Reliability。
那因為是儲存資料,所以最重要的是如何保護我們的硬碟,如果是儲存資料的硬碟最好採用 RAID 機制來做,這邊我特別記錄一下何謂 RAID
RAID
根據維基資料:容錯式磁碟陣列(RAID, Redundant Array of Independent Disks),舊稱容錯式廉價磁碟陣列(Redundant Array of Inexpensive Disks),簡稱磁碟陣列。利用虛擬化儲存技術把多個硬碟組合起來,成為一個或多個硬碟陣列組,目的為提升效能或資料冗餘,或是兩者同時提升。
在運作中,取決於 RAID 層級不同,資料會以多種模式分散於各個硬碟,RAID 層級的命名會以 RAID 開頭並帶數字,例如:RAID 0、RAID 1、RAID 5、RAID 6、RAID 7、RAID 01、RAID 10、RAID 50、RAID 60。每種等級都有其理論上的優缺點,不同的等級在兩個目標間取得平衡,分別是增加資料可靠性以及增加記憶體(群)讀寫效能。
簡單來說,RAID 把多個硬碟組合成為一個邏輯硬碟,因此,作業系統只會把它當作一個實體硬碟。RAID 常被用在伺服器電腦上,並且常使用完全相同的硬碟作為組合。由於硬碟價格的不斷下降與 RAID 功能更加有效地與主機板整合,它也成為普通使用者的一個選擇,特別是需要大容量儲存空間的工作,如:視訊與音訊製作。
RAID (磁碟陣列) 是為了提供更大的效能、可靠性、儲存容量與更低的成本,而由多部磁碟機 (稱為陣列) 組成的磁碟系統。容錯陣列是以六個 RAID 層級來分類:由 0 到 5。每一個層級使用不同的演算法來實作容錯功能。
這邊也上了 RAID 各層級的比較,n 代表硬碟總數:
| RAID 等級 | 最少硬碟 | 最大容錯 | 可用容量 | 讀取效能 | 寫入效能 | 安全性 | 目的 | 應用產業 |
|---|---|---|---|---|---|---|---|---|
| 0. | 2 | 0. | n | n | n | 一個硬碟異常,全部硬碟都會異常 | 追求最大容量、速度 | 影片剪接快取用途 |
| 1 | 2 | n-1 | 1 | n | 1 | 最高,一個硬碟正常即可 | 追求最大安全性 | 個人、企業備份 |
| 5 | 3 | 1 | n-1 | n-1 | n-1 | 高 | 追求最大容量、最小預算 | 個人、企業備份 |
| 6 | 4 | 2 | n-2 | n-2 | n-2 | 安全性 較 RAID 5 高 | 同 RAID 5,但較安全 | 個人、企業備份 |
| 10 | 4 | n/2 | n/2 | n | n/2 | 安全性高 | 綜合 RAID 0/1 優點,理論速度較快 | 大型資料庫、伺服器 |
這邊也多加了 backend 版主的看法:https://www.facebook.com/groups/616369245163622/posts/1333064660160740/
整理一下:
-
RAID 10 只能單保護單一硬碟的物理性故障。
而大家都知道:硬碟們永遠是結拜的好兄弟,不求同年同月同日生,但求同年同月同日死……
大家都知道:RAID 10 的硬碟,物理上是差不多都放到一起的。所以會一起過熱,一起被共震壞掉,一起遇電源問題……(以上都是機房 HDD 主死因)
大家也知道:RAID 10 的硬碟們,一般都是同一時間,在同一地方買的,遇上同一批有問題的零件可能性也很大……
-
Master-Slave replication 只能保護物理故鄉。
但是 Replication 是保護不了 Application 有 bug 把資料誤刪的。
另外,replication 也保護不了爆肝後的工程師錯手把 database drop 掉。
-
AWS / GCP 的 disk snapshot 不是 100% 安全的。
大家都有聽過 cracker 動用社交工程拿到了工程師的 AWS / GCP 的 root account password。
然後把伺服器連同 backup 資料全刪光光再來威脅贖金吧。
只有完全離線了的資料才是真正安全的。
(呃,p 什麼 hub 的別用 window 來看,是常識吧)
-
所謂黑洞式 backup,就是「我覺得這個 backup 成功了」
在磁帶 backup 時代,一堆人為了省錢,明明超了使用期限的磁帶還是不停重用。結果要拿出來做 recovery 時才發現這磁帶是一個黑洞,資料有進沒出的……
看清你離線 backup 的 media(磁帶,bluray disc)的壽命。同時,偶然便把 backup 拿一份出來看看是否真的能做 recovery,才能保證你的資料真的是安全的。
Software Faults
那麼其實硬體大規模壞掉的情況並不常見,許多時候系統會遇到的還是軟體的錯誤居多,比如說:
- A software bug that causes every instance of an application server to crash when given a particular bad input. For example, consider the leap second on June 30, 2012, that caused many applications to hang simultaneously due to a bug in the Linux kernel.
- A runaway process that uses up some shared resource—CPU time, memory, disk space, or network bandwidth.
- A service that the system depends on that slows down, becomes unresponsive, or starts returning corrupted responses.
- Cascading failures, where a small fault in one component triggers a fault in another component, which in turn triggers further faults.
因此,我們通常需要利用 unit test,process isolation,allowing processes to crash and restart,也要加入在生產環境上加入一些監測系統,做緊急處理。
Human Errors
人為錯誤,當然最有可能就是我們這些工程師沒做好軟體開發囉。
有幾個點可以讓我們這些工程師去注意,當我們在撰寫程式的時候:
-
Design systems in a way that minimizes opportunities for error.
例如:做好抽象化設計,AP 的權限控管好,什麼該開放,什麼不該開放。
-
Decouple the places where people make the most mistakes from the places where they can cause failures.
provide fully featured non-production sandbox environments where people can explore and experiment safely, using real data, without affecting real users.
這個書上舉的例子我不是很理解,書上的說明是提供一個 non-production 的環境讓 user 可以使用真實資料,但是不會影響實際的 user。我可以理解通常上線前應該會有所謂的測試環境,這樣可以先用接近真實的資料來做測試。
-
Test thoroughly at all levels, from unit tests to whole-system integration tests and manual tests.
對每一個 layer 都要做好 test,可以有效降低可能會出現的錯誤。那現在通常比較多自動化測試的工具或者 pattern 可以使用,不過我覺得整合測試這方面,可能還是要偏向人工測試居多。
-
Allow quick and easy recovery from human errors, to minimize the impact in the case of a failure.
當遇到錯誤,能夠迅速地縮小這個錯誤的範圍,個人覺得,最快的速度會是 rollback 到上一個 version,至少先把錯誤的版本先降下來,或是當新功能上線時,先對一部份的 user 開放,避免有問題的話影響全部的 user。
不過以上的說法比較偏向遇到的錯誤是沒有拿到錯誤的資料,如果有錯誤的資料那就要想辦法能夠計算出正確的資料,或是乾脆還原成之前的舊資料。
-
Set up detailed and clear monitoring, such as performance metrics and error rates.
一樣,需要設定監控的機制,不過是 performance 或是 error rate,一但不對勁都應該設定自動化通知,讓我們這些工程師可以快速的處理。這樣的做法就稱為 telemetry。
-
Implement good management practices and trainin
團隊內應該要有共用的規範,例如說大家可能會規定使用相同的 lib 或是 coding style,避免每一個人的 code 長得不太一樣,此外我是覺得每一個專案,都應該至少有所謂的架構圖,以及 API Document,這樣才可以幫助後來的新人可以快速上手,也可以讓老鳥能夠快速回憶當年做的專案。
How Important is Reliability?
- 如果生產環境有 bug,就有可能會降低生產力而讓收益跟名譽收損。
- 當然很多時候對於新創而言,重點是在於快速推出新產品,這時候為了開發快速就可能會犧牲 Reliability,但是當系統一但變大的時候,最終還是要來解決根本問題的。
Scalability
Scalability is the term we use to describe a system’s ability to cope with increased load.
要解決 Scalability 的問題,要考慮以下的問題
- If the system grows in a particular way, what are our options for coping with the growth ?
- How can we add computing resources to handle the additional load ?
Describe Load
系統上的附載度是我們了解 Scalability 的關鍵,通常系統上會有以下的計算方式:
- it may be requests per second to a web server
- the ratio of reads to writes in a database
- the number of simultaneously active users in a chat room
- the hit rate on a cache
那麼有可能我們系統需要在乎的是 average case 為何,也有可能要對付極端情況的 case。
我們來看一下 Twitter case:
-
Post tweet
每一個使用者可以發布新的 message 給他們的追蹤者,根據統計 4.6k requests/sec on average, over 12k requests/sec at peak。
-
Home timeline
每一個使用者可以看他們追蹤者的 tweets,根據統計 300k requests/sec
根據以上的統計,字面上雖然處理 12k requests/sec 好像很容易,但是要知道,根據這個 Tweet 的系統,每一個 user 可以追蹤很多人,每一個人也可以被很多人追蹤,來看關聯關係會長怎樣:
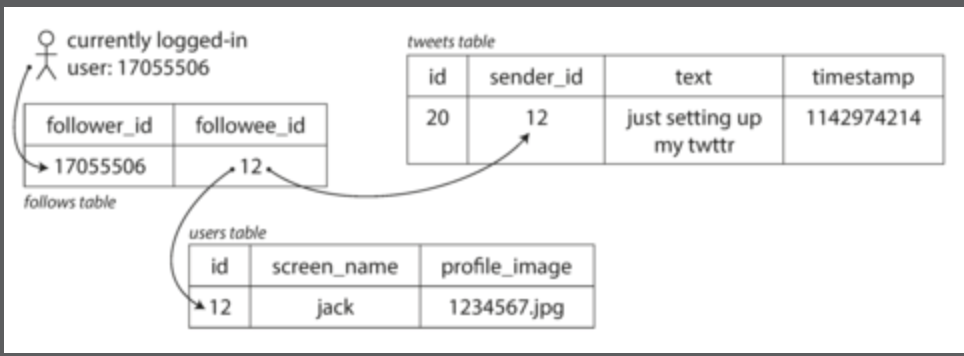
問題來了,當發出一則 tweet,會有兩種做法:
-
Posting a tweet simply inserts the new tweet into a global collection of tweets.
當有 user 存取它們的 home timeline,需要看到所有他追蹤的人的 tweet,並且按照時間排序,那麼我們可能會寫出這樣的 query:
1
2
3
4
5SELECT tweets.*, users.*
FROM tweets
JOIN users ON tweets.sender_id = users.id
JOIN follows ON follows.followee_id = users.id
WHERE follows.follower_id = current_user然而這樣的做法一定會拖垮資料庫的性能,所以第二種方法改良是加上 cache。
-
Maintain a cache for each user’s home timeline—like a mailbox of tweets for each recipient user
當有 user 發布 tweet,找出所有追蹤該 user 的所有 follower 並且將新 tweet 塞入每一個追蹤者的 home timeline caches,這樣讀取 timeline caches 的成本降低,速度也會大幅度的提升:
![figure1-3]()

最原始的 tweet 系統採用第一種方式,現在的話則是採用第二種改良的方式,然而這樣的問題來了,平均而言,每則 tweet 可能會有 75 個 followers,所以 4.6k tweets per second become 345k writes per second to the home timeline caches.
Tweet 系統希望可以在五秒內就可以更新完 timeline 部分,這就是 Scalability 遇到的挑戰。對於 Tweet 系統而言,the distribution of followers per user (maybe weighted by how often those users tweet) is a key load parameter for discussing scalability, since it determines the fan-out load.
最後 Tweet 聽說採用混合式的方式,多數普通的 user 維持方法二,因為普通的 user 的追蹤數是少量的,不太影響效能,對於明星的 user,則會用特地個別的去更新,並且分開存取,來更新 timeline ,這邊書本沒有寫得很清楚,也許是獨立開一個 cache server 或是 database sharding 的方式去個別存取。
Describe Performance
當了解怎麼去描述系統的負載度之後,接著來講講會如何影響 performance 這件事情:
-
When you increase a load parameter and keep the system resources (CPU memory, network bandwidth, etc.) unchanged, how is the performance of your system affected?
-
When you increase a load parameter, how much do you need to increase the resources if you want to keep performance unchanged?
-
throughput—the number of records we can process per second, or the total time it takes to run a job on a dataset of a certain size.
In online systems, what’s usually more important is the service’s response time—that is, the time between a client sending a request and receiving a response.
這邊紀錄一下 Latency 與 Response time 的差別:
Latency and response time are often used synonymously, but they are not the same. The response time is what the client sees: besides the actual time to process the request (the service time), it includes network delays and queueing delays.
Latency is the duration that a request is waiting to be handled—during which it is latent, awaiting service.
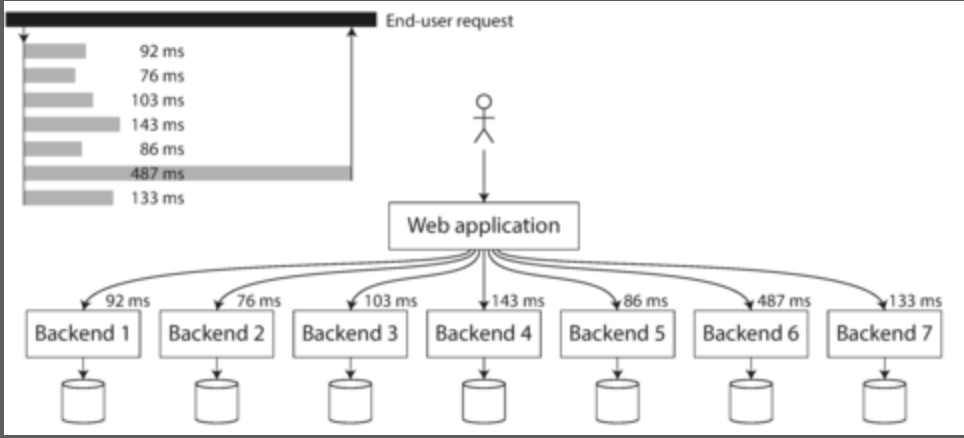
來看一下這張圖:

每一個灰色的柱狀代表每一個 request,每一個柱狀的高度代表 request 所花費的 response time,這邊也列出平均跟中位數與 95th and 99th 的分布為何。
通常每一個 request 所花費的時間不會是一樣的,很有可能會因為:
- the loss of a network packet and TCP retransmission
- a garbage collection pause
- a page fault forcing a read from disk
- mechanical vibrations in the server rack
而造成不同的回應時間。
根據以上的圖,我們可以得到以下幾件事情:
-
平均數通常這個不會是一個很好的指標,因為沒辦法直接的告訴我們多少的 user 經歷 delay 這件事情。所以通常我們會看 percentiles 來了解,例如我們將所有 response time 從快排到慢,接著看一下中位數,如果中位數是 200 ms 那麼代表有一半的 request 高於 200 ms 也有一半的 request 低於 200 ms
因此我們也可以知道有多少的 user 實際上等超過中位數的時間。
-
如果要看極端的情況,也可以看 95th 或是 99th,越高的話就代表是 tail latencies,極端的情況可以知道是會大幅度的影響使用者的體驗的。
這邊書本提出了 Amazon 的例子:
Amazon describes response time requirements for internal services in terms of the 99.9th percentile, even though it only affects 1 in 1,000 requests.
This is because the customers with the slowest requests are often those who have the most data on their accounts because they have made many purchases—that is, they’re the most valuable customers.
It’s important to keep those customers happy by ensuring the website is fast for them:
Amazon has also observed that a 100 ms increase in response time reduces sales by 1%, and others report that a 1-second slowdown reduces a customer satisfaction metric by 16%
所以可以知道使用者體驗是可能會影響生產的收益的。
但是要解決極端情況的 percentiles 有時候沒有那麼簡單,因為有可能是因為 random events outside of your control。
SLO V.S. SLA
這邊書本有提到這兩個名詞,我特地查了下,後來覺得 Google 這篇文章寫得不錯:https://cloud.google.com/blog/products/devops-sre/sre-fundamentals-slis-slas-and-slos
而文章內的圖就跟我們上面的例子一樣,因此本書的作者意思就是說這樣圖通常也會拿來制定 SLO 與 SLA。
白話來解釋的話:
- SLO 指定了服務所提供功能的一種期望狀態。
- SLA 是一個涉及 2 方的合約,雙方必須都要同意並遵守這個合約。當需要對外提供服務時,SLA 是非常重要的一個服務質量訊號,需要產品和法務部門的同時介入,因為需要獎勵跟懲罰。
HOL blocking
這邊書中也有提到 response time 極端的情況也是有可能遇到這個問題,什麼是 HOL blocking?
根據維基百科:隊頭阻塞(英語:Head-of-line blocking,縮寫:HOL blocking)在計算機網絡的範疇中是一種性能受限的現象。它的原因是一列的第一個數據包(隊頭)受阻而導致整列數據包受阻。例如它有可能在緩存式輸入的交換機中出現,有可能因為傳輸順序錯亂而出現,亦有可能在 HTTP 流水線中有多個請求的情況下出現。
關於 HOL blocking 的前後今生,其實要從 http 1.1 細講,這邊推薦這個作者的文章:https://github.com/rmarx/holblocking-blogpost
講解了從 HTTP 1.1 到 HTTP 3.0 為何有 HOL blocking 以及到了 HTTP 3.0 如何去解決。
多個 request 組成一個完整的 flow
這邊也有提到一個範例:
user 要體驗完整的服務,可能會需要很多 request 的結果,但是如果其中有一隻特別慢,那麼對於 user 而言他的體驗就是最慢的 request 那樣,就算你其他隻 request 很快,體驗也會變差,我個人認為除了後端拆分 API 可以更好,再來改善的點就是前端的使用者體驗要更好,因為 loading 是必備的,只是如何讓使用者體驗更好是一大課題。
Approaches for Coping with Load
提升 Salability 通常會用到 vertical scaling,轉移到配備更好的 machine,或是 horizontal scaling ,將許多 loading 分散給好幾台較小的 machine。
通常使用較多的且相同的配備會比用大量的小配備會來得簡單與省錢。
那麼市面上有許多工具都可以自動化的進行 vertical scaling 與 horizontal scaling,比如說 Kubernetes,人為操作的話可能會造成一些 operational surprises。
通常如果轉移 stateless services 給多個 machine 是比較容易的,如果是 stateful service 例如 database,就需要謹慎思考是否真的要採用 multi node,如果可以 single node 就能滿足當下情境是最好。
The architecture of systems that operate at large scale is usually highly specific to the application—there is no such thing as a generic, one-size-fits-all scalable architecture (informally known as magic scaling sauce).
舉例來說:
The problem may be the volume of reads, the volume of writes, the volume of data to store, the complexity of the data, the response time requirements, the access patterns, or (usually) some mixture of all of these plus many more issues.
- For example, a system that is designed to handle 100,000 requests per second, each 1 kB in size, looks very different from a system that is designed for 3 requests per minute, each 2 GB in size—even though the two systems have the same data throughput.
Maintainability
It is well known that the majority of the cost of software is not in its initial development, but in its ongoing maintenance
要維持 Maintainability 需要記得以下幾點:
- fixing bugs
- keeping its systems operational
- investigating failures
- adapting it to new platforms
- modifying it for new use cases
- repaying technical debt
- adding new features
當然拉,許多工程師相信都不喜歡 legacy systems,因此造就這種系統其 Maintainability 越來越低的原因,但是如果我們在一開始設計的時候就記住一些原則,就不會日後這麼痛苦了。
也就是:
-
Operability
Make it easy for operations teams to keep the system running smoothly.
-
Simplicity
Make it easy for new engineers to understand the system, by removing as much complexity as possible from the system. (Note this is not the same as simplicity of the user interface.)
-
Evolvability
Make it easy for engineers to make changes to the system in the future, adapting it for unanticipated use cases as requirements change. Also known as extensibility, modifiability, or plasticity.
Operability: Making Life Easy for Operations
Operations teams are vital to keeping a software system running smoothly. A good operations team typically is responsible for the following
這邊我覺得直接放英文就好,寫中文真的不太好翻譯 QQ
- Monitoring the health of the system and quickly restoring service if it goes into a bad state
- Tracking down the cause of problems, such as system failures or degraded performance
- Keeping software and platforms up to date, including security patches
- Keeping tabs on how different systems affect each other, so that a problematic change can be avoided before it causes damage
- Anticipating future problems and solving them before they occur (e.g., capacity planning)
- Establishing good practices and tools for deployment, configuration management, and more
- Performing complex maintenance tasks, such as moving an application from one platform to another
- Maintaining the security of the system as configuration changes are made
- Defining processes that make operations predictable and help keep the production environment stable
- Preserving the organization’s knowledge about the system, even as individual people come and go
Data systems can do various things to make routine tasks easy, including:
- Providing visibility into the runtime behavior and internals of the system, with good monitoring
- Providing good support for automation and integration with standard tools
- Avoiding dependency on individual machines (allowing machines to be taken down for maintenance while the system as a whole continues running uninterrupted)
- Providing good documentation and an easy-to-understand operational model (“If I do X, Y will happen”)
- Providing good default behavior, but also giving administrators the freedom to override defaults when needed
- Self-healing where appropriate, but also giving administrators manual control over the system state when needed
- Exhibiting predictable behavior, minimizing surprises
Simplicity: Managing Complexity
Small software projects can have delightfully simple and expressive code, but as projects get larger, they often become very complex and difficult to understand.
There are various possible symptoms of complexity:
- explosion of the state space
- tight coupling of modules
- tangled dependencies
- inconsistent naming and terminology
- hacks aimed at solving performance problems
- special casing to work around issues elsewhere
When complexity makes maintenance hard, budgets and schedules are often overrun. In complex software, there is also a greater risk of introducing bugs when making a change
- when the system is harder for developers to understand and reason about
- hidden assumptions
- unintended consequences
- unexpected interactions are more easily overlooked.
Making a system simpler does not necessarily mean reducing its
functionality; it can also mean removing accidental complexity.
One of the best tools we have for removing accidental complexity is
abstraction.
- A good abstraction can hide a great deal of implementation
detail behind a clean, simple-to-understand façade. - A good abstraction can also be used for a wide range of different applications.
- Not only is this reuse more efficient than reimplementing a similar thing multiple times, but it also leads to higher-quality software, as quality improvements in the abstracted component benefit all applications that use it.
- For example, high-level programming languages are abstractions that hide machine code, CPU registers, and syscalls.
- SQL is an abstraction that hides complex on-disk and in-memory data structures, concurrent requests from other clients, and inconsistencies after crashes.
Evolvability: Making Change Easy
It’s extremely unlikely that your system’s requirements will remain unchanged forever.
- you learn new facts
- previously unanticipated use cases emerge
- business priorities change
- users request new features
- new platforms replace old platforms
- legal or regulatory requirements change
- growth of the system forces architectural changes
In terms of organizational processes, Agile working patterns provide a framework for adapting to change.
The Agile community has also developed technical tools and patterns that are helpful when developing software in a frequently changing environment, such as test-driven development (TDD) and refactoring.
總結
這個章節主要是介紹當我們在設計系統時,要考慮三個元素:Reliability, Salability, Maintainability, 根據這些元素怎樣設計可以符合我們系統的情境,設計出來的系統也能更加的 strong。